前缀树
- 1. 前缀树的的介绍
- 2.前缀树的实现
- 2.1插入功能
- 2.2删除功能
- 2.3查找前缀和查找单词功能
- 2.4 哈希表版本
1. 前缀树的的介绍
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
2.前缀树的实现
如何实现一颗前缀树呢?这里有两种实现的方法,对应了不同的情况。
我们首先来定义一下前缀树的节点,我们让每一个根节点有两个值,一个为pass,一个为end,pass表示经过这个节点的次数,end表示走到叶子节点的次数(也就是这个单词出现的次数)。
我们先看看这棵树的结构。比如我们插入字符串{“aa”,“aaa”,“bba”,“ssba”},我们看看这颗树的结构。
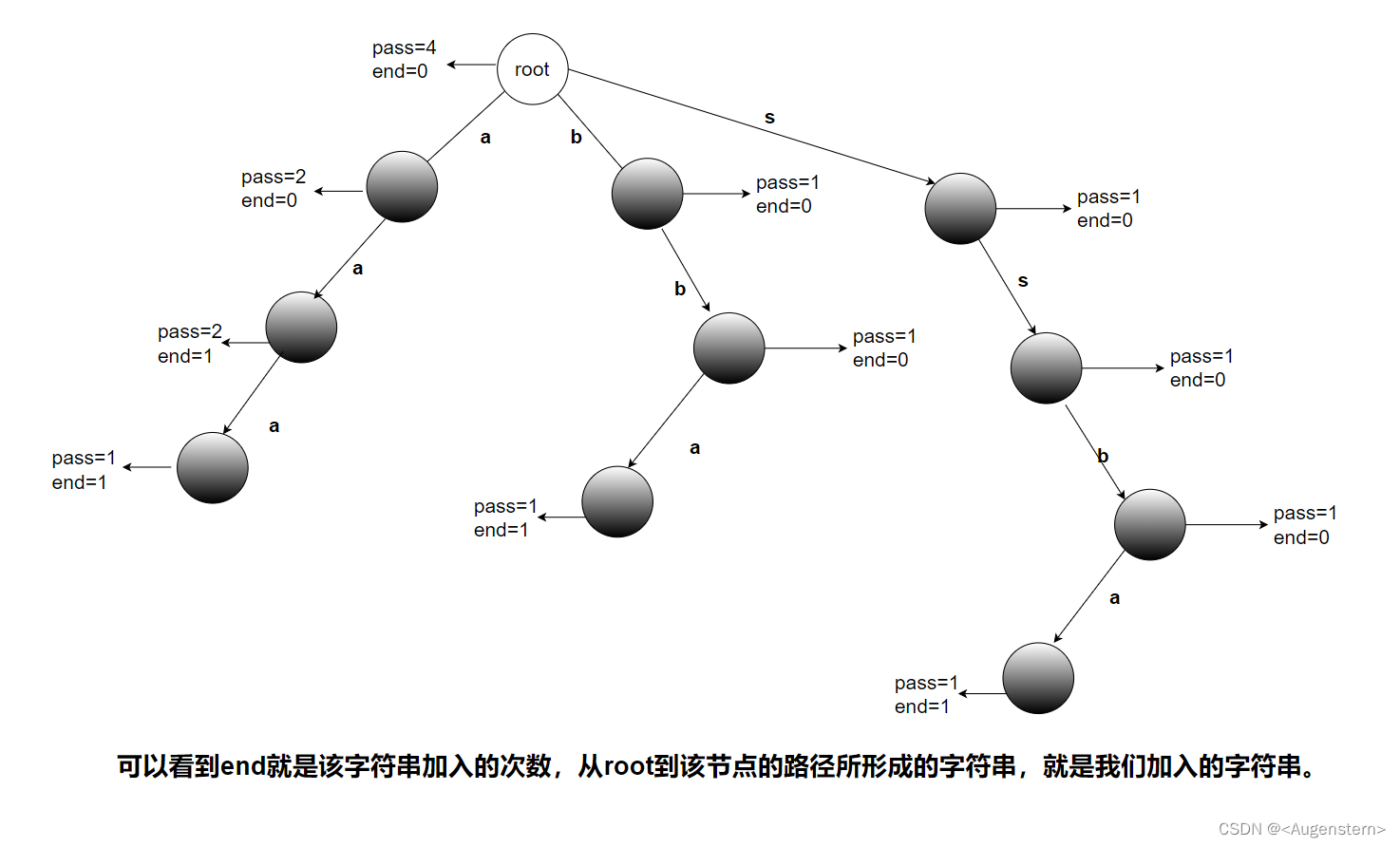
现在我们模拟这个过程来写代码
先来定义好节点
struct TreeNode // 创建结点
{TreeNode *next[26];int end;int pass;TreeNode() // 初始化结点{end = 0;path = 0;for(int i=0;i<26;i++)next[i]=NULL;}
};
下面我们实现树的部分,我们就储存一个头节点和所需要的接口
class Trie
{
private:TreeNode* root;
public:Trie(){root = new TreeNode;}void insert_Node(string word); // 插入void Delete_Node(string word); // 删除int search(string word); // 查找int prefixNumber(string word);//查找有多少以word作为前缀的单词
};
2.1插入功能
void Trie::insert_Node(string wrod)
{if (wrod == "") return;int idx = 0;TreeNode* node = root;root->pass++;for (int i = 0; i < wrod.size(); i++){idx = wrod[i] - 'a';if (node->next[idx]==nullptr)node->next[idx] = new TreeNode;node = node->next[idx];node->pass++;}node->end++;
}
2.2删除功能
//这个函数java的可以不用写,因为Java有JVM垃圾回收机制。
void Delete(TreeNode* node)
{if (node == NULL)return;for (int num = 0; num < 26; num++){if (node->next[num]){Delete(node->next[num]);}}delete(node);node=NULL;
}void Trie::Delete_Node(string word)
{if (!search(word))return;int index = 0;TreeNode* node = root;node->pass--;for (int i = 0; i < word.size(); i++){index = word[i] - 'a';if (--node->next[index]->pass == 0){// Java的直接将 node。next[index] = NULL 即可Delete(node->next[index]);node->next[index] = NULL;return;}node = node->next[index];}node->end--;
}2.3查找前缀和查找单词功能
int Trie::prefixNumber(string word)
{if (word == "") return 0;int idx = 0;TreeNode* node = root;for (int i = 0; i < word.size(); i++){idx = word[i] - 'a';if (node->next[idx] == nullptr) return 0;node = node->next[idx];}return node->pass;
}
int Trie::search(string word)
{if (word == "") return 0;int idx = 0;TreeNode* node = root;for(int i=0;i<word.size();i++){ idx = word[i] - 'a';if (node->next[idx] == nullptr) return 0;node = node->next[idx];}return node->end;
}
2.4 哈希表版本
如何单词不只有26个小写字母,我们该如何去实现呢,我们可以通过哈希表去进行映射来实现。
只需要以ASIII作为key,代码稍微改动一下就可以了。
#include <iostream>
#include <string>
#include <algorithm>
#include <unordered_map>
using namespace std;struct TreeNode
{int pass;int end;unordered_map<int, TreeNode*> next;TreeNode(){pass = 0;end = 0;}};class Trie
{
private:TreeNode* root;
public:Trie(){root = new TreeNode;}void insert_Node(string word); // 插入void Delete_Node(string word); // 删除int search(string word); // 查找int prefixNumber(string word);//查找有多少以word作为前缀的单词
};void Trie::insert_Node(string wrod)
{if (wrod == "") return;int idx = 0;TreeNode* node = root;root->pass++;for (int i = 0; i < wrod.size(); i++){idx = (int)wrod[i];if (!node->next.count(idx)){node->next[idx] = new TreeNode;}node = node->next[idx];node->pass++;}node->end++;
}int Trie::search(string word)
{if (word == "") return 0;int idx = 0;TreeNode* node = root;for(int i=0;i<word.size();i++){ idx = (int)word[i];if (!node->next.count(idx)) return 0;node = node->next[idx];}return node->end;
}
//这个函数java的可以不用写,因为Java有JVM垃圾回收机制。
void Delete(TreeNode* node)
{if (node == NULL)return;for (int num = 0; num < 26; num++){if (node->next[num]){Delete(node->next[num]);}}delete(node);node = NULL;
}void Trie::Delete_Node(string word)
{if (!search(word))return;int index = 0;TreeNode* node = root;node->pass--;for (int i = 0; i < word.size(); i++){index = (int)word[i];if (--node->next[index]->pass == 0){// Java的直接将 node。next[index] = NULL 即可Delete(node->next[index]);node->next[index] = NULL;return;}node = node->next[index];}node->end--;
}int Trie::prefixNumber(string word)
{if (word == "") return 0;int idx = 0;TreeNode* node = root;for (int i = 0; i < word.size(); i++){idx = (int)word[i];if (!node->next.count(idx)) return 0;node = node->next[idx];}return node->pass;
}int main()
{Trie tr;tr.insert_Node("aad");tr.insert_Node("jjafp");tr.insert_Node("jjdafp");tr.insert_Node("jjdafp");tr.insert_Node("jjafp");tr.insert_Node("jjdap");cout << tr.search("jjdafp") << endl;cout << tr.prefixNumber("j") << endl;return 0;
}