中国在AI for Science的基础还非常的薄弱,且非短期内可以提升,需要有一个长期性的计划,也需要有足够的金钱投入和人才队伍建设。
本篇作者褚学森,中国船舶科学研究中心、深海技术科学太湖实验室 研究员;新兴技术研究室AI方向牵头人;AICA首席AI架构师培养计划第四期学员。在今天的「AI先行者」分享中,他将和大家聊聊自己对于AI for Science的理解和感悟。
中国船舶科学研究中心、深海技术科学太湖实验室,是赫赫有名的“蛟龙号”、“奋斗者号”的研发单位。我从大学毕业加入至今已快20年,目前在新兴技术研究室担任AI方向牵头人。结合近几年在AI for Science科研前沿领域的探索,分享一些个人的观察和思考,希望帮助中国AI产业应用走得更快些。

中国AI发展不能“偏科”
我在2021年参加了深度学习技术及应用国家工程研究中心联合百度举办的AICA首席AI架构师第四期的培训,可谓眼界大开。课程覆盖面广,授课老师都是一线大拿,唯一的遗憾是授课的时间比较短,对我们深入了解和学习还是不够,希望将来有更深度、更长时间的学习。
我们搞船舶的,具体说是用超级计算机搞仿真模拟,在AICA学员中会感到有一点点“寂寞”,有类似感觉的,可能还有搞石油的、搞海洋监测的。
因为我看到90%的学员都是集中在CV(计算机视觉)和NLP(自然语言处理)方向,而像我们这样的研究所,比较集中在AI for Science和AI for Product两大类。前者,是通过AI提升科研技术手段创新,如提升试验手段、实验能力、仿真能力等;后者是通过AI实现产品智能化,如智能船舶、无人船自动驾驶、辅助决策,这些方面我们都已经有了一些积累。
我必须坦率地说,如果百度在通用AI的实践上代表中国的最高水平的话, 那反映出一个现状就是,中国在AI for Science的基础还非常的薄弱,且非短期内可以提升,需要有一个长期性的计划,也需要有足够的金钱投入和人才队伍建设。

 生成式大模型
生成式大模型
一半海水一半火焰
我当时AICA培训结业的时候,ChatGPT这波还没有起来,现在非常热,我也专门讲一下我的一些感受。
对于普通人来说,ChatGPT似乎是一夜之间冒出来的,改变了游戏规则。但事实上不是的,它依托的深度学习和大模型的技术底座一直有在发展,只是因为正好这一次和chat模式结合,使得普通人能够用自然语言去体验AI的能力和魅力,它就一夜成名了。这让我不由感概,很多大事看似由一个细节或偶然推动的,但背后有其必然。
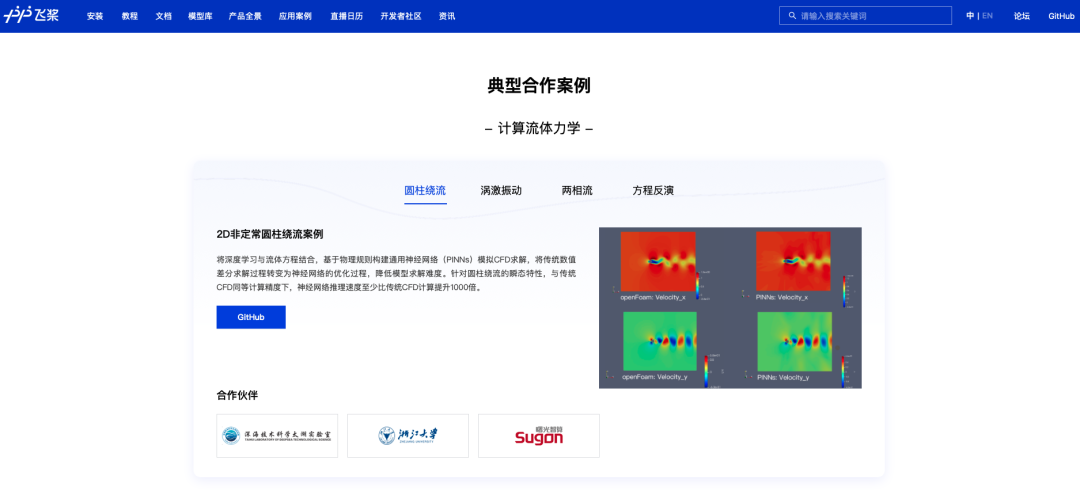
飞桨科学计算
对于生成式大模型的能力,我第一时间体验了。如果要打个比喻,它的出现有点像当年智能手机颠覆功能手机,是很多要素综合的结果,例如从按键变成触摸屏、从3G进入4G、开放的操作系统、大量自由开发者应用涌现等等。
但这些因素中谁是主因呢?我觉得是“智能操作系统”,智能操作系统提供了手机应用可随意扩展和万众参与开发的技术底座,改变了手机生态,ChatGPT带来的也是操作系统级的变化,它打开了普通人与智能大模型的交互大门,也证实了通用人工智能的可行性。
我对ChatGPT的体验主要是“文科”方面的。我也体验了很多大模型,特别是百度的文心一言,可以说是国内最好的。我认为,如果有人专攻和科研结合的生成式能力,比如论文的检索、查询、提炼、写作辅助,再比如工作协同、图片生成等领域,应该是比较快的能产生一些成果的,所以它很热。
但也有冷的一面,我必须强调的是,目前我学习和在工作中应用AI已经快5年的时间了,我的一个比较朴素的判断是,无论是以前的大模型,还是现在这一波生成式浪潮,短期内还不会出现特别适应于我们船舶行业的通用深度学习算法和模型。
因为通用版的AI工具还无法处理特定的工程问题,不同的应用模式,需要不同的机器学习算法和针对特定问题的进一步细化,比如要做流体力学的方向,尽管有了一些尝试性案例,但我觉得它们还过于简单,要真正应用到工程,必须有真正深入我们这个行业的人一起才能做出来的。所以最后,我们这个AI组,还是要做很多通用化之外的行业二次开发,不然就解决不了具体的困难。
当然,短期内不能,不代表以后不能。我相信随着我们对AI领域的持续深耕,也会有持续的突破。
其实,我们已经开始走在这条路上了,比如有一个重点方向——“船舶知识大脑”,就是基于知识图谱和大模型。通过学习我们也了解到,百度的文心大模型 和其背后的知识图谱、知识增强等技术密不可分。我们相信继续深入了解百度“文心+飞桨”的产业实践,对提升我们在知识领域的能力会是非常有借鉴作用的,我们也希望持续和百度在这方面保持合作和探索上的协作。
 要继续马拉松式的投入
要继续马拉松式的投入
我已经工作20年了,但还在攻读清华大学的计算机工程博士学位,因为虽然我们的行业如计算流体很多年前就开始应用计算机,后面用了很多年的超算,但行业内主流方法还是比较古老的。如果说的具体一点,它是在上个世纪70年代的时候发展起来的,针对的是当时数据少、算力也很薄弱的状态,用有限的条件得到一个比较宏观的最优解,这样的算法不是专门针对当前大数据、高算力情形设计,无法有效拓展。
但是,现在的算法、算力和方法论体系都有了巨大进步,我们不能再用上个世纪的体系,这可能也是单位将AI作为一个方向建设,并且让我来牵头的缘故。
在我看来,AI for Science非常有前途,它不是一个应用或一个算法,它是从科学的最底层规律出发,让bottom up的纯数据驱动方式,逐渐转向与物理模型相融合的阶段。
说的再通俗一点,我从事的是AI for CFD方面的攻关,属于科学智能的范畴。就是用AI去学习科学原理,然后得到模型,进而去解决实际的问题。比如,AlphaFold2对蛋白质折叠结构的预测,为这个困扰生物学界 50 余年的难题提供了革命性手段。
从这个角度去看,AI for Science在国际上已经如火如荼的搞起来了,国际上较领先的是DeepMind和Nvidia等。但坦率来说他们目前也还处于人才培育阶段,少部分有代表性的国际成功案例,没到适用大规模商业应用程度,还是以不惜代价的资金投入做出来的。
但尽管如此,人家并没有因为短期效益不明显而减少支持,ChatGPT出来之前,也没人说得清OpenAI坚持的大模型是否值得投入。这也提醒我们,尖端科研的过程就是你追我赶,现在我们不占有优势,如果没有持续投入的决心,就会落后。
举个例子,戈登贝尔奖是高性能计算领域的诺贝尔奖,2016 年、2017年都是我国拿到的戈登贝尔奖,2018年是两个美国团队拿到的奖,他们的成就都是基于当时世界排名第一的Summit系统上,那里面很多应用都已经是面向人工智能的;后来尤其像DeepMind,每年都会出类似AI爆品的东西,整个科学界对AI 活跃度就带上来了,这值得我们关注。
AI的顶级研发非常非常的花钱,我们需要集中力量办大事。当百度2021年开始设计飞桨科学计算套件PaddleScience(赛桨),布局AI for Science生态,我们第一时间参与了相关共建开发工作,支撑完成了基于PINNs方法的方腔流、圆柱绕流等应用案例,为PaddleScience的1.0版发布奠定了基础。合作过程双方都是自愿投入,后来我们和百度一起申请一个国家级别的基金,结果过会的时候就被pass掉了。否掉的原因不是说项目不好,而是评审者认为,你和企业合作,企业就会有投入啊,为什么还要来跟那么多嗷嗷待哺的项目抢基金。
这是一个很典型的现象,我们国家用在AI底层研发、AI for Science、包括工业软件方面投入了很多经费,但是各个口子都在做,有点雨露均沾的味道,彼此之间又有很大的隔阂,没有真正做到力往一处使,真正发挥举国体制的优势。当然,二十大提出了创新总方针,很多问题会在以后被重视起来,但我觉得我们要消融来自社会各界的研究机构、高科技公司、高校之间的“隐形”的墙,真正做到力出一孔,这恐怕是一个长期的问题。以百度这样的高科技公司主导开源模式,共建生态,不失为一个有效途径。
 中国造船工业如何应对“卡脖子”
中国造船工业如何应对“卡脖子”
应对各类“卡脖子”是我们国家近年科技发展的焦点,我们船舶行业也要应对可能的“卡脖子”问题。工业软件就是其中一种。
你可能认为怎么会?毕竟,2022年1-10月,我国造船业在国际市场的份额继续稳居世界第一,在全球18种主要船型分类中,我国有10种船型新接订单量位居世界第一。目前,全球建造难度最高的液化天然气船,我国承接的数量已提升至全球的近三成,创历史最高水平。
但你可能不知道,从事我们这个行业,必须使用工业软件,CFD软件是其中一种,CFD英语全称 (Computational Fluid Dynamics),即计算流体动力学,它是流体力学、计算数学和计算机科学结合的产物,是一门具有强大生命力的交叉科学。CFD软件通常指商业化的CFD程序,具有良好的人机交互界面,能够让使用者无需精通CFD相关理论就能够解决实际问题。这些软件从基本物理定理出发,在很大程度上替代了耗资巨大的流体动力学实验设备,在科学研究和工程技术中产生巨大的影响,是目前国际上一个强有力的研究领域。
而目前几乎所有主流的CFD软件都是在欧美国家手里,包括英国的CFX和美国的Fluent, 后来CFX和Fluent都被ANSYS公司收购,成为其ANSYS系列产品下的流体模块。
类似于“我不用你的芯片设计软件,就无法又快又好的设计出芯片”这样的问题,完全可能在我们这个行业再发生一次。

而我们除了迎头赶上,也要弯道超车,现在,有AI的加入,给CFD的弯道超车提供了可能。人工智能在很多方面有优势,比如通过在更快的周转时间内为每个仿真创建更多设计,从而降低计算、设计程序和运营成本。
又比如,通过在CFD过程中自动调参和提供知识库工作流帮助来提高模拟的准确性,以及创建生态系统以无缝方式模拟、预测和优化产品,提高产品性能和效率等等。
人工智能与CFD的结合说起来很深,我只择要说一点。目前这个领域有纯数据驱动和结合先验知识两类。纯数据驱动方法是由已有的CV等其他领域方法迁移过来,这类方法最大难处在于大量的数据样本获取和训练。而融合传统的方法及其他先验知识到神经网络训练中,可以有效降低对数据的需求,这是我们现在跟百度飞桨一起合作,在攻关的方向,但难度非常大。
这让我很感概,还是力量不够集中。百度作为一个通用型AI企业,已经进入AI世界的领导者象限,这是很值得骄傲的事情。但百度再强,也没法替所有的行业分门别类的去搞专用算法。在我看来,百度是一个引领者的角色,但我们行业也要和百度互相奔赴,我们要输出我们的know-how做百度的“带路党”,我们也需要百度的工程师真正在我们领域待一两年,我们还需要充裕的资金和开放的环境, 如果这些都具备,我觉得以中国人的智慧,是能够作出一点不同凡响的事情来的。
结语
说了这么多,才深切的感到,越是本身技术壁垒高的行业,通用型AI企业的赋能难度就越大。这个问题会困扰整个AI行业很多年,而在我看来,唯一的破解之道,就是培养跨界人才。
我记得一个故事,说有人采访爱因斯坦,提了一个问题,说为什么牛顿经典力学现在还是主流。爱因斯坦回答说,只有等那些从小就把相对论当基础常识来学习的人成长起来了,门户之见也就自然消失了。
在这里我们也可以期待,完全从基础教育开始就学习AI的这批人成长起来,会给这个世界带来什么样的变化。
相关链接
点击下方链接或阅读原文,即刻报名了解百度AICA首席AI架构师培养计划第八期。
百度 AICA 首席 AI 架构师培养计划第八期





关注【飞桨PaddlePaddle】公众号
获取更多技术内容~