文章目录
- 数据类型
- 字符串
- 实现
- 使用场景
- List 列表
- 实现
- 使用场景
- Hash 哈希
- 实现
- 使用场景
- Set 集合
- 实现
- 使用场景
- ZSet 有序集合
- 实现
- 使用场景
- BitMap
- 实现
- 使用场景
- Stream
- 使用场景
- pubsub为什么不能作为消息队列
- 数据结构
- 机制
- SDS 简单动态字符串
- 压缩列表
- 哈希表
- 整数集合
- 跳表
- quicklist
- listpack
- 持久化
- AOF (Append only file)
- RDB (Redis Database)
- 数据恢复
- 过期和淘汰
- 过期删除策略
- 内存淘汰策略
- 主从复制
- 哨兵机制
- 哨兵集群的组成
- 切片集群
- 缓存
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 面试题
- 缓存和数据库一致性
- redis是单线程吗
- redis集群脑裂以及解决办法
- 从库如何处理过期key
- 如何只缓存热点数据
- 如何处理大key
- redis支持事务吗
- redis分布式锁
- set nx
- redis在集群模式下如何实现可靠的分布式锁
数据类型
字符串
实现
使用SDS(简单动态字符串),SDS不仅可以保存字符串还可以保存二进制数据,获取长度的时间复杂度是O(1),SDS的API是安全的,比如拼接字符串不会造成缓冲区溢出,总的来说就是对数组封装,提供一系列方便操作的API。
字符串对象有三种编码:int、raw、embstr
-
整数:ptr从void*转换为long
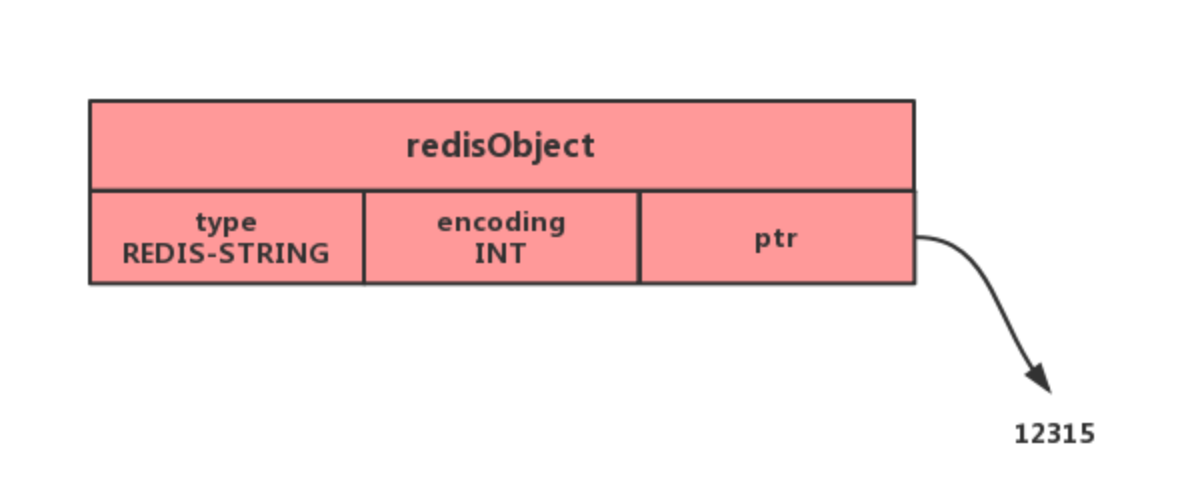
-
短字符串(至于多短,每个redis版本不一样):分配一块连续空间保存redisObject和SDS

-
长字符串:分别为redisObject和SDS分配两个内存,redisObject.ptr指向SDS
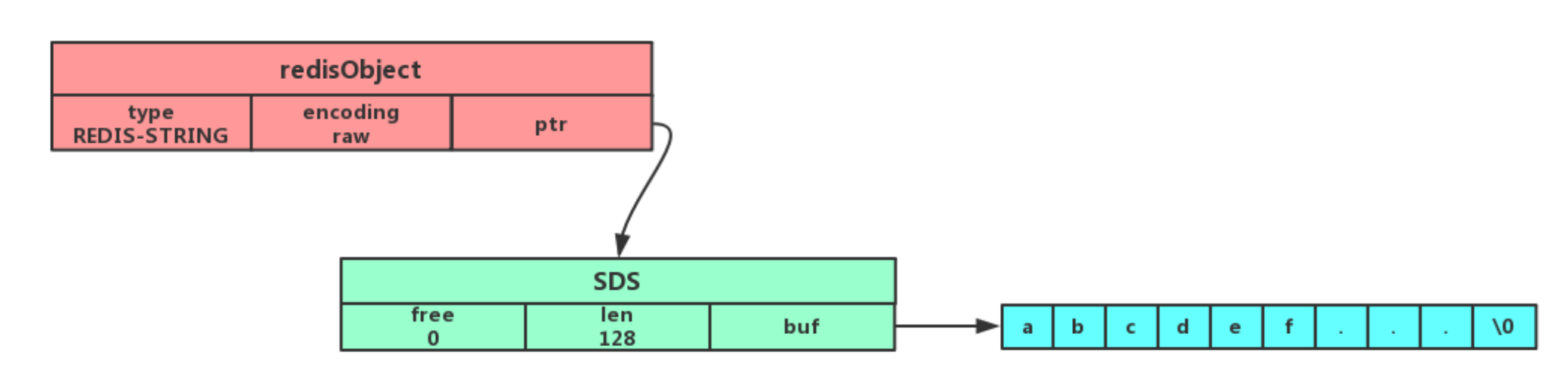
embstr如果要修改大小的话,只能重新分配空间。因此embstr实际上是只读的,当要修改embstr的长度,redis会先将其转换为raw再进行修改。
使用场景
缓存对象、常规计数(INCR)、分布式锁(SET-NX)、共享Session
List 列表
List在使用上就是一个Deque双端队列,存字符串
实现
- redis3.2之前:小列表使用压缩列表实现,大列表使用双向链表实现
- redis3.2之后:使用quicklist实现
使用场景
消息队列:
- 保序:LPUSH+RPOP,但是RPOP需要轮询,浪费CPU性能,因此还提供了BRPOP阻塞式读取
- 处理重复:每条消息设置一个全局唯一ID,利用ID判断是否已经消费,List不会为消息生成ID,需要用户自己添加
- 保证可靠:BRPOPLPUSH,读取的同时将消息插入另一个List作为留存,如果用户处理消息时失败,下次从留存List重新读取
作为消息队列的缺点:
- 不支持消费者组
Hash 哈希
适合存储对象
实现
- redis7.0之前:小Hash使用压缩列表,大Hash使用哈希表
- redis7.0之后:小Hash使用listpack,大Hash使用哈希表
使用场景
缓存对象:一般可以用String+序列化存储对象,并将变化频繁的字段抽出来用Hash存储
Set 集合
实现
- 元素都是整数的小Set:整数集合
- 否则:哈希表
使用场景
点赞:保证每个用户只能点一次赞
共同关注(SINTER)
推荐关注(SDIFF)
抽奖(允许重复中奖SRANDMEMBER,不允许SPOP)
潜在风险:「并、交、差」的计算复杂度高,数据量大的情况下会阻塞redis。可以用从库进行计算,或交给客户端来自行处理,从而不阻塞主库
ZSet 有序集合
比Set多了一个score,按照score排序。ZSet不支持「差」运行
实现
- redis7.0之前:小zset使用压缩列表,大zset使用跳表
- redis7.0之后:小zset使用listpack,大zset使用跳表
使用场景
排行榜:score最大的前几个(ZREVRANGE),范围score内最小的前几个(ZRANGEBYSCORE)
电话排序:获取132、133开头的号码( ZRANGEBYLEX phone [132 (134 ),不要在分数不一致的 SortSet 集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确
BitMap
实现
String
使用场景
签到统计:比如一年的签到只需要365个bit
判断登陆态:用户ID作为offset,如果ID是连续的,5000 万用户只需要 6 MB 的空间(5000万位)
连续签到用户总数:比如连续七天,需7个bitmap,对应位的位置则是用户id,将7个bitmap作与运算,并对结果BITCOUNT
Stream
专门用于消息队列。Stream出来之前各种消息队列的缺陷:
- pub/sub:不能持久化保存消息,离线重连的客户端不能读取历史消息
- List:无法重复消费,一个消息消费完就会被删除,生产者需要实现全局唯一ID
Stream特点:
- 持久化
- 自动生成全局唯一ID
- ACK确认机制
- 消费组
使用场景
Stream作为消息队列的时候,会面临:
-
可能会丢数据
- 生产者:不会丢,提交给MQ后得到响应就代表发送成功
- 消费者:不会丢,pending list机制,消费者执行完逻辑后发送xack,确保消息不丢失
- 中间件(redis):会丢失,AOF每秒异步写盘,redis宕机会造成数据丢失,主从复制也是异步的,当主从切换的时候也存在丢失数据的可能
而专业的MQ部署的是一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
-
消息堆积:Redis 的数据都存储在内存中,数据堆积会造成OOM,而专业的MQ数据最终都落盘。
pubsub为什么不能作为消息队列
- 无数据持久化:pubsub没有基于任何数据结构,不会写到RDB和AOF中
- 数据只能实时接收,消费者只能接收到订阅之后生产者发送的消息
- 消费者消费不过来的时候,消费者会被强行断开
因此pubsub只适用于即时通讯的场景,比如构建哨兵集群
数据结构
机制
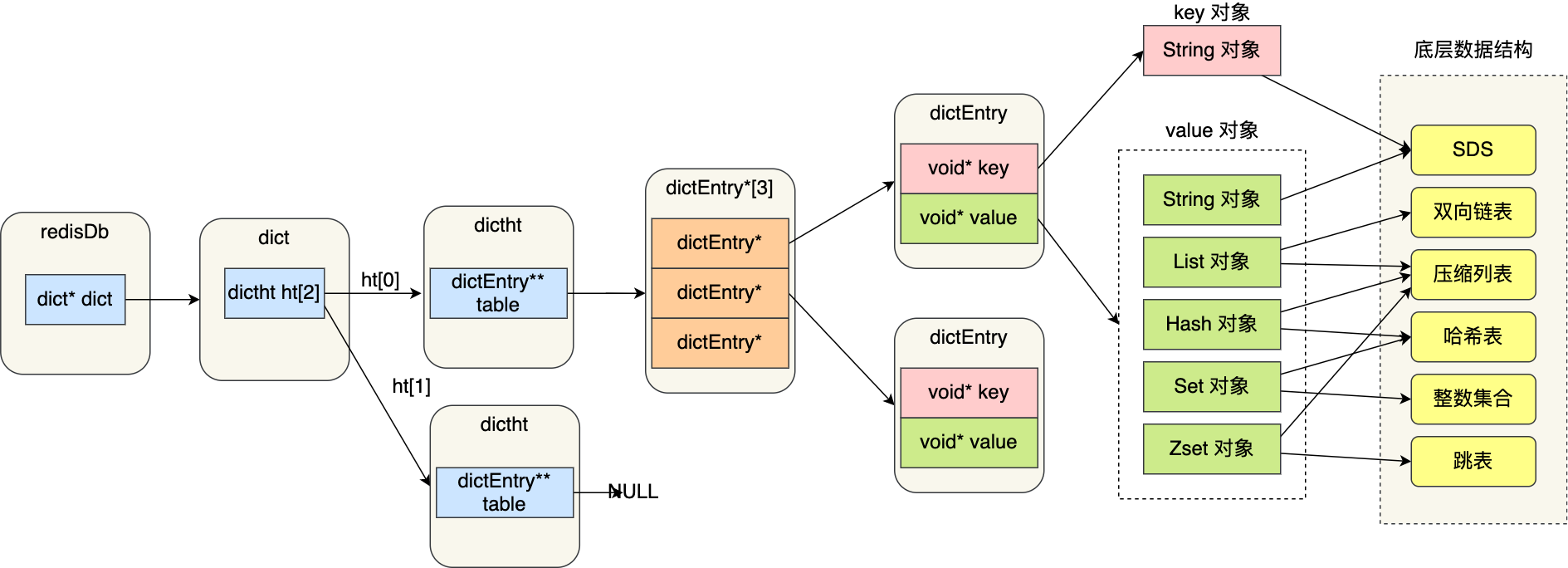
- redisDb 结构,表示 Redis 数据库的结构,结构体里存放了指向了 dict 结构的指针;
- dict 结构,结构体里存放了 2 个哈希表,正常情况下都是用「哈希表1」,「哈希表2」用语rehash;
- ditctht 结构,表示哈希表的结构,结构里存放了哈希表数组,数组中的每个元素都是指向一个哈希表节点结构(dictEntry)的指针;
- dictEntry 结构,表示哈希表节点的结构,结构里存放了 *void * key 和 void * value 指针, key 指向的是 String 对象,而 *value 则可以指向 String 对象,也可以指向集合类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
其中key和value指向的都是redisObject:
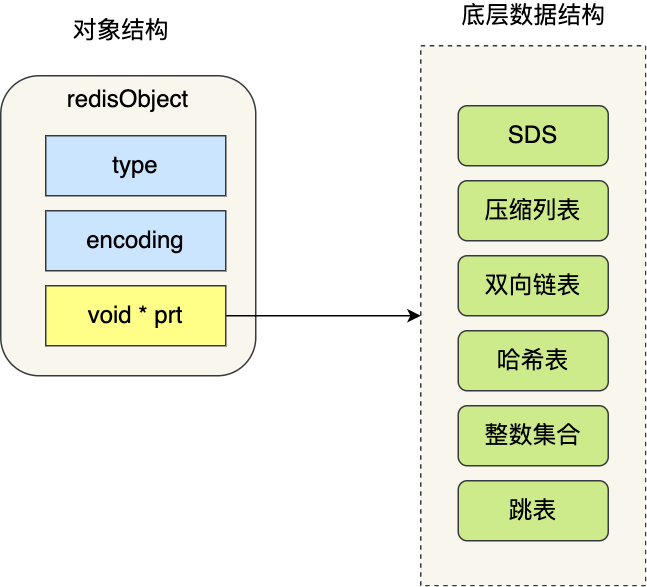
- type,标识该对象是什么类型的对象(String 对象、 List 对象、Hash 对象、Set 对象和 Zset 对象);
- encoding,标识该对象使用了哪种底层的数据结构;
- ptr,指向底层数据结构的指针。
SDS 简单动态字符串
在char buf[]的基础上增加了len(数据长度)、alloc(buf长度)、flags属性(sds类型),使其具有:
-
O(1)获取字符串长度
-
二进制安全:不再以末尾0判断字符串,而是len判断长度,使其能存储任意二进制内容
-
缓冲区安全:通过alloc - len计算剩余空间是否足够存储数据,不足的话会自动扩容
-
节省内存:比如sdshdr16和sdshdr32类型,最大只能存2^16与2^32,当字符串长度小的时候,可以减小结构头占用空间:
struct __attribute__ ((__packed__)) sdshdr16 {uint16_t len;uint16_t alloc; unsigned char flags; char buf[]; };struct __attribute__ ((__packed__)) sdshdr32 {uint32_t len;uint32_t alloc; unsigned char flags;char buf[]; };并且sdshdr取消了对齐,以时间换空间
压缩列表
结构:整个列表字节数 | 列表尾部字节距离起始地址的字节数 | 列表的节点数量 | 节点 | 结束点0xFF
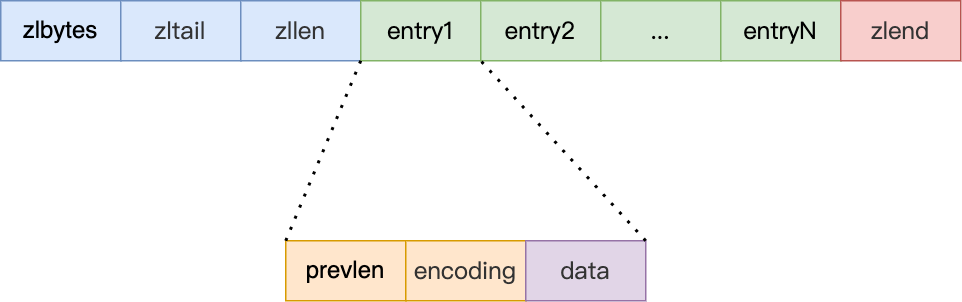
节点的结构:上一个节点的长度 | 本节点的类型和长度 | 节点数据
prevlen和encoding会根据节点数据的类型和大小来决定分配多少空间,redis这样做以尽量地节省内存
压缩列表的优点:
- 紧凑型的数据结构以利用 CPU 缓存
- 针对不同长度的数据进行相应编码,以节省内存
压缩列表的缺点:
- 除了第一个和最后一个节点,查找节点O(n)复杂度
- 连锁更新问题:某个节点扩容后,导致后一个节点的prevlen更新,并且如果prevlen不止是更新数值,占据的内存还变大了,那么后后一个节点的prevlen也要更新…最差情况下导致所有节点连锁更新,导致多次分配内存。
综上,压缩列表不适宜保存过多元素
哈希表
redis的哈希表采用拉链法解决哈希冲突,哈希表和节点结构如下
typedef struct dictht {//哈希表数组dictEntry **table;//哈希表大小unsigned long size; //哈希表大小掩码,用于计算索引值unsigned long sizemask;//该哈希表已有的节点数量unsigned long used;
} dictht;typedef struct dictEntry {//键值对中的键void *key;//键值对中的值,可以是uint、int、double或指针union {void *val;uint64_t u64;int64_t s64;double d;} v;//指向下一个哈希表节点,形成链表struct dictEntry *next;
} dictEntry;
实际上是用的是dict结构,存储了两个哈希表,一个存储数据,一个备用用来rehash
typedef struct dict {…//两个Hash表,交替使用,用于rehash操作dictht ht[2]; …
} dict;
redis采用渐进式rehash,在rehash期间,进行新增、删除、查找的时候,会将hash1对应位置上的元素迁移到hash2,这样就将rehash这整个大操作,均摊到每次用户的增删改查上。
rehash条件:
- 负载因子>=1并且没有执行RDB快照或AOF重写时,进行rehash操作
- 负载因子>=5,强制进行rehash
整数集合
typedef struct intset {//编码方式uint32_t encoding;//集合包含的元素数量uint32_t length;//保存元素的数组int8_t contents[];
} intset;
encoding表示contents内元素的大小(16、32或64位)
整数集合的升级:比如当前encoding=16,当加入一个需要用32位才能表示的整数时,需要将所有元素大小扩容为32位,并将encoding改成32
跳表
redis只有zset到了跳表(O(logn)范围查询),另外zset还用了哈希表(O(1)等值查询):
// 当插入或者更新的时候需要同时维护dict和zsl
typedef struct zset {dict *dict;zskiplist *zsl; // 大部分操作都是范围操作,使用跳表
} zset;
跳表结构:
typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;
节点结构:
typedef struct zskiplistNode {//Zset 对象的元素值sds ele;//元素权重值double score;//后向指针struct zskiplistNode *backward;//节点的level数组,保存每层上的前向指针和跨度struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;

查找规则:从头节点的最高层开始,当forward != null,并且forward小于要找的节点时,则移动到forward,否则往下移动一层,判断forward != null,并且forward…(与上一层进行的步骤相同)
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
redis跳表不严格维持第k层和第k+1层之间节点的比例,而是设定一个等于这个比例的概率:跳表在创建节点的时候,随机生成每个节点的层数,当创建新节点的时候,会生成范围为0~1的随机数,如果随机数小于0.25则层数+1,重复这个过程直到随机数大于0.25或达到最大层高64。那么两层节点的概率为1/4、三层节点概率为1/16…以此类推
跳表与常见的logn查找树相比:
- 平衡树 VS 跳表:跳表实现更简单,不需要旋转等操作维持平衡,并且在p=0.25下,每个节点平均的指针数量为1.33,而平衡树的指针为2,跳表更加节省内存,而且需要调整的话只需要修改p即可,更加灵活
- 红黑树 VS 跳表:跳表实现更简单,不需要旋转/染色来保持平衡,并且范围查询没有跳表效率好
- B+树 VS 跳表:跳表实现更简单,不需要在节点分裂/合并来保持平衡,B+树更适用于数据保存在外存的应用,核心思想是通过在节点存储更多的索引信息,降低树高,以用更少的IO次数来查询到数据
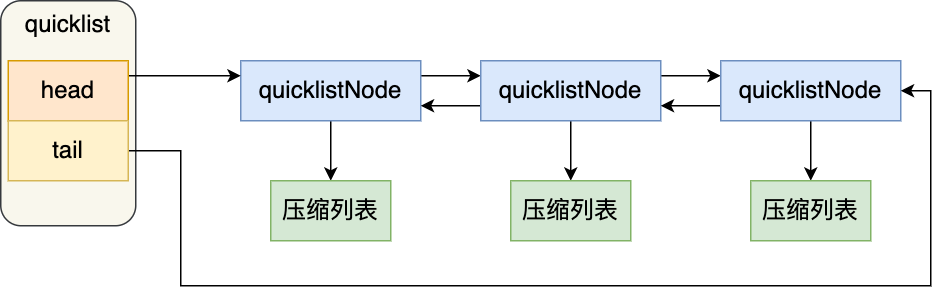
quicklist
用于新版redis实现List列表。quicklist是「压缩列表+双链表」的结合,链表每个节点是一个压缩列表,压缩列表的大小限制在一定大小范围,大大减少了连锁更新带来的负面影响。
listpack
listpack用于替代压缩列表,解决连锁更新的问题:
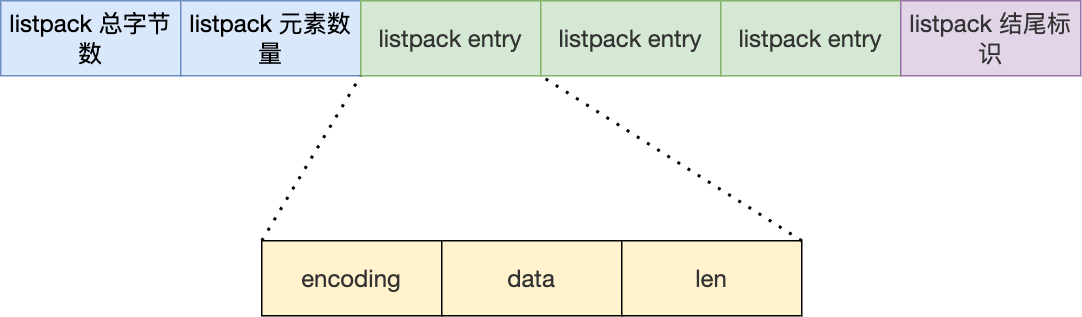
len记录encoding+data的总长度,这样一来当某个节点的大小发生变化,不会影响到其他的节点的大小。
持久化
AOF (Append only file)
AOF是记录所有「写操作」的日志。AOF的写是同步的,先进行写操作,再将该写操作写入AOF。每次写操作完成后都使用write函数将其写入AOF,但是此时只是写入了操作系统内核缓冲区,数据还没写到磁盘,可以通过fsync函数马上刷盘。可以配置三种刷盘策略:
- No:不调用fsync,由操作系统来决定什么时候将内核缓冲区的内容写到磁盘
- Everysec:每秒fsync
- Always:每次write都fsync
重写机制(实际上叫压缩机制更合理):同一个键值只保留最后一个写操作(通过内存当前所有的数据),以去除冗余的写操作。重写过程中不改动原来的AOF,只是写到临时文件,重写完成后再覆盖原文件,否则,如果直接对原文件重写并且中途重写失败的话,则数据遭到破坏不可逆转。
后台重写:创建bgrewriteaof子进程负责重写(扫描数据库中所有数据,逐一把内存数据的键值对转换成一条命令写入日志),主进程正常处理客户端请求,同时主进程开启AOF重写缓冲区用于保留新的写操作。子进程重写完成后向主线程发信号,此时主线程将AOF重写缓冲区内容追加到新的AOF文件中,并覆盖原有AOF文件。整个重写过程中主线程发生阻塞的情况有:
- 主线程由于fork子线程后的内存是共享且只读的,因此修改key的时候会触发COW(copy on write),如果是复制大key则阻塞时间长
- 主线程处理重写完成的信号
RDB (Redis Database)
RDB记录某个时间点的全量数据快照。通过save(同步)或bgsave(子进程)来生成RDB,而RDB的加载是redis启动的时候自动执行的。
混合持久化:混合持久化工作在AOF重写日志,子进程层重写AOF的时候不是将内存数据转换为写操作记录到AOF文件,而是以RDB的方式记录到AOF文件,最后主进程将RDB与重写缓冲区的AOF格式内容加入,最后文件内容为:
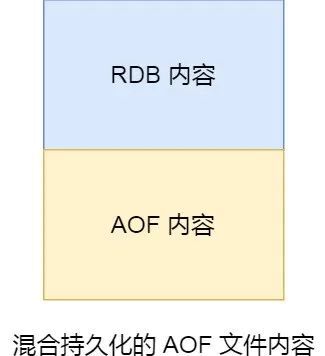
由于前半部份是RDB格式,因此下次加载的时候会很快。
数据恢复
优先加载AOF,因为AOF的数据更加完整,比如策略为Everysec的时候最多只会丢失一秒内的数据,如果AOF不存在的话再加载RDB。
过期和淘汰
过期删除策略
- 定时:创建一个定时事件,事件到达时事件处理器删除key。优点是内存友好(及时删除key),缺点是CPU不友好(key较多的时候CPU还得花时间去删除暂时也不会用到的key)
- 惰性:每次访问key的时候才去检查过期时间。优点是CPU友好,缺点是内存不友好
- 定期:每隔一段时间随机选出一批key,删除其中过期的key,优点是综合了内存和CPU友好,不过根据场景需要调参(触发删除的频率)
选择惰性+定期比较好。
内存淘汰策略
八种策略:noeviction, volatile-(random/ttl/lru/lfu), allkeys-(random/lru/lfu)
redis的lru:传统lru基于链表,而redis只是给每个key记录了最后一次访问时间,淘汰的时候随机选择一批key,淘汰访问时间最久远的,这样就不用维护链表,提升性能也节省空间。
redis的lfu:传统lfu基于双哈希+链表,而redis只是给每个key记录了最后一次访问时间和访问次数,淘汰的时候淘汰频率最低的,频率一样则淘汰访问时间最久远的。而频率的更新规则如下:
- 先衰减:距离上一次访问时间越久,衰减越大
- 再增加:按照一定概率增加,频率越大的key,越难增加
主从复制
第一次同步:在从服务器上执行「replacaof 主服务器地址 端口」,然后主从双方就会建立连接,主服务器bgsave子进程生成RDB文件并传给从服务器。生成RDB到从服务器加载完成RDB期间,主服务器新的写操作都写到缓存中。从服务器加载RDB完成后,主服务器发送缓存(新的写操作)给从服务器并执行,同步完成。
命令传播:第一次同步后,TCP连接会一直维持着,后续主服务器的写操作命令都基于这个长链接传给从服务器。
增量复制:主从意外断开重连之后,就会采取增量复制,使从服务器恢复断连到重连这段时间内未同步的数据。做法是:主服务器维护一个固定大小的环形缓冲区,维护一个master_repl_offset记录当前写到的位置,主服务器每次进行写操作时,除了将写操作命令发给从服务器,还会将其写入环形缓冲区中,并推进master_repl_offset,并且由于缓冲区大小有限,最新会覆盖最旧的数据。从服务器也维护一个slave_repl_offset记录当前读到的位置,每次接收主服务器同步过来的写命令,就会推进salve_repl_offset。重连后从服务器将自己的offset发给主服务器,主服务器检查「master_repl_offset - slave_repl_offset」如果小于缓冲区大小的话,那么就将这段缓冲区内容发给从缓冲区进行同步,否则就全量同步。
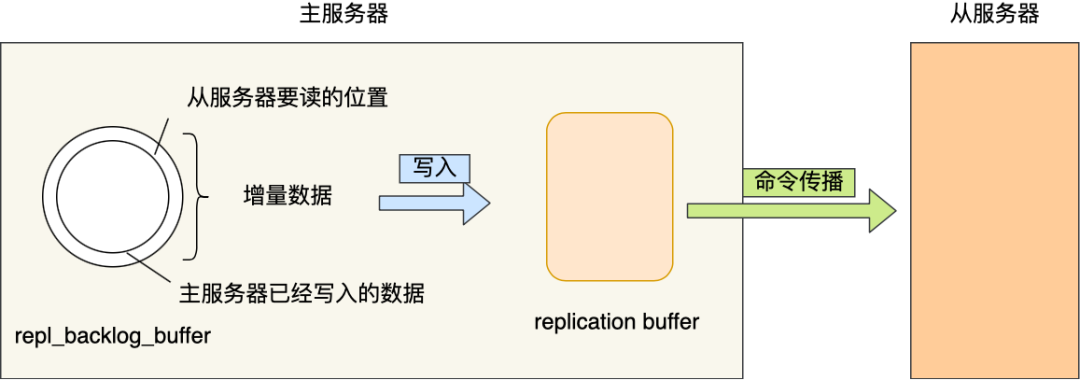
为了避免从服务器重连后全量同步开销太大,因此这个环形缓冲区最好根据实际情况设大些。
哨兵机制
由于主从模式是读写分离的, 因此主节点挂了要重新选出新的主节点,哨兵节点就是用来监控主节点、选取新主节点以及通知新的主节点已经选出来了。
客观下线:哨兵每隔一秒ping所有主从节点,如果在规定时间内没收到pong的话就判定节点为「主观下线」。而对于主节点来说,还有「客观下线」,因为主节点可能只是因为网络拥塞或者压力大导致哨兵没及时收到pong。为了减少误判,哨兵一般设为集群,只有quorum数量的哨兵节点都认为主节点主观下线,此时客观下线才成立。
leader选举:判定客观下线后,还需要从哨兵中选出leader,由leader来执行主从切换。由判定客观下线的哨兵节点成为leader,比如哨兵B先发现主观下线,询问哨兵A和C是否也主观下线,收到超半数且达到quorum数量的赞成票后判定为客观下线并成为candidate,随后B先投自己一票,并且让A和C也投B一票,当票数超过半数则B成为leader,开始执行主从切换。
主从切换步骤(由leader执行):
-
哨兵选取新主节点
- 根据优先级配置选择优先级大的节点
- 如果优先级相同,选择slave_repl_offset更靠近master_repl_offset的节点
- 如果slave_repl_offset相同,那么选择ID较小的节点
然后向该节点发送slaveof no one使其转换为主节点, 并每秒发送一次info,轮询其状态
-
哨兵向其他从节点发送「slaveof 新主节点地址 端口」
-
使用pub/sub,哨兵通知客户端主节点的改变
-
哨兵继续监视旧主节点,发现其上线之后发送「slaveof 新主节点地址 端口」
哨兵集群的组成
哨兵集群的建立:通过在主节点上使用pub/sub,进行哨兵之间的通讯。比如哨兵A在频道上发布自己的地址和端口,其他哨兵就会收到并与A建立连接
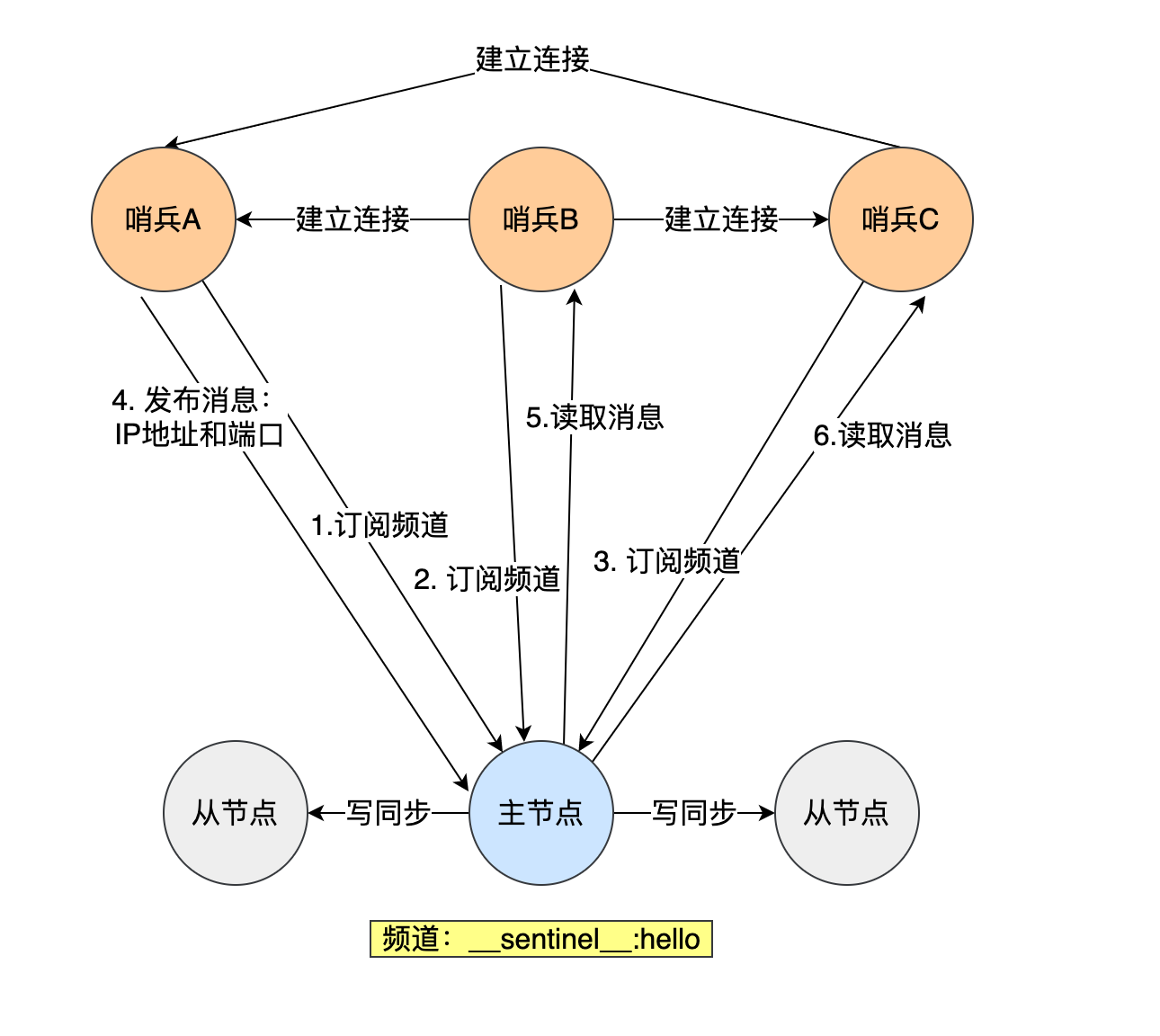
哨兵获取从节点信息:哨兵向主节点发送info命令,主节点返回从节点信息,获取从节点信息后,哨兵就可以与从节点建立连接并监视从节点
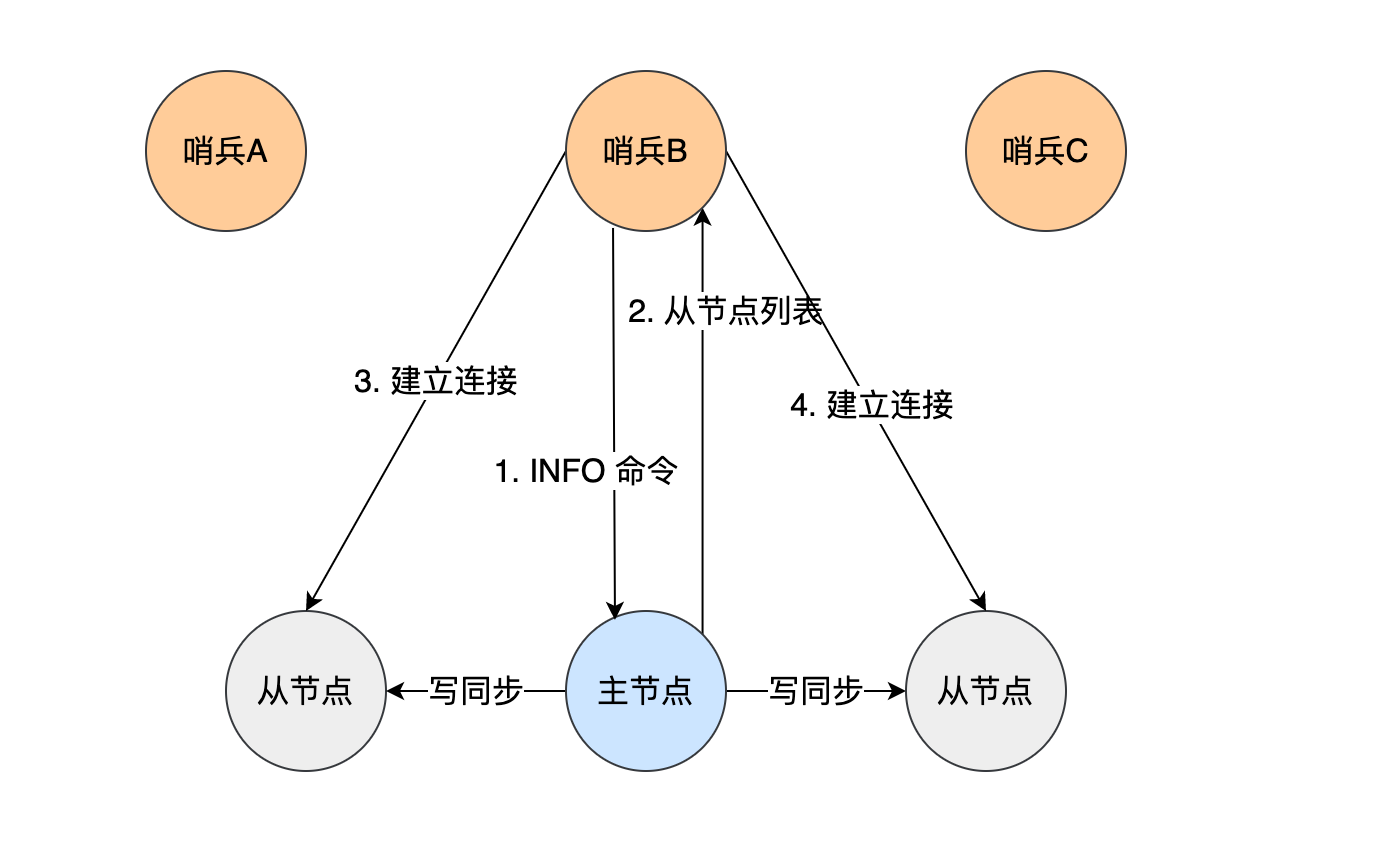
总而言之,主节点作为通讯中介。
切片集群
其实就是将数据存储到不同的redis实例上,以降低对单主节点的依赖,提高redis服务的读写性能。
一个redis切片集群有16384个哈希槽,要么平均要么手动将这些个哈希槽分配给集群中各个redis实例。当存储数据的时候,将key哈希到对应的哈希槽中,本质就是哈希到对应的redis节点中。
缓存
缓存雪崩
产生原因:大量key同时过期、redis宕机
解决办法:
- 大量key同时过期:
- 过期时间+随机数:避免大量key同时失效
- 互斥锁:避免缓存重复构建
- 后台更新:不设置过期时间,让后台线程定时更新缓存。除了更新缓存,也要负责内存淘汰而重构缓存,有两种方法重构:
- 频繁轮询,检测到缓存淘汰后马上重构
- 业务线程发现缓存失效后,通过消息队列告知后台线程去重构
- redis宕机
- 服务熔断/限流,等到redis恢复并预热完成后再恢复
- 构建集群,主从切换
缓存击穿
产生原因:热点数据过期
解决办法:
- 互斥锁
- 后台更新
缓存穿透
产生原因:数据库根本没有这样的数据
解决办法:
-
检查请求参数,过滤非法请求
-
缓存空值
-
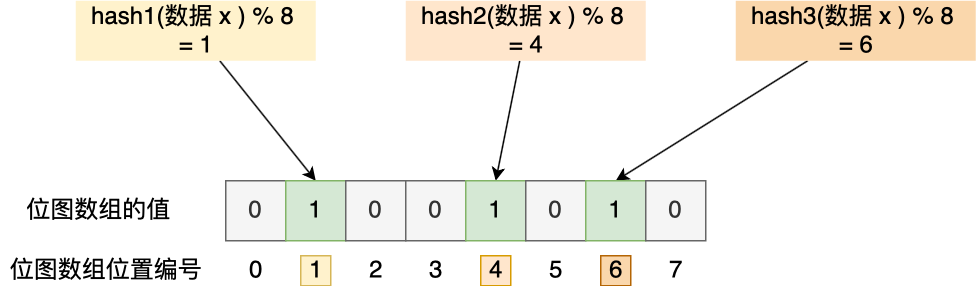
布隆过滤器:写入key的时候为key生成多个hash,并将这多个hash在哈希表对应的位置1。当读key的时候按同样方式生成多个hash,如果这些hash对应的位都为1,则判定为key存在。综上,判定为不存在一定不存在,但是判定存在不一定存在。
面试题
缓存和数据库一致性
先更新数据库再更新缓存的问题:
- A更新数据库
- B更新数据库
- B更新缓存
- A更新缓存
先更新缓存再更新数据库的问题:
- A更新缓存
- B更新缓存
- B更新数据库
- A更新数据库
无论是先更新数据库还是先更新缓存都会存在数据库和缓存不一致。
先删缓存再更新数据库的问题:
- A删缓存
- B读缓存未命中,重构缓存为旧值
- A更新数据库
先更新数据库再删除缓存的问题1(假设当前缓存没有数据):
- A读缓存未命中,读取数据库
- B更新数据库,删除缓存
- A用旧值重建缓存
但上述情况发生概率很低,因为A读完数据库后马上重建缓存,而「重建缓存」这个动作其实是很快的,一般在「B更新数据库,删除缓存」前就已经完成,因此「先更新数据库再删除缓存」这个方案相比之下最好。最后再加上过期时间兜底这种发生不一致的低概率情况。
先更新数据库再删除缓存的问题2:若「删除缓存」这个操作失败的话,直到下次更新之前,读到的都是缓存中的旧值,解决办法有两种
- 重试:将「删除缓存操作」加入消息队列,重试直到成功,并向消息队列返回ack
- 订阅mysql binlog:比如使用canal中间件,订阅binlog中数据的更新操作,并推送给缓存服务让其删除对应的缓存
两者都是采用异步操作缓存,异步删除是为了快速响应客户端,但要求客户端对重试这段时间内容忍读到缓存中的旧值(即在consistency和 available之间选择后者)。
再次探讨为什么是删除而不是更新缓存:缓存的数据可能与数据库多张表有关,更新缓存可能还需要查询多张表。另外写多读少的场景下,删除缓存比更新缓存更有性价比。
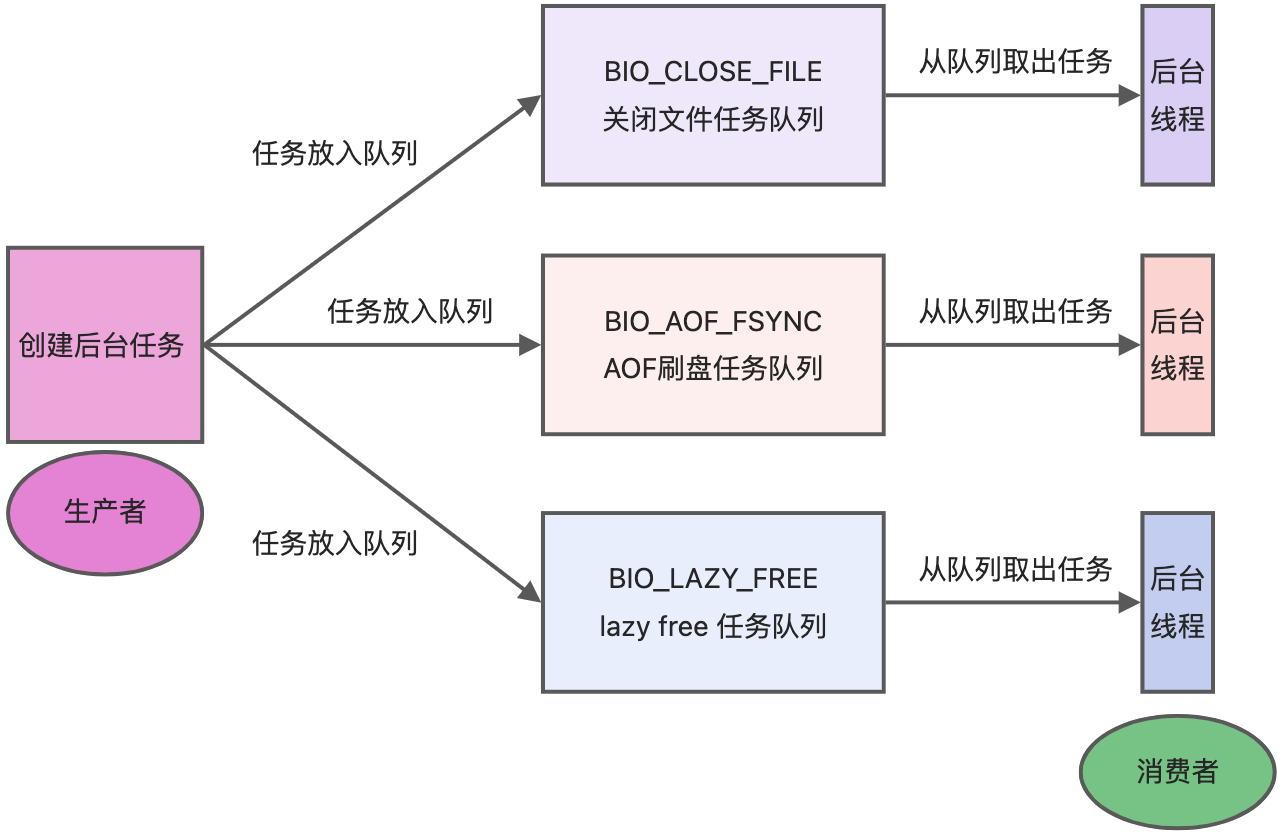
redis是单线程吗
redis单线程指的是「接收客户端请求,数据读写,响应客户端」这个过程。而redis内部还会启动几个线程来处理其他事情:
- 关闭文件的线程
- AOF刷盘线程
- lazyfree线程,比如执行unlink key / flushdb async / flushall async 等命令
该单线程采用多路复用IO来接收客户端的请求:
- 创建epoll和socket,绑定「连接事件处理函数」并加入epoll,然后epoll_wait等待事件到来
- 如果是连接事件,accept这个连接,绑定「读事件处理函数」并加入epoll
- 如果是读事件,读取客户端发来的请求并执行,然后将客户端对象添加到发送队列,将执行结果放到发送缓冲区,注册「写事件处理函数」并加入epoll
- 如果是写事件,通过write将缓冲区的执行结果发送出去,如果这一轮没有发完,则继续注册「写事件处理函数」
随着网络硬件性能的提升,性能瓶颈出现在网络IO上,因此新版redis又引入了多线程来读/写网络IO数据。至此,redis的线程有:
- 主线程:负责执行命令
- 三个后台线程:分别处理文件关闭(bio_close_file)、AOF刷盘(bio_aof_fsync)、释放内存(bio_lazy_free)
- IO线程(多线程):读请求和写响应,分担网络IO压力
redis集群脑裂以及解决办法
脑裂:指的是集群出现多个主节点,比如某个集群的主节点被分区(暂时与其他节点无法连接,好比自己一个处于一个与世隔绝的分区),但主节点本身与客户端都不知情,并继续接收来自客户端的命令。接着哨兵从从节点中选出新的主节点,此时整个集群同时存在两个主节点。
脑裂带来的问题:当被分区的主节点恢复并重新加入集群后,会被哨兵降级为从节点,并且数据被全量同步为新主节点的数据,导致旧主节点被分区这段时间内客户端写入的数据被丢失。
解决方案:为主节点接收客户端命令设定条件,即主节点保持连接的从库至少有N个,并且主从复制时从库的ACK消息延迟不能超过T秒,否则该主库就会直接返回错误给客户端,拒绝处理命令,直到新主库上线
从库如何处理过期key
从库不会自己主动写或删除任何key,而是主库发现key过期时,才会在AOF新增一条del,并同步到所有从库。
如何只缓存热点数据
使用zset。比如经常访问的top1000商品,score存储的是访问次数,数据存储的是商品的ID。当访问商品命中的时候,更新score+1。定期清理排名1000以外的缓存。
如何处理大key
大key指的是value很大。
带来的问题:对大key操作耗时、传输大key耗时、阻塞后续请求、切片集群数据倾斜
查找bigkey的方法:
- redis-cli --bigkeys:最好在从节点执行。这个方法只能返回每种类型中最大的那个 bigkey。对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量
- scan + type + [strlen/llen/hlen/scard/zcard/memory usage]
- 使用第三方RDB分析工具查找大key
删除bigkey的方法:
- 分批次删除
- 异步删除:手动unlink,或者开启lazyfree(针对内存淘汰、过期删除、从节点清除自身数据,避免这些操作阻塞主线程)
redis支持事务吗
实际上redis支持的不是事务而是批量执行队列,并且命令不作检查无脑入队,提交后正确的命令会被执行,错误的命令会报错,即不符合原子性(要么全部成功要么全部失败):
#获取name原本的值
127.0.0.1:6379> GET name
"xiaolin"
#开启事务
127.0.0.1:6379> MULTI
OK
#设置新值
127.0.0.1:6379(TX)> SET name xialincoding
QUEUED
#注意,这条命令是错误的
# expire 过期时间正确来说是数字,并不是‘10s’字符串,但是还是入队成功了
127.0.0.1:6379(TX)> EXPIRE name 10s
QUEUED
#提交事务,执行报错
#可以看到 set 执行成功,而 expire 执行错误。
127.0.0.1:6379(TX)> EXEC
1) OK
2) (error) ERR value is not an integer or out of range
#可以看到,name 还是被设置为新值了
127.0.0.1:6379> GET name
"xialincoding"
redis分布式锁
set nx
加锁:
SET lock_key unique_value NX PX 10000
unique_value是客户端唯一标识
释放锁:判断是否当前客户端+解锁(lua脚本保证原子性):
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])
elsereturn 0
end
优点:高性能、实现简单、避免单点故障
缺点:超时事件不好设置、集群模式下分布式锁不可靠(锁还未同步到从节点时主节点宕机,选出新主节点后相当于锁就失效了)
redis在集群模式下如何实现可靠的分布式锁
使用redlock,核心思想是向每个节点都申请锁(相当于所有节点都是主节点):
- 条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 节点上成功获取到了锁;
- 条件二:客户端从大多数节点获取锁的总耗时(t2-t1)小于锁设置的过期时间。

![[云原生] K8S声明式资源管理](https://img-blog.csdnimg.cn/direct/06b922e839a748c7b189047639cc07c9.png)
