SparkSQL在整个执行计划处理的过程中,使用了Catalyst 优化器。
1 基于RBO的优化
在Spark 3.0 版本中,Catalyst 总共有 81 条优化规则(Rules),分成 27 组(Batches),其中有些规则会被归类到多个分组里。因此,如果不考虑规则的重复性,27 组算下来总共会有 129 个优化规则。
如果从优化效果的角度出发,这些规则可以归纳到以下 3 个范畴:
1.1 谓词下推(Predicate Pushdown)
将过滤条件的谓词逻辑都尽可能提前执行,减少下游处理的数据量。对应PushDownPredicte 优化规则,对于 Parquet、ORC 这类存储格式,结合文件注脚(Footer)中的统计信息,下推的谓词能够大幅减少数据扫描量,降低磁盘 I/O 开销。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 6g --class com.atguigu.sparktuning.PredicateTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
左外关联下推规则:左表 left join 右表
| 左表 | 右表 | |
| Join中条件(on) | 只下推右表 | 只下推右表 |
| Join后条件(where) | 两表都下推 | 两表都下推 |
注意:外关联时,过滤条件写在on与where,结果是不一样的!
1.2 列剪裁(Column Pruning)
列剪裁就是扫描数据源的时候,只读取那些与查询相关的字段。
1.3 常量替换(Constant Folding)
假设我们在年龄上加的过滤条件是 “age < 12 + 18”,Catalyst 会使用 ConstantFolding 规则,自动帮我们把条件变成 “age < 30”。再比如,我们在 select 语句中,掺杂了一些常量表达式,Catalyst 也会自动地用表达式的结果进行替换。
2 基于CBO的优化
CBO优化主要在物理计划层面,原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划。
而每个执行节点的代价,分为两个部分:
1)该执行节点对数据集的影响,即该节点输出数据集的大小与分布
2)该执行节点操作算子的代价
每个操作算子的代价相对固定,可用规则来描述。而执行节点输出数据集的大小与分布,分为两个部分:
1)初始数据集,也即原始表,其数据集的大小与分布可直接通过统计得到;
2)中间节点输出数据集的大小与分布可由其输入数据集的信息与操作本身的特点推算。
2.1 Statistics 收集
需要先执行特定的SQL语句来收集所需的表和列的统计信息。
- 生成表级别统计信息(扫表):
ANALYZE TABLE 表名 COMPUTE STATISTICS
生成sizeInBytes和rowCount。
使用ANALYZE语句收集统计信息时,无法计算非HDFS数据源的表的文件大小。
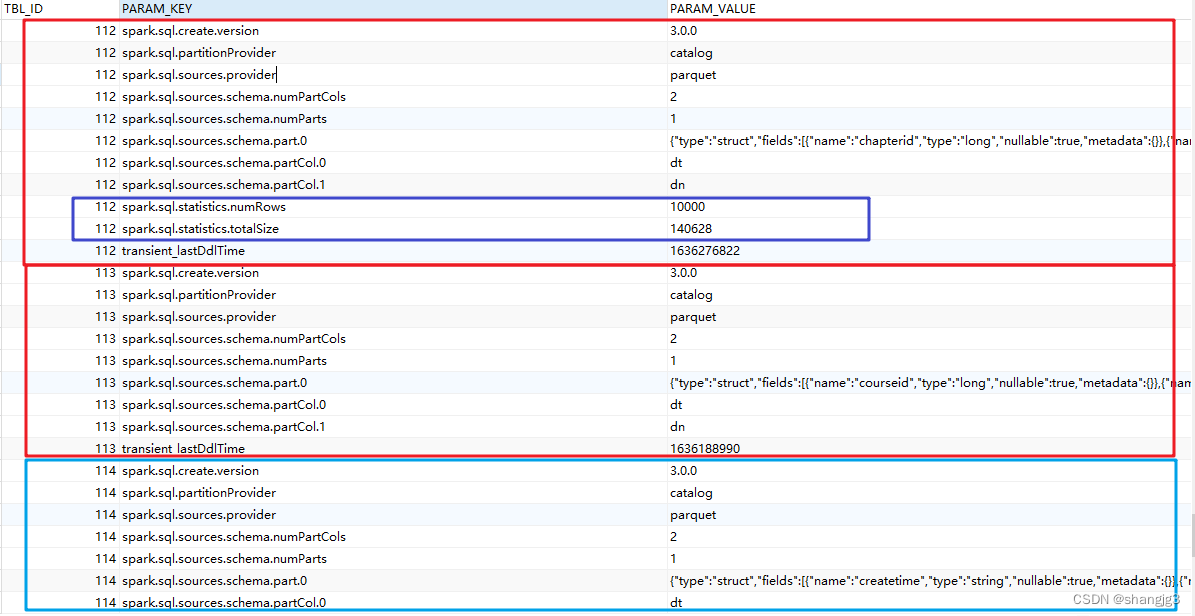
- 生成表级别统计信息(不扫表):
ANALYZE TABLE src COMPUTE STATISTICS NOSCAN
只生成sizeInBytes,如果原来已经生成过sizeInBytes和rowCount,而本次生成的sizeInBytes和原来的大小一样,则保留rowCount(若存在),否则清除rowCount。
- 生成列级别统计信息
ANALYZE TABLE 表名 COMPUTE STATISTICS FOR COLUMNS 列1,列2,列3
生成列统计信息,为保证一致性,会同步更新表统计信息。目前不支持复杂数据类型(如Seq, Map等)和HiveStringType的统计信息生成。

- 显示统计信息
DESC FORMATTED 表名
在Statistics中会显示“xxx bytes, xxx rows”分别表示表级别的统计信息。
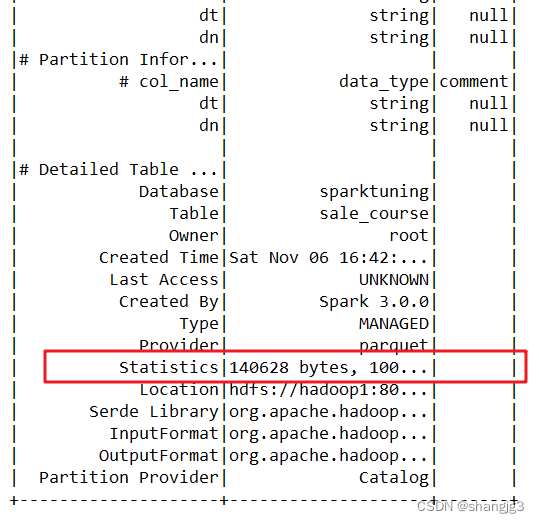
也可以通过如下命令显示列统计信息:
DESC FORMATTED 表名 列名
执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 6g --class com.atguigu.sparktuning.cbo.StaticsCollect spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2.2 使用CBO
通过 "spark.sql.cbo.enabled" 来开启,默认是false。配置开启CBO后,CBO优化器可以基于表和列的统计信息,进行一系列的估算,最终选择出最优的查询计划。比如:Build侧选择、优化 Join 类型、优化多表 Join 顺序等。
| 参数 | 描述 | 默认值 |
| spark.sql.cbo.enabled | CBO总开关。 true表示打开,false表示关闭。 要使用该功能,需确保相关表和列的统计信息已经生成。 | false |
| spark.sql.cbo.joinReorder.enabled | 使用CBO来自动调整连续的inner join的顺序。 true:表示打开,false:表示关闭 要使用该功能,需确保相关表和列的统计信息已经生成,且CBO总开关打开。 | false |
| spark.sql.cbo.joinReorder.dp.threshold | 使用CBO来自动调整连续inner join的表的个数阈值。 如果超出该阈值,则不会调整join顺序。 | 12 |
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 4g --class com.atguigu.sparktuning.cbo.CBOTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3 广播Join
Spark join策略中,如果当一张小表足够小并且可以先缓存到内存中,那么可以使用Broadcast Hash Join,其原理就是先将小表聚合到driver端,再广播到各个大表分区中,那么再次进行join的时候,就相当于大表的各自分区的数据与小表进行本地join,从而规避了shuffle。
1)通过参数指定自动广播
广播join默认值为10MB,由spark.sql.autoBroadcastJoinThreshold参数控制。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 4g --class com.atguigu.sparktuning.join.AutoBroadcastJoinTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2)强行广播
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 4g --class com.atguigu.sparktuning.join.ForceBroadcastJoinTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
4 SMB Join
SMB JOIN是sort merge bucket操作,需要进行分桶,首先会进行排序,然后根据key值合并,把相同key的数据放到同一个bucket中(按照key进行hash)。分桶的目的其实就是把大表化成小表。相同key的数据都在同一个桶中之后,再进行join操作,那么在联合的时候就会大幅度的减小无关项的扫描。
使用条件:
(1)两表进行分桶,桶的个数必须相等
(2)两边进行join时,join列=排序列=分桶列
不使用SMB Join:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.join.BigJoinDemo spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
使用SMB Join:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --class com.atguigu.sparktuning.join.SMBJoinTuning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar