【JavaGuide面试总结】MySQL篇·下
- 1.介绍一下索引吧
- 2.索引的优缺点
- 3.讲一下索引的底层数据结构
- Hash 表
- B 树& B+树
- 4.说说MyISAM 引擎和 InnoDB 引擎 B+Tree 实现机制的不同
- 5.索引类型
- 主键索引(Primary Key)
- 二级索引(辅助索引)
- 6.简单说说聚簇索引与非聚簇索引
- 聚簇索引(聚集索引)
- 非聚簇索引(非聚集索引)
- 7.非聚簇索引一定回表查询吗(覆盖索引)?
1.介绍一下索引吧
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。🤑
2.索引的优缺点
优点 :
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点 :
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
3.讲一下索引的底层数据结构
Hash 表
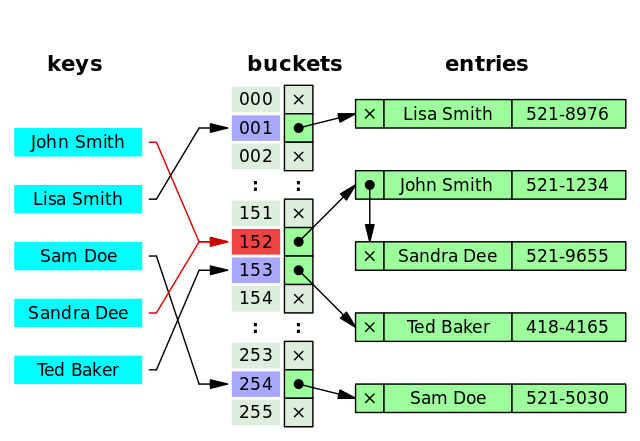
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))
为何能够通过 key 快速取出 value 呢? 原因在于 哈希算法(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value
hash = hashfunc(key)
index = hash % array_size

但是!哈希算法有个 Hash 冲突 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 链地址法。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。
既然哈希表这么快,为什么 MySQL 没有使用其作为索引的数据结构呢? 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
试想一种情况:
SELECT * FROM tb1 WHERE id < 500;
Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
B 树& B+树
B 树也称 B-树(注意这里不是B减树,而是B杠树),全称为 多路平衡查找树 ,B+ 树是 B 树的一种变体。B 树和 B+树中的 B 是 Balanced (平衡)的意思。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。😲
B 树& B+树两者有何异同呢?
- B 树的所有节点既存放键(key) 也存放 数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显
4.说说MyISAM 引擎和 InnoDB 引擎 B+Tree 实现机制的不同
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引(非聚集索引)”
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(聚集索引)”。而其余的索引都作为 辅助索引 ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方
InnoDB中在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引
因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂😟
5.索引类型
主键索引(Primary Key)
数据表的主键列使用的就是主键索引。
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在 null 值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键(row_id,隐藏的)

二级索引(辅助索引)
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置😤
- 唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
- 普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。

6.简单说说聚簇索引与非聚簇索引
聚簇索引(聚集索引)
聚簇索引即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引😢
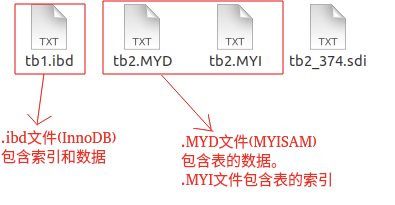
在 MySQL 中,InnoDB 引擎的表的 .ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
优点 :
- 查询速度非常快 :聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
- 对排序查找和范围查找优化 :聚簇索引对于主键的排序查找和范围查找速度非常快。
缺点 :
- 依赖于有序的数据 :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- 更新代价大 : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
非聚簇索引(非聚集索引)
非聚簇索引即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引😭
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
优点 :
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
缺点 :
- 依赖于有序的数据 :跟聚簇索引一样,非聚簇索引也依赖于有序的数据
- 可能会二次查询(回表) :这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
这是 MySQL 的表的文件截图:
7.非聚簇索引一定回表查询吗(覆盖索引)?
非聚簇索引不一定回表查询。
试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
SELECT name FROM table WHERE name='dahezhiquan';
那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!如果 SQL 查的就是主键呢?
SELECT id FROM table WHERE id=1;
主键索引本身的 key 就是主键,查到返回就行了。这种情况就称之为覆盖索引了。