YOLOv8训练自己的目标检测数据集
目录标题
- 源码下载
- 环境配置
- 安装包
- 训练自己的数据集
- 数据集文件格式
- 数据集文件配置
- 超参数文件配置
- 训练数据集
- 命令行训练
- 脚本.py文件训练
- 进行detect
- 显示detect的效果
源码下载
YOLOv8官方的GitHub代码,同时上面也有基础环境的配置要求以及代码运行的教程。下载后的源码文件名应该是ultralytics-main。
环境配置
这里可参考YOLOv5,YOLO v7的代码环境配置。
安装包
需要额外的安装一些包,因为后面需要用到。
pip install ultralytics
训练自己的数据集
数据集文件格式
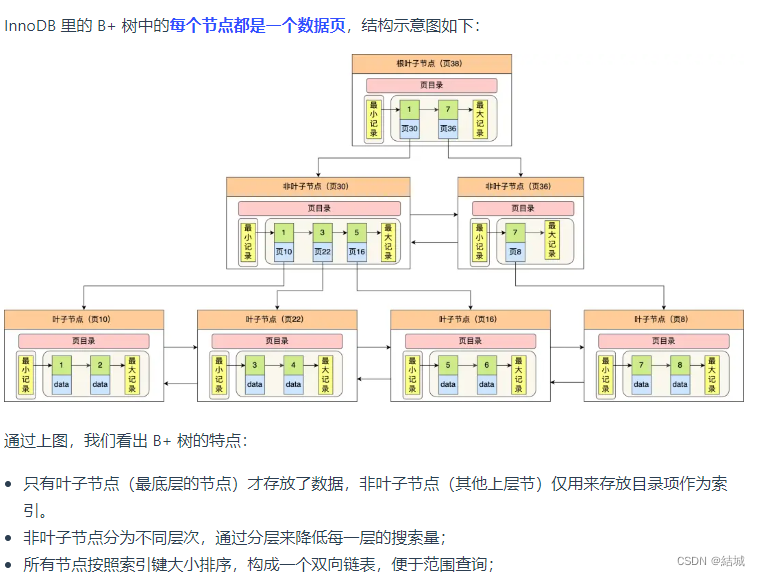
- 数据集文件格式是txt的yolo格式,整体数据集文件格式如下:
- 同时images下的文件格式如下: train(训练集图片),val(测试集图片),test(测试集图片)
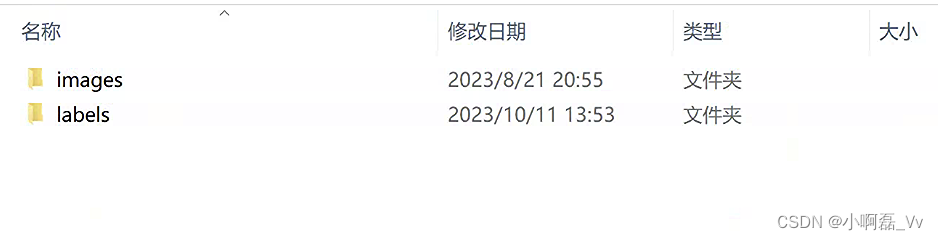
- 同时labels下的文件格式如下: train(训练集图片对应的标签),val(测试集图片对应的标签),test(测试集图片对应的标签)

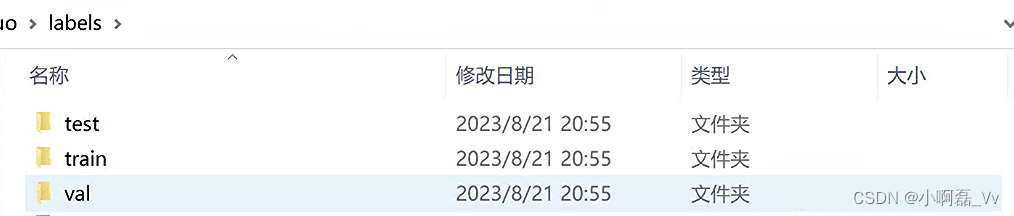
- 整体数据集格式文件如下
├── linhuo
│ ├── images
│ │ ├── train
│ │ ├── val
│ │ ├── test
│ ├── labels
│ │ ├── train
│ │ ├── val
│ │ ├── test
数据集文件配置
数据集文件配置的位置如下:
ultralytics-main/ultralytics/cfg/datasets/
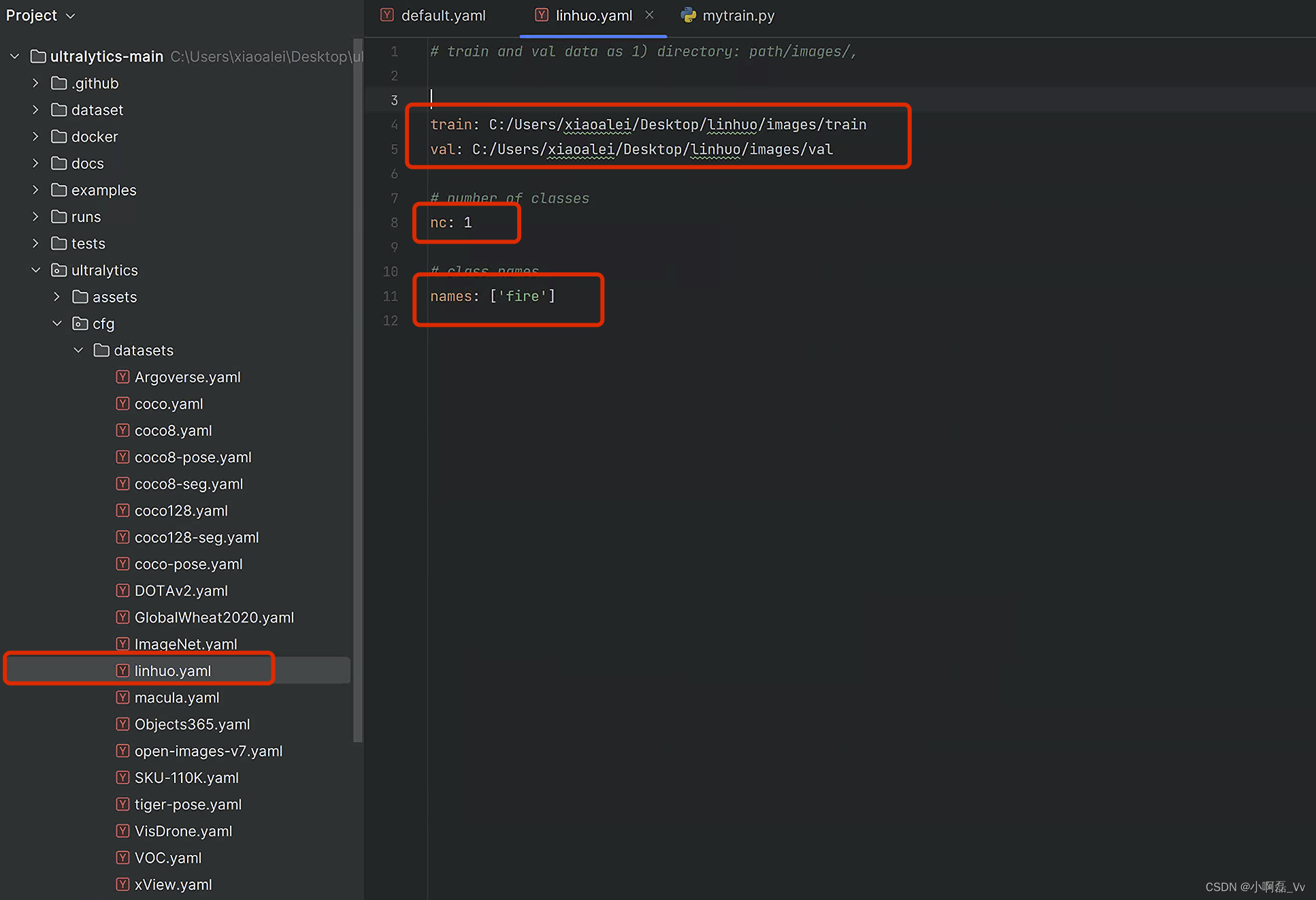
在该文件下创建数据自己数据集文件配置的yaml文件,这是我创建自己数据集配置的yaml文件。同时yaml文件内要说明以下内容:
- 索引到数据集文件images下的train、val
- 数据集标注的类别数目
- 数据集标注的类别名称
- 如我的数据集只有1类, 标注类别是fire
超参数文件配置
超参数文件配置的路径:
ultralytics-main/ultralytics/cfg/default.yaml
具体的超参数说明可以看看网上的教程,这里主要配置model,data,patience。
- model: 可以配置yolov8n.pt, yolov8n.yaml(这里填写配置yolov8n.pt, yolov8n.yaml的具体路径),如果配置yolov8n.yaml需要将类别数目改为1。
model: './weights/yolov8n.pt' # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml
- data: 这里是填写数据集文件配置的地址。
data: 'ultralytics/cfg/datasets/linhuo.yaml' # (str, optional) path to data file, i.e. coco128.yaml
- patience: epochs to wait for no observable improvement for early stopping of training(就是多少次没有训练一个好的结果就会提前停止训练)。
训练数据集
命令行训练
- task=detect:目标检测
- mode=train:训练模式
- model=yolov8n.pt:模型预训练权重的地址,我是默认放到ultralytics-main目录下
yolo task=detect mode=train model=yolov8n.pt data=ultralytics/cfg/datasets/linhuo.yaml batch=16 epochs=500
脚本.py文件训练
- 新建立一个python脚本文件 mytrain.py
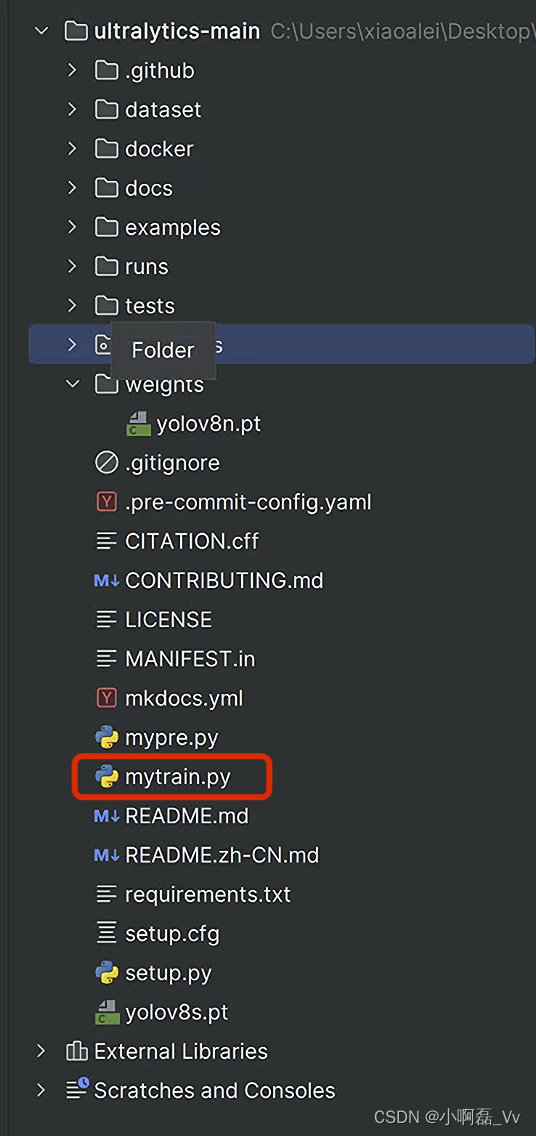
代码为:直接运行即可。
from ultralytics import YOLO
# 权重网络模型加载权重模型
model = YOLO('ultralytics/cfg/models/v8/yolov8.yaml').load('./weights/yolov8n.pt') # build from YAML and transfer weights# Train the model: 数据集配置yaml
results = model.train(data='ultralytics/cfg/datasets/linhuo.yaml', epochs=500, batch=16)
进行detect
- 新建立一个python脚本文件 mypre.py上面图片有
from ultralytics import YOLO
model = YOLO('runs/detect/train/weights/best.pt')# 检测的图片的路径
source = 'ultralytics/assets/2708.jpg'# 预测结果
results = model.predict(source, save=True)
显示detect的效果


![批量插入SQL 错误 [933] [42000]: ORA-00933: SQL 命令未正确结束](https://img-blog.csdnimg.cn/0f39e9d28bf44c3bbcf38aa0ce55b669.png)