innoDB是按照页为单位读写的
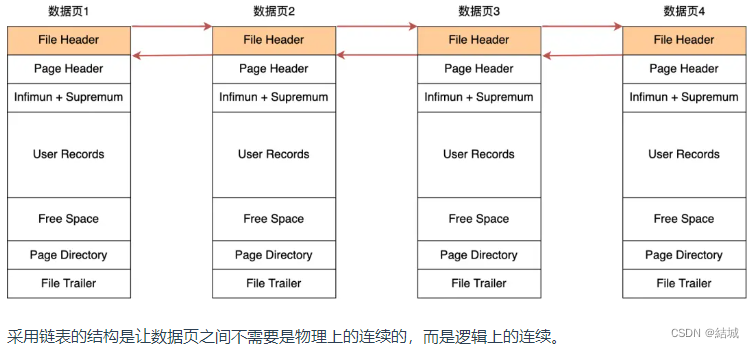
那页中有很多行数据,是怎么执行查询的呢,首先我们肯定,是以单向列表形式存储的,提高了增删的效率,但是查询效率低。所以实际上对页中的行数据进行了优化,能以二分的方式进行查询,执行这一操作的机制叫做页目录,在页的内部建立分组(包括最大和最小记录,但不包括被删除了的记录)。按照从小到大顺序排列,每组的最大的记录的头信息(file_header)存储着本组记录的数量(见粉红色字段)。页目录存储的是最后一条记录的地址偏移量(槽、slot,相当于页目录有个指针,指向每个组的最后一条记录)。所以二分就能根据每个slot的最大值判定当前查询应该去哪个分组。
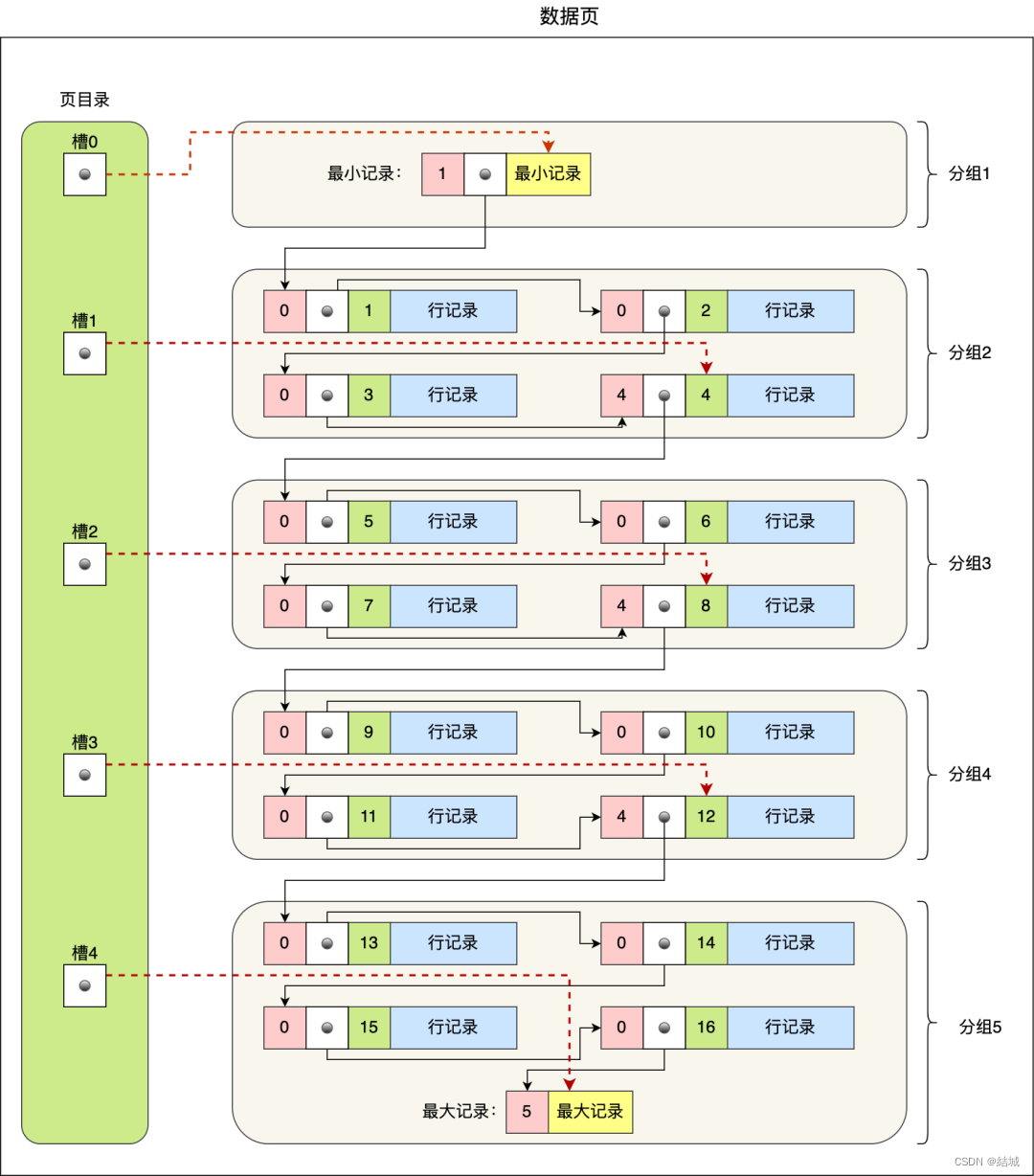
然后我们抽象到更高层次,页如何被查询的?其实B+树的每个节点都是一页,只不过非叶子节点的数据是指针。叶子节点才是真的数据。
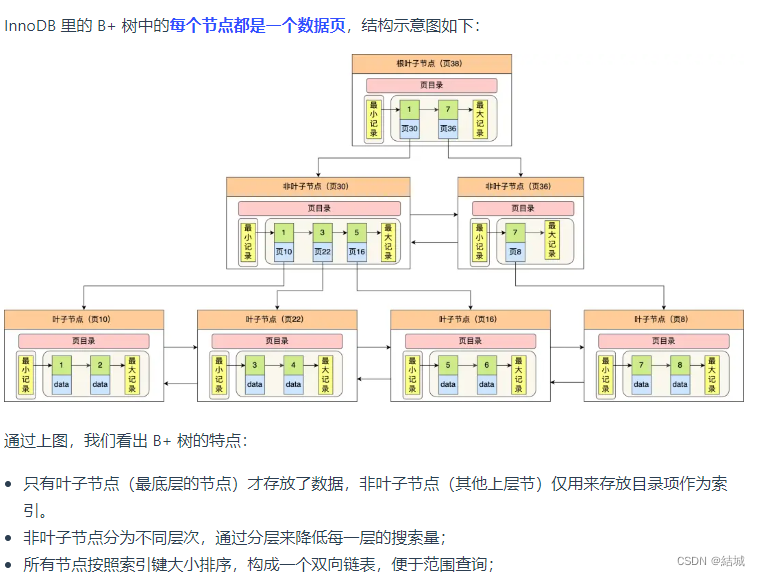
然后索引又分为聚簇索引和二级索引。
聚簇索引一般是主键索引,如果没有主键就选不包含NULL值得唯一列,如果还没有MySQL会创建一个隐藏的自增id列当作聚簇索引。聚簇索引叶子节点存的是真实数据。
二级索引就是建立的索引,叶子节点存放的是主键值,也就是说用了二级索引,查到后,还要用查到的主键值再查一遍聚簇索引才能获取数据结果,这个过程叫做回表。但假如你要查的就是主键,那就只查一次即可。
mysql中数据是如何被用B+树查询到的
news/2024/11/7 9:28:13/
相关文章


WorkPlus实现完全私有化部署,企业数据安全有保障
在这个信息化飞速发展的时代,企业正面临着越来越多的数据安全挑战。为了确保数据的安全性和隐私性,WorkPlus迎合市场需求,推出了完全私有化部署方案,为企业提供了全面、可靠的安全保障,成为企业移动办公的首选。 WorkP…
selinux-policy-default(2:2.20231119-2)软件包内容详细介绍(2)
接前一篇文章:selinux-policy-default(2:2.20231119-2)软件包内容详细介绍(1) 4. 重点文件内容解析
(1)control/postist文件
文件内容如下:
#!/bin/sh
set -e# summary of how this script can be called:
# * <postinst> `configure <most-recentl…

IO口电压下降那么多是怎么回事??
前几天一个工程师向我反馈他测得如下电路MCU IO口的电压不是3.3V,只有2V多。 IO配置的是输入功能,无上下拉。最初我不太相信这个结果,后来自己用万用表实际测量了下,还真是这个结果 这是咋回事呢?不应该电压就是3.3V吗…
YOLOv5分割训练,从数据集标注到训练一条龙解决
最近进行了分割标注,感觉非常好玩,也遇到了很多坑,来跟大家分享一下,老样子有问题评论区留言,我会的就会回答你。
第一步:准备数据集
1、安装标注软件labelme如果要在计算机视觉领域深入的同学࿰…

冷链运输车辆GPS定位及温湿度管理案例
1.项目背景
项目名称:山西冷链运输车辆GPS定位及温湿度管理案例
项目需求:随着经济发展带动物流行业快速发展,运输规模逐步扩大,集团为了适应高速发展的行业现象,物流管理系统的完善成了现阶段发展的重中之重。因此&…
精通Nginx(17)-安全管控之防暴露、限制访问、防DDos攻击、防爬虫、防非法引用
安全是每个系统都需要考虑的关键因素,Nginx在这方面提供了丰富的功能,使我们可以就实际情形做很精细调整。这些功能包括防信息暴露、客户端访问限制、通讯加密、防DDos攻击、防爬虫、防非法引用及防非法域名请求等。
目录 防信息暴露
关闭版本号
关闭目录列表
客户端访问…

SpringBoot_websocket实战
SpringBoot_websocket实战 前言1.websocket入门1.1 websocket最小化配置1.1.1 后端配置1.1.2 前端配置 1.2 websocket使用sockjs1.2.1 后端配置1.2.2 前端配置 1.3 websocket使用stomp协议1.3.1 后端配置1.3.2 前端配置 2.websocket进阶2.1 websocket与stomp有什么区别2.2 webs…