已解决Python读取20GB超大文件内存溢出报错MemoryError
文章目录
- 报错问题
- 报错翻译
- 报错原因
- 解决方法1
- 解决方法2(推荐使用)
- 帮忙解决
报错问题
日常数据分析工作中,难免碰到数据量特别大的情况,动不动就2、3千万行,如果直接读进 Python 内存中,且不说内存够不够,读取的时间和后续的处理操作都很费劲。最近处理文本文档时(文件约20GB大小),出现memoryError错误和文件读取太慢的问题,报错代码如下:
with open(file, 'r', encoding='utf-8') as f:json_list = f.readlines()
报错信息如下:
MemoryError
报错翻译
报错翻译如下:内存错误
报错原因
报错原因:
这种方式是将文件里面所有内容按行读取到一个大列表中,对于小文件,这种方式其实挺方便,但对于大文件就会出现内存可能不足的情况,报 MemoryError 错误,或者消耗掉很客观的内存资源。小伙伴按下面的方法解决任选其一即可!!!
解决方法1
pandas.read_csv参数chunksize通过指定一个分块大小(每次读取多少行)来读取大数据文件,可避免一次性读取内存不足,返回的是一个可迭代对象 TextFileReader
import pandas as pdreader = pd.read_csv('E:\Python学习\新建文件夹\新建文本文档.txt', sep=',', chunksize=10)for chunk in reader:df = chunkprint(type(df), df.shape)
解决方法2(推荐使用)
EmEditor介绍: 简单好用的文本编辑器,支持多种配置,自定义颜色、字体、工具栏、快捷键设置,可以调整行距,避免中文排列过于紧密,具有选择文本列块的功能(按ALT键拖动鼠标),并允许无限撤消、重做,总之功能多多,使用方便,是替代记事本的最佳编辑器。我使用的EmEditor的分割功能,将20G的json文件按行分割为10个小文件。
EmEditor下载地址:https://zh-cn.emeditor.com/#download
(1)安装完成后,找到工具 》 点击分割文件:
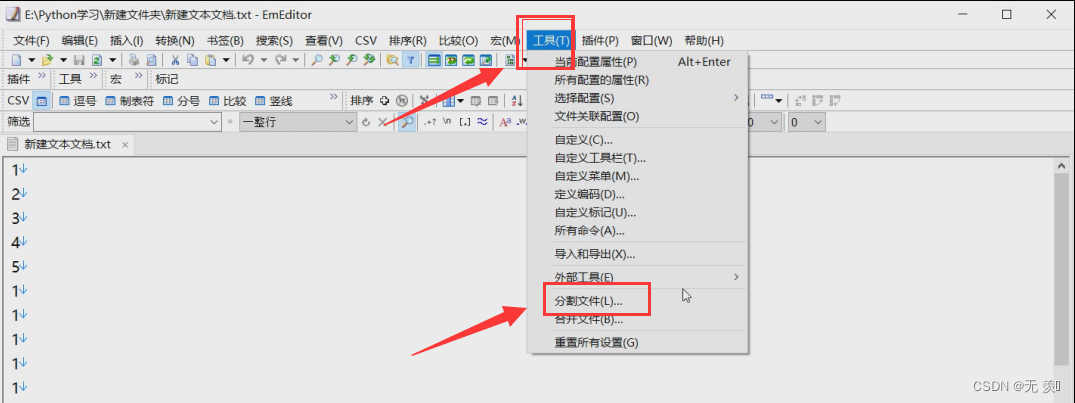
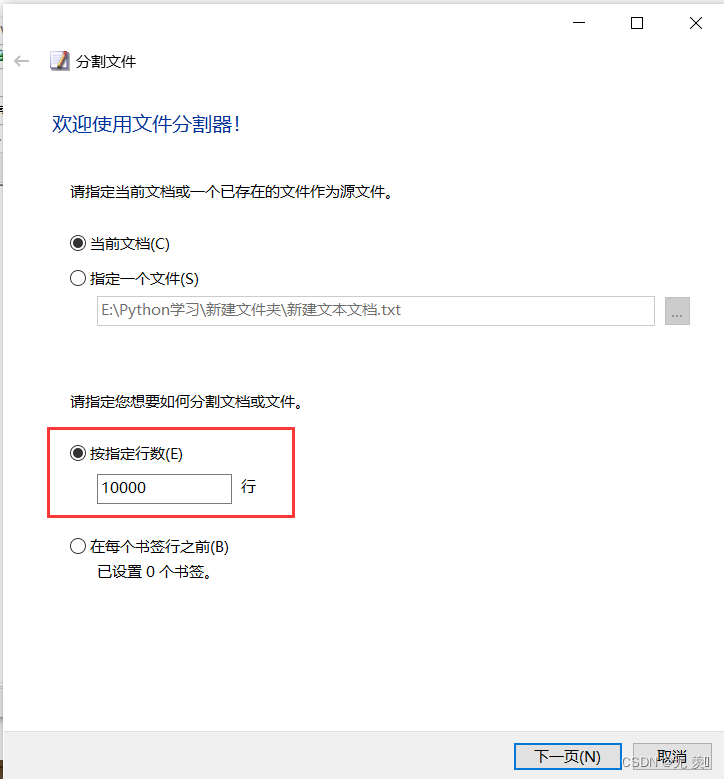
(2)指定分割的行数(以多少行分割成一个新文件),然后点击下一页:
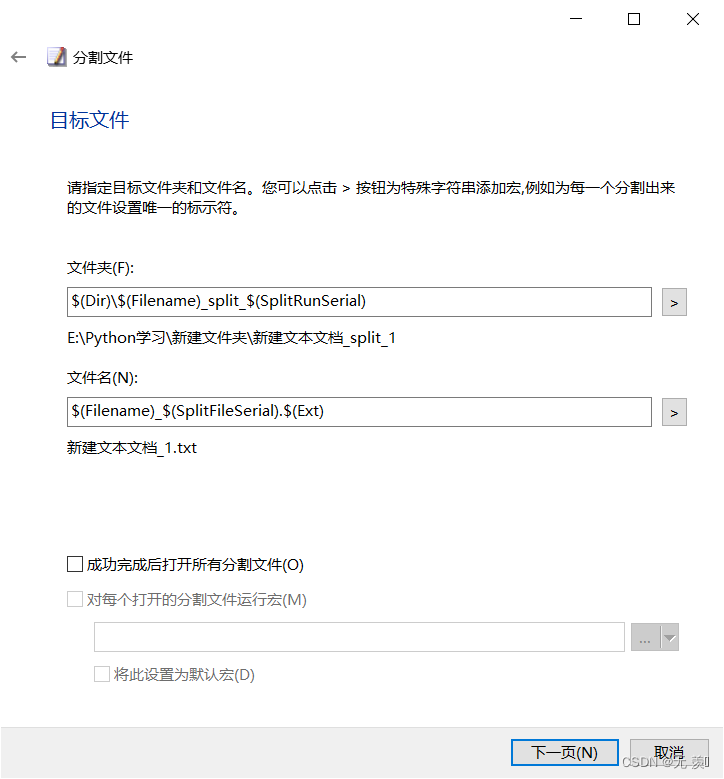
(3)默认即可接着一直点击下一页:
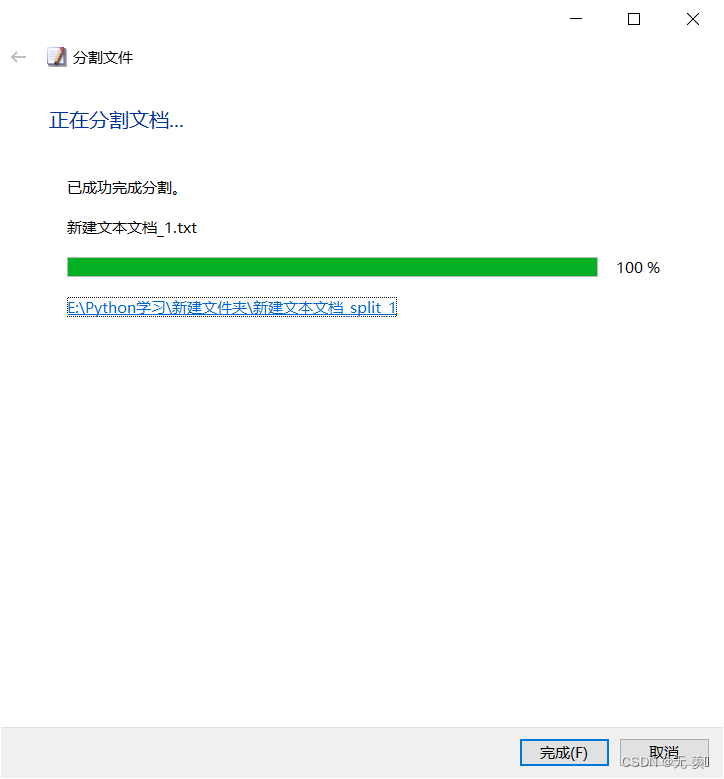
(4)分割完成,点击完成:
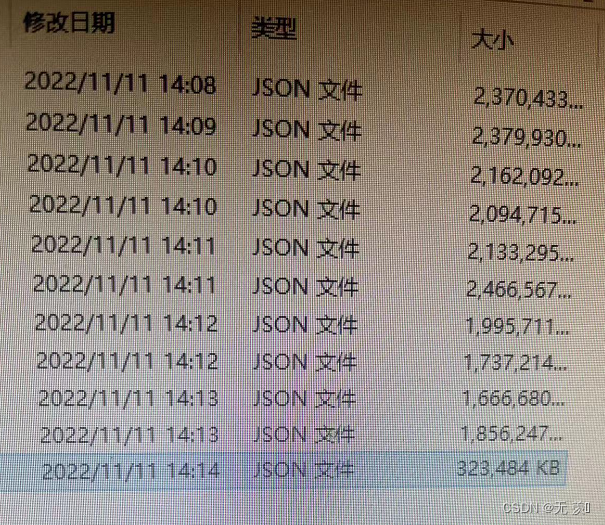
(5)找到对应的文件,把json文件分割为10小份(这个是写文章之前分割的):
帮忙解决
本文已收录于:《告别Bug专栏》,欢迎免费订阅!!!
本专栏用于记录学习和工作中遇到的各种疑难编程Bug问题,以及粉丝群里小伙伴提出的各种问题,文章形式:报错代码 + 报错翻译 + 报错原因 + 解决方法,包括程序安装、运行程序过程中遇到的等等问题,博主心愿:让天下没有难学的编程,从此告别Bug!!!
订阅专栏 + 关注博主后,扫描下方二维码进全栈学习互助交流群可以帮忙解决问题,并且可以免费领取300本IT电子书籍、学习资料、简历模板、面试题库,和小伙伴们交流学习、抱团取暖,共同进步!!!