文章目录
- Foreword
- Motivation
- Method
- Query facet generation:
- Facet feedback
- Evaluation
Foreword
- This paper is from CIKM 2014, so we only consider the insights
- I have read this paper last month and today i share this blog
- There are many papers that have not been shared. More papers can be found in: ShiyuNee/Awesome-Conversation-Clarifying-Questions-for-Information-Retrieval: Papers about Conversation and Clarifying Questions (github.com)
Motivation
Extend faceted search into open-domain web setting, which we call Faceted We Search
Method
two major components in a FWS(Faceted Web Search) system:
- query facet generation
- facet feedback
Query facet generation:
Facet generation is typically performed in advance for an entire corpus, an approach which is challenging when extended to the general web
-
So, we use query facet generation to generate facets for a query
-
Extracting Candidates: as before(
Extracting Query Facets from Search Results) -
Refining Candidates: re-cluster the query facets or their facet term`s into higher quality query facets.
- topic modeling(unsupervised):
- assumption: candidate facets are generated by a mixture of hidden topics(query facets). After training, the topics are returned as query facets, by using top terms in each topic.
- apply both pLSA and LDA
- only use term co-occurence information
- QDMiner / QDM(unsupervised):
- applies a variation of the Quality Threshold clustering algorithm to cluster the candidate facets with bias towards important ones. Then it ranks/selects the facet clusters and the terms in those clusters based on TF/IDF-like scores.
- consider more information than just term co-occurence, but it’s not easy to add new features
- QF-I and QF-J (supervised): based on a graphical model
- learns how likely it is that a term in the candidate facets should be selected in the query facets, and how likely two terms are to be grouped together into a same query facet, using a rich set of features.
- based on the likelihood scores, QF-I selects the terms and clusters the selected terms into query facets, while QF-J
repeats the procedure, trying to performance joint inference.
- topic modeling(unsupervised):
Facet feedback
Re-rank the search results.
-
Boolean Filtering Model:
- condition can be AND, OR , A + O, etc.
- S(D,Q)S(D,Q)S(D,Q) is the score returned by the original retrieval model

- condition can be AND, OR , A + O, etc.
-
Soft Ranking Model(better):
-
expand the original query with feedback terms, using a linear combination as follows:

-
S(D,Q)S(D,Q)S(D,Q) is the score from the original retrieval model
-
SE(D,Fu)S_E(D,F^u)SE(D,Fu) is the expansion part which captures the relevance between the document D and feedback facet FuF_uFu, using expansion model E.
-
use original retrieval model to get document scores when the feedback terms are used as query.

or

-
-
-
the original retrieval model:
- incorporates word unigrams, adjacent word bigrams, and adjacent word proximity.
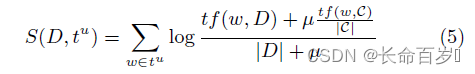
-
Evaluation
Intrinsic evaluation does not necessarily reflect the utility of the generated facets in assisting search
- some annotator-selected facets may be of little value for the search task, and some good facet terms may be missed by annotators.
We propose an extrinsic evaluation method directly measures the utility based on a FWS task
Intrinsic Evaluation:
“gold standard” query facets are constructed by human annotators and used as the ground truth to be compared with facets generated by different systems.
- Conventional clustering metrics:
Purityand Normalized Mutual InformationNMI - Newly designed metrics for facet generation: wPREα,βwPRE_{\alpha,\beta}wPREα,β, some variations of nDCGnDCGnDCG
The facet annotation is usually done by first pooling facets generated by the different systems. Then annotators are asked to group or re-group terms in the pool into preferred query facets, and to give ratings for each of them regarding how useful or important the facet is.
Extrinsic Evaluation:
Propose an extrinsic evaluation method which evaluated a system based on an interactive search task that incorporates FWS
- simulate the user feedback process based on an interaction model, using oracle feedback terms and facet terms collected from annotators.
- Both the oracle feedback and annotator feedback incrementally select all feedback terms that a user may select, which will
then be used in simulation based on the user model to determine which subset of the oracle or annotator feedback terms are selected by a user and how much time is spent giving that feedback. - Finally, the systems are evaluated by the re-ranking performance together with the estimated time cost.
Oracle and Annotator Feedback:
- Oracle feedback: presents an ideal case of facet feedback, in which only effective terms
- is cheap to obtain for any facet system
- but may be quite different from what actual users may select in a real interaction.
- So, also collect feedback terms from annotators
- Annotator feedback
User Model:
Describes how a user selects feedback terms from facets, based on which we can estimate the time cost for the user.