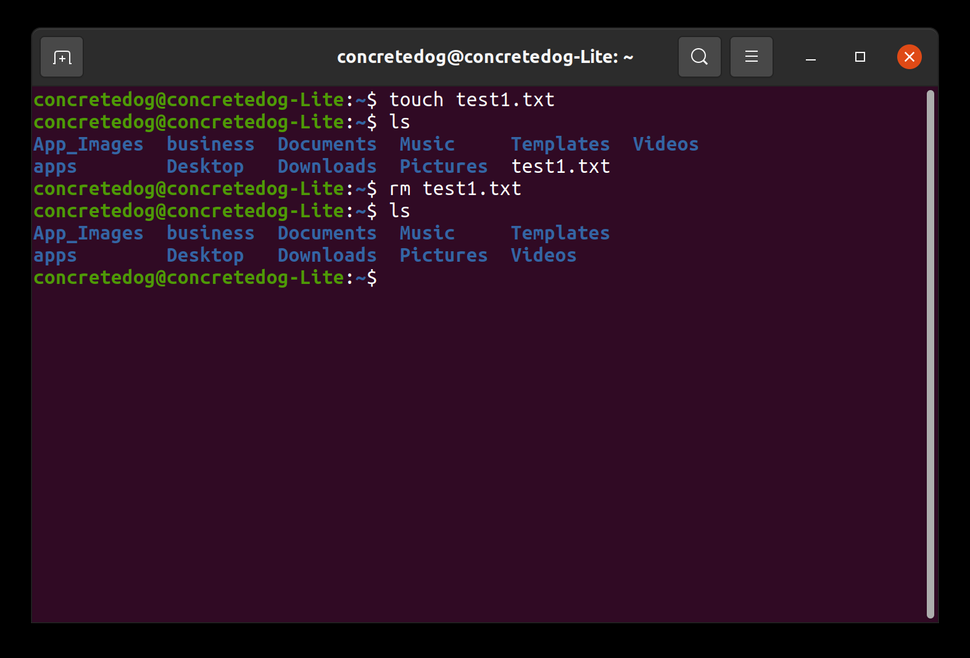
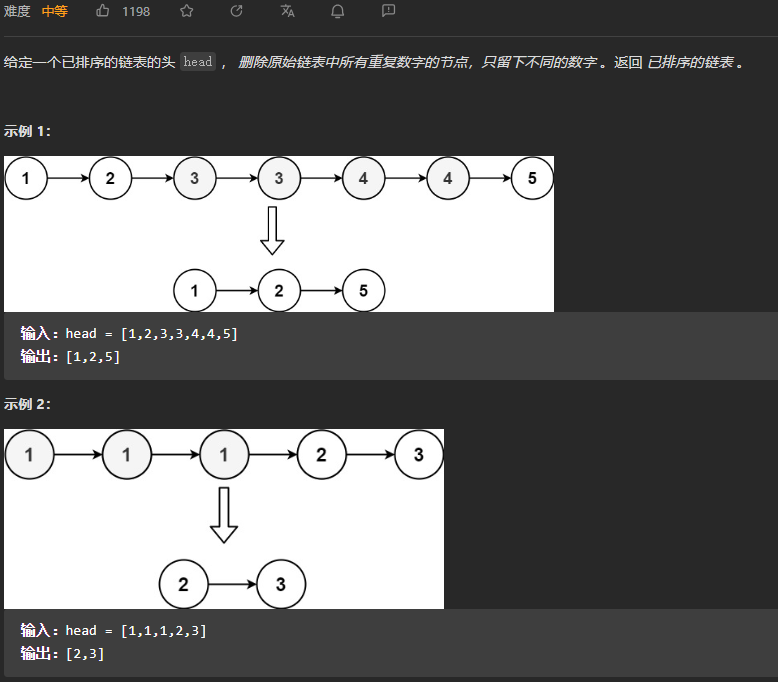
下面是提供的代码的逐行注释,以及对next数组在KMP算法中的作用的解释:
#include <iostream>
#include <vector>
using namespace std;void buildNextArray(const char* pattern, vector<int>& next) {int m = strlen(pattern); // 获取模式串的长度int j = 0;next[0] = 0; // 第一个字符的next值始终为0for (int i = 1; i < m; i++) {while (j > 0 && pattern[i] != pattern[j])j = next[j - 1]; // 回溯到前一个字符的next值if (pattern[i] == pattern[j])j++;next[i] = j;}
}int KMP(const char* text, const char* pattern) {int n = strlen(text); // 获取文本串的长度int m = strlen(pattern); // 获取模式串的长度vector<int> next(m); // 创建next数组并初始化buildNextArray(pattern, next); // 构建next数组int i = 0, j = 0;while (i < n) {if (pattern[j] == text[i]) {i++;j++;if (j == m) {return i - j; // 匹配成功,返回起始位置}} else {if (j != 0) {j = next[j - 1]; // 回溯到前一个字符的next值} else {i++;}}}return -1; // 未找到匹配
}int main() {char str[] = "bacbababadababacambabacaddababacasdsd";char ptr[] = "ababaca";int result = KMP(str, ptr);if (result != -1) {cout << "Pattern found at index " << result << endl;} else {cout << "Pattern not found in the text." << endl;}return 0;
}
next数组在KMP算法中的作用是,它保存了每个字符对应的"最长相等前缀后缀长度"。这个信息帮助算法避免在不匹配时重复比较已经匹配的部分。next数组中的值告诉算法在不匹配时应该将模式串向后滑动多远,从而最大程度地减少比较操作的次数,提高匹配效率。
算法理解
好的,下面我将用一个比喻来解释KMP算法:
想象你正在阅读一本英语书,但你的英语水平有限,只能阅读英语中的一部分文字。你希望在这本书中找到一个特定的单词,比如 “HELLO”。
Naïve Approach:
在一本书中查找单词的朴素方法是从第一页开始,逐页翻阅,每次比较一页上的文字是否与单词匹配。如果不匹配,就翻到下一页再次尝试。这个过程需要不断地翻页和比较,可能需要很长时间才能找到单词。
KMP算法:
现在,你拥有一本字典,其中列出了各种英语单词以及它们的发音。你可以在字典中查找 “HELLO”,并得到 “HELLO” 这个单词的发音。然后,你可以在书中查找一个特定单词,比如 “HELLO”,并试着匹配发音而不是文字。
现在,当你在书中找到一段文字时,你可以直接比较这段文字的发音是否与 “HELLO” 的发音相匹配,而不需要一页一页翻阅。如果不匹配,你可以使用发音字典的信息,跳过一些文字,以减少不匹配的次数。这样,你可以更快地找到 “HELLO”。
KMP算法就像使用发音字典一样,它通过预处理模式字符串(单词)来构建一个跳转表(next数组),这个表告诉你在不匹配时应该跳过多远,以减少比较的次数。这使得KMP算法能够更高效地在文本中查找模式,特别是当模式很长时。
下面是你提供的代码,并在需要的地方填上合适的代码,同时提供相关的解释:
class Invoice {public void printInvoice() {System.out.println("This is the content of the invoice!");}
}class Decorator extends Invoice {protected Invoice ticket;public Decorator(Invoice t) {ticket = t;}public void printInvoice() {if (ticket != null) {ticket.printInvoice(); // (1) 调用包装的发票对象的打印方法}}
}class HeadDecorator extends Decorator {public HeadDecorator(Invoice t) {super(t);}public void printInvoice() {System.out.println("This is the header of the invoice!");super.printInvoice(); // (2) 调用父类的打印方法,以便在头部之后继续打印}
}class FootDecorator extends Decorator {public FootDecorator(Invoice t) {super(t);}public void printInvoice() {super.printInvoice(); // (3) 调用父类的打印方法,以便在底部之前继续打印System.out.println("This is the footnote of the invoice!");}
}public class Test {public static void main(String[] args) {Invoice t = new Invoice();Invoice ticket;// (4) 创建一个嵌套的装饰器链:头部 -> 原始发票 -> 底部ticket = new FootDecorator(new HeadDecorator(t));ticket.printInvoice(); // 输出装饰的结果System.out.println("------------------");// (5) 创建另一个嵌套的装饰器链:头部 -> 原始发票 -> 底部ticket = new HeadDecorator(new FootDecorator(t));ticket.printInvoice(); // 输出不同顺序的装饰结果}
}
逐行解释:
-
ticket.printInvoice();在Decorator类的printInvoice方法中,调用包装的发票对象的打印方法,以实现在原始发票内容之上添加额外的内容。 -
super.printInvoice();在HeadDecorator类的printInvoice方法中,调用父类的打印方法,以便在头部之后继续打印原始发票内容。 -
super.printInvoice();在FootDecorator类的printInvoice方法中,调用父类的打印方法,以便在底部之前继续打印原始发票内容。 -
创建一个嵌套的装饰器链,先添加底部装饰器,然后再添加头部装饰器,最后包装了原始的
t发票对象,以实现底部内容、原始内容和头部内容的顺序。 -
创建另一个嵌套的装饰器链,先添加头部装饰器,然后再添加底部装饰器,不同于第一个链的顺序。
这样,装饰模式允许以不同的顺序组合装饰器,以实现不同的打印顺序和输出结果。