这两天闲的无聊,随便爬了点小说和趣图,因为好久没使用xpath了,所以遇到了点问题,就是xpath值一直为空,举个例子:
爬取小说网站。
使用xpath工具查询小说网站导航栏的xpath路径是这样子的:
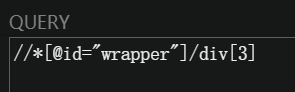
值是酱紫的:
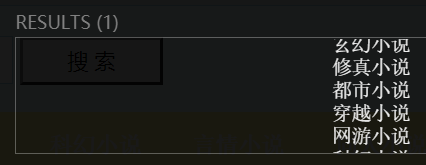
用python测试下xpath
import requests
from lxml import etreeheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1"}
url = "http://www.b520.cc/"
按xpath直接使用
rep = requests.get(url =url,headers=headers).text
html = etree.HTML(rep)
xp = '//*[@id="wrapper"]/div[3]' # xpath直接拷贝的
nav = html.xpath(xp)
print(nav)
返回

转成文本加个text()
xp = '//*[@id="wrapper"]/div[3]/text()'
用复制的xpath就算加上了text()也才打印出这个玩意,完全牛头不对马嘴
再仔细看一看网页

发现文本及链接全在 li的a标签里面
后面的路径改进一下
# xp = '//*[@id="wrapper"]/div[3]/text()' # xpath直接拷贝的
new_xp = "//*[@id='wrapper']/div[2]/ul/li/a/text()" # 自己找的xpath
打印结果:

数据出来了
想要链接的话,直接把text()改成@href
"//*[@id='wrapper']/div[2]/ul/li/a/@href"
总得来说,现在不能过于依赖于xpath工具,需要对比网页查找路径