- string(字符串)
- 用法
- 使用场景
- list(列表)
- 用法
- 使用场景
- set(不可重复,乱序的集合)
- 用法
- 使用场景
- zset (相对于set集合 增加了score属性,score可用于排序)
- 用法
- 使用场景
- hash (哈希表)
- 用法
- 使用场景
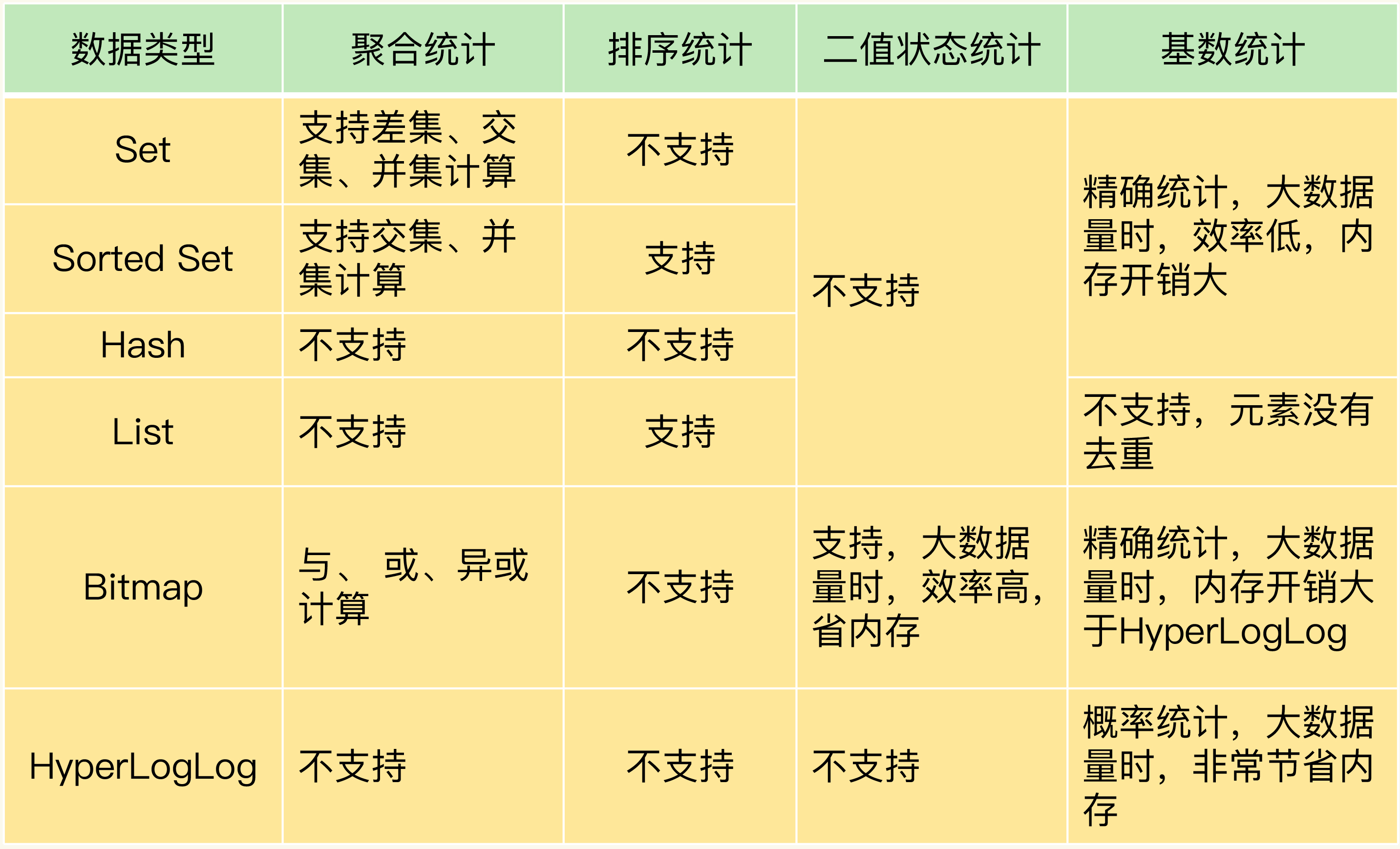
- redis统计模式
- 聚合统计
- 排序统计
- 二值状态统计
- 基数统计
string(字符串)
用法
# 给key设置value
set [key] [value]
# 根据key 获取 value
get [key]
# 根据key删除
del [key]
# 判断是否存在指定key
exists [key]
# 批量存取键值对
mset [key1] [value1] [key2] [value2]
# 根据key批量获取value
mget [key1] [key2]
# 给key设置对应的过期时间 单位:秒
expire [key] [time]
# 等价于 set + expire 命令组合
setex [key] [time] [value]
# 如果key不存在则set 创建,否则返回0
setnx [key] [value]
# 如果value为整数 可用 incr命令每次自增1
incr [key]
# 使用incrby命令对整数值 进行增加 number
incrby [key] [number]
使用场景
存储key-value键值对,可以用做缓存 使用setnx 实现分布式锁 使用 incr 命令 用作计数器 分布式系统全局序列号
list(列表)
用法
# 将一个或多个值 插入到key列表的表头(最左边)
lpush [key] [value1] [value2]
# 将一个或多个值value插入到key列表的表尾(最右边)
rpush [key] [value1] [value2]
# 移除并返回key列表的头元素
lpop [key]
# 移除并返回key列表的尾元素
rpop [key]
# 返回列表key中指定区间内的元素,区间以偏移量start和stop指定
lrange [key] start stop
# 从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout:秒,如果timeout=0,一直阻塞等待
brpop [key] timeout
# 从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout:秒,如果timeout=0,一直阻塞等待
blpop [key] timeout
使用场景
模拟分布式系统数据结构 Stack(栈) = LPUSH(左边放) + LPOP(左边取) Queue(队列)= LPUSH(左边放) + RPOP(右边取) Blocking MQ(阻塞队列)= LPUSH(左边放) + BRPOP(右边阻塞取:没有数据就阻塞!)
公众号拉取文章,微博粉丝拉取被关注人的消息 发送者使用lpush 将消息放置指定key中,接受者使用lrang key 0 5 获取最新的五条消息
set(不可重复,乱序的集合)
用法
# 在key 中插入多个元素
sadd [key] [value1] [value2]
# 指定key 删除对应value
srem [key] [value1] [value2]
# 查看指定key的集合
smembers [key]
# 查看指定key 的个数
scard [key]
# 判断member元素是否存在于集合key中
sismember [key] [value1]
# 从集合key中选出count个元素,元素不从key中删除
srandmember [key] [count]
# 从集合key中选出count个元素,元素从key中删除
spop [key] [count]
# 交集运算
sinter key [key ...]
# 将交集结果存入新集合destination中
sinterstore destination [key] [key ..]
# 并集运算
sunion key [key ..]
# 将并集结果存入新集合destination中
SUNIONSTORE destination key [key ...]
# 差集运算
SDIFF key [key ...]
# 将差集结果存入新集合destination中
SDIFFSTORE destination key [key ...]
使用场景
随机抽奖
1) 5个人点击参与抽奖加入集合
SADD lottery 1001 1002 1003 1004 1005
2) 查看参与抽奖的所有用户ID
SMEMBERS lottery
3) 抽取3名获奖者
SRANDMEMBER lottery 3 //可重复获奖,用户ID不会从集合中删除,可以参与下次抽奖
SPOP lottery 3 //不可重复获奖,用户ID从集合中删除,无法参与下次抽奖
社交软件 点赞 收藏功能
1) 用户1001给你这条消息点了个赞
SADD thumbsUp:{消息ID} 1001
2) 用户1001取消点赞
SREM thumbsUp:{消息ID} 1001
3) 检查用户1001是否点过赞
SISMEMBER thumbsUp:{消息ID} 1001
4) 获取点赞的用户列表
SMEMBERS thumbsUp:{消息ID}
5) 获取点赞用户数
SCARD thumbsUp:{消息ID}
zset (相对于set集合 增加了score属性,score可用于排序)
用法
# 增
zadd key 2 "two" 3 "three" --添加两个分数分别是 2 和 3 的两个成员
# 删
zrem key one two --删除多个成员变量,返回删除的数量
# 改
zincrby key 2 one --将成员 one 的分数增加 2,并返回该成员更新后的分数(分数改变后相应它的index也会改变)
# 查
# 返回所有成员和分数,不加WITHSCORES,只返回成员 加 WITHSCORES 多返回分数
zrange key 0 -1 WITHSCORES
# 按照元素的分值从小到大的顺序返回从start(0开始) 到stop之间的所有元素
zrange key start stop
# 倒序获取有序集合key从start下标到stop下标的元素
zrevrange key start stop [WITHSCORES]
# 获取成员 three 的分数
zscore key three
# 获取分数满足表达式 1 < score <= 2 的成员
zrangebyscore key 1 2
# 获取 key 键中成员的数量
zcard key
# 获取分数满足表达式 1 <= score <= 2 的成员的数量
zcount key 1 2
# 获取元素的排名,从小到大
zrank key member
# 获取元素的排名,从大到小
zrevrank key member
使用场景
排行榜
zadd hotNews:20190819 1 '守护香港'
1) 点击一次”守护香港“这个新闻,那么此新闻的score属性+1
incrby hotNews:20190819 1 '守护香港'
2) 展示当前热搜新闻的前10名(最后的WITHSCORES代表查询出的结果包含具体的分数)
ZREVRANGE hotNews:20190819 0 10 WITHSCORES
hash (哈希表)
用法
--增
hset key field1 "s" --若字段field1不存在,创建该键及与其关联的Hash, Hash中,key为field1 ,并设value为s ,若字段field1存在,则覆盖
hmset key field1 "hello" field2 "world" -- 一次性设置多个字段
--删
hdel key field1 --删除 key 键中字段名为 field1 的字段
del key -- 删除键
--改
hincrby key field 1 --给field的值加1
--查
hget key field1 --获取键值为 key,字段为 field1 的值
hlen key --获取key键的字段数量
hmget key field1 field2 field3 --一次性获取多个字段
hgetall key --返回 key 键的所有field值及value值
hkeys key --获取key 键中所有字段的field值
hvals key --获取 key 键中所有字段的value值
使用场景
购物车
hset cart:1001 10088 1 //给用户1001添加商品10088,数量为1
hincrby cart:1001 10088 1 //用户1001将商品10088购买数量+1
hlen cart:1001 //获得用户1001购物车商品总数
hdel cart:1001 10088 //用户1001将10088商品从购物车删除
hgetall cart:1001 //获得用户1001购物车的所有商品以及购买数量
redis统计模式
redis命令
聚合统计
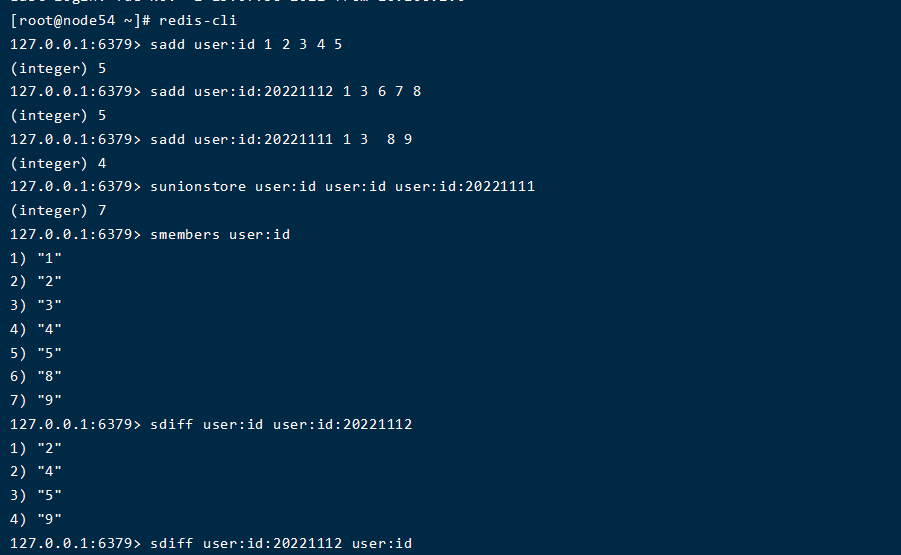
利用set集合 去重的特性,多个集合之间取交集(sinter),并集(sunion),差集(sdiff)
排序统计
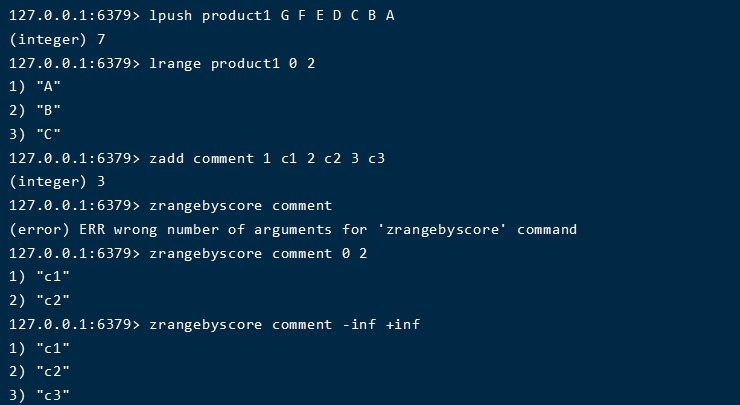
可以利用list插入时顺序来排序(lpush + lrange),或者利用sorted-set 的权重来排序 (zadd + zrangebyscore )
二值状态统计
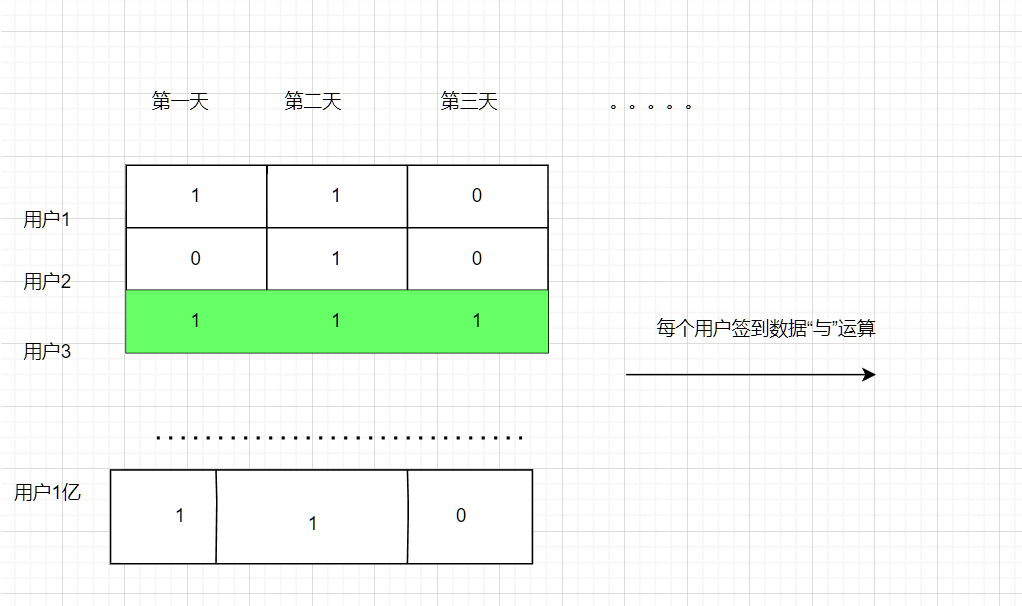
二值状态统计。这里的二值状态就是指集合元素的取值就只有 0 和 1 两种。在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态;
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态。你可以把 Bitmap 看作是一个 bit 数组。
Bitmap 支持用 BITOP 命令对多个 Bitmap 按位做“与”“或”“异或”的操作
那么,具体该怎么用 Bitmap 进行签到统计呢?我还是借助一个具体的例子来说明。
假设我们要统计 ID 3000 的用户在 2020 年 8 月份的签到情况,就可以按照下面的步骤进行操作。
第一步,执行下面的命令,记录该用户 8 月 3 号已签到。
SETBIT uid:sign:3000:202008 2 1
第二步,检查该用户 8 月 3 日是否签到。
GETBIT uid:sign:3000:202008 2
第三步,统计该用户在 8 月份的签到次数。
BITCOUNT uid:sign:3000:202008
这样,我们就知道该用户在 8 月份的签到情况了
统计一亿个用户十天内又没有连续签到
基数统计
基数统计就是指统计一个集合中不重复的元素个数
在统计uv(页面访客个数)的场景,使用set集合,hash都能达到目的,缺点就是内存消耗高。
使用HyperLogLog 可以极大降低内存的使用,缺点就是准确率会下降,标准误算率是 0.81%
HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
引用
有一亿个keys要统计,应该用哪种集合?
- END -本文由 mdnice 多平台发布