1.初识Redis
Redis是一种键值型的NoSql数据库,这里有两个关键字:
-
键值型
-
NoSql
其中键值型,是指Redis中存储的数据都是以key、value对的形式存储,而value的形式多种多样,可以是字符串、数值、甚至json:

而NoSql则是相对于传统关系型数据库而言,有很大差异的一种数据库。
1.1.认识NoSQL
NoSql可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
1.1.1.结构化与非结构化
🏏传统关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束等等信息,插入的数据必须遵守这些约束:
🏑并且在程序上线很久以后,数据库的表机构几乎成为不可修改的存在,如果要修改的话,要牵动的结构会非常多。
这个算是结构型数据库的短处。
🏒而NoSql则对数据库格式没有严格约束,往往形式松散,自由。可以是键值型,也可以是文档型,甚至可以是图格式。
1.1.2.关联和非关联
🥍传统数据库的表与表之间往往存在关联,例如外键。
🏓而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合:
{id: 1,name: "张三",orders: [{id: 1,item: {id: 10, title: "荣耀6", price: 4999}},{id: 2,item: {id: 20, title: "小米11", price: 3999}}]
}
此处要维护“张三”的订单与商品“荣耀”和“小米11”的关系,不得不冗余的将这两个商品保存在张三的订单文档中,不够优雅。还是建议用业务来维护关联关系。
1.1.3.查询方式
🏸传统关系型数据库会基于Sql语句做查询,语法有统一标准;
🥊而不同的非关系数据库查询语法差异极大,五花八门各种各样。
1.1.4.事务
每日一记:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
🥋传统关系型数据库能满足事务ACID的原则。
🥅而非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性。
1.1.5.总结
除了上述四点以外,在存储方式、扩展性、查询性能上关系型与非关系型也都有着显著差异,总结如下:
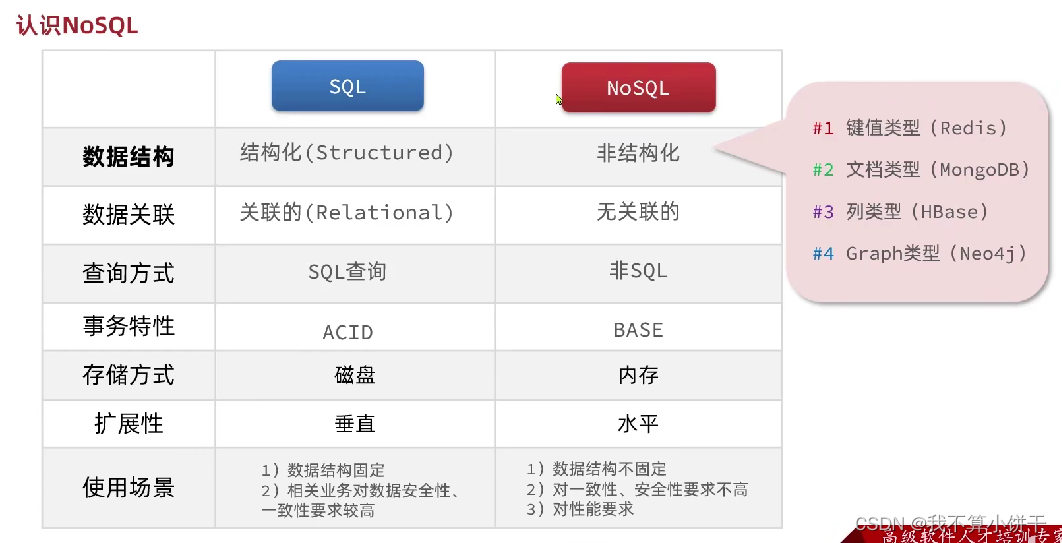
😩其中base意味非关系数据库可以完成基础的事务,或者就不能完成事务
😫关系型数据库在设计之初就没有考虑到分布式的需求,所以我们在存储数据到关系型数据库的时候,其实都是存在于本机,影响数据库性能的其实就是本机的性能,而非关系型数据库,在设计之初就考虑到了数据拆分的需求,因此他们在插入数据的时候都会基于这个数据的id或者是唯一的标识做一个哈希运算,根据哈希运算的结果去判断这个数据去存储到哪一个结点上,从而实现数据的拆分。因此nosql在扩展的时候非常轻松实现。
- 存储方式
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
- 扩展性
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
💆🛌🖥️🎮🕹️⚔️🤡
1.2.认识Redis
Redis诞生于2009年全称是Remote Dictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库。
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化(持久化是将程序数据在持久状态和瞬时状态间转换的机制。通俗的讲,就是瞬时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存),其实就是redis会定期将数据存到磁盘)
- 支持主从集群(从节点可以备份主节点的数据,这样子主节点宕机,数据可以从从节点中找到,主从可以做读写分离,从而大大提高查询效率)、分片集群(就是将数据拆分,存储的上限大大提高)
- 支持多语言客户端
作者:Antirez
Redis的官方网站地址:https://redis.io/
为什么redis单线程但是性能却那么好
- 😟因为数据是写在内存的
- 👺IO多路复用
什么是IO多路复用
一句话解释:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力。
应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标的输入、中断信号等等事件,再比如web服务器如nginx,需要同时处理来来自N个客户端的事件。
逻辑控制流在时间上的重叠叫做 并发
而CPU单核在同一时刻只能做一件事情,一种解决办法是对CPU进行时分复用(多个事件流将CPU切割成多个时间片,不同事件流的时间片交替进行)。在计算机系统中,我们用线程或者进程来表示一条执行流,通过不同的线程或进程在操作系统内部的调度,来做到对CPU处理的时分复用。这样多个事件流就可以并发进行,不需要一个等待另一个太久,在用户看起来他们似乎就是并行在做一样。
但凡事都是有成本的。线程/进程也一样,有这么几个方面:
线程/进程创建成本
CPU切换不同线程/进程成本 Context Switch
多线程的资源竞争
有没有一种可以在单线程/进程中处理多个事件流的方法呢?一种答案就是IO多路复用。
因此IO多路复用解决的本质问题是在用更少的资源完成更多的事。
- 👻良好的编码