| Year | Name | Area | model | description | drawback |
|---|---|---|---|---|---|
| 2021 ICML | Clip (Contrastive Language-Image Pre-training) | contrastive learning、zero-shot learing、mutimodel |  | 用文本作为监督信号来训练可迁移的视觉模型 | CLIP’s zero-shot performance, although comparable to supervised ResNet50, is not yet SOTA, and the authors estimate that to achieve SOTA, CLIP would need to add 1000x more computation, which is unimaginable;CLIP’s zero-shot performs poorly on certain datasets, such as fine-grained classification, abstraction tasks, etc; CLIP performs robustly on natural distribution drift, but still suffers from out-of-domain generalisation, i.e., if the distribution of the test dataset differs significantly from the training set, CLIP will perform poorly; CLIP does not address the data inefficiency challenges of deep learning, and training CLIP requires a large amount of data; |
| 2021 ICLR | ViT (VisionTransformer) |  | 将Transformer应用到vision中:simple, efficient,scalable | 当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果 | |
| 2022 | DALL-E | 基于文本来生成模型 | |||
| 2021 ICCV | Swin Transformer |  | 使用滑窗和层级式的结构,解决transformer计算量大的问题;披着Transformer皮的CNN | ||
| 2021 | MAE(Masked Autoencoders) | self-supervised |  | CV版的bert | scalablel;very high-capacity models that generalize well |
| TransMed: Transformers Advance Multi-modal Medical Image Classification |  | ||||
| I3D | |||||
| 2021 | Pathway | ||||
| 2021 ICML | VILT | 视觉文本多模态Transformer | 性能不高 推理时间快 训练时间特别慢 | ||
| ALBef | align before fusion 为了清理noisy data 提出用一个momentum model生成pseudo target |
CV论文阅读大合集
news/2024/11/8 18:05:57/
相关文章

【漏洞复现】锐捷RG-EW1200G登录绕过
漏洞描述 免责声明
技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和利益,未经授权请勿利用文章中的技术资料对任何计算机系统进行入侵操作…

数据库的事务四大特性(ACID)、详解隔离性以及隔离级别、锁
文章目录 🎉数据库的事务四大特性(ACID)以及隔离性一、事务的四大特性✨1、原子性(Atomicity)🎊2、一致性(Consistency)🎊3、隔离性(Isolation)&a…
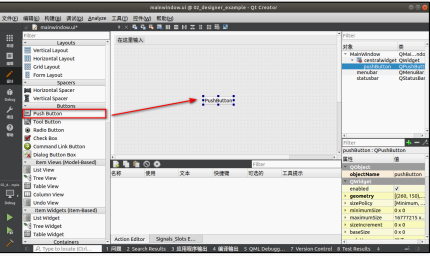
基于Qt Designer 操作教程
本章将简介使用 Qt Creator 里自带的 Qt Designer,使用 Qt Designer 比较方便的构造 UI 界面。特点是方便布局,比较形象。
## 使用 UI 设计器开发程序
在这小节里我们继续学习如何使用 Qt Designer 开发程序,Qt Designer 是属于 Qt Creator 的一个功能而已,大家不要搞混…


【Effective Modern C++】条款24:区分万能引用和右值引用
条款24:区分万能引用和右值引用
万能引用既可以是左值引用,也可以是右值引用。
一、模板中的万能引用
要求:T && 类型推导。
template<typename T>
void f(T &¶m); // param是一个万能引用template<type…

【送书福利-第二十三期】《从零基础到精通Flutter开发》
😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主、前后端开发、人工智能研究生。公粽号:程序员洲洲。 🎈 本文专栏:本文…
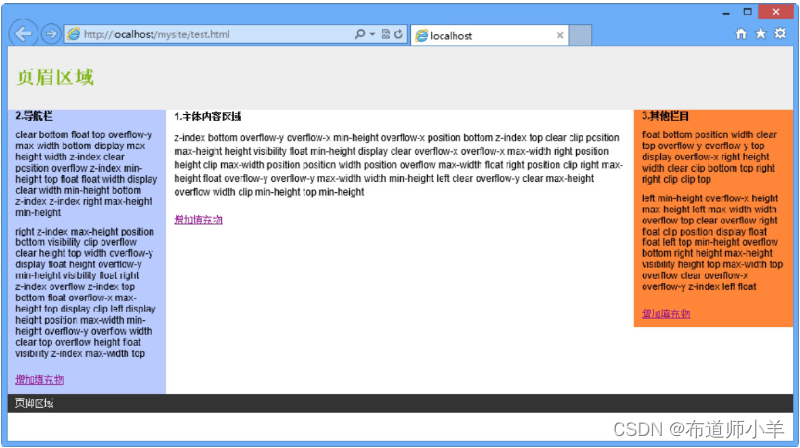
CSS3网页布局基础
CSS布局始于第2个版本,CSS 2.1把布局分为3种模型:常规流、浮动、绝对定位。CSS 3推出更多布局方案:多列布局、弹性盒、模板层、网格定位、网格层、浮动盒等。本章重点介绍CSS 2.1标准的3种布局模型,它们获得所有浏览器的全面、一致…
onnx 模型加密与解密部署运行
1.这里主要介绍onnx在c环境下的加密和解密部署。一般的onnx文件加载方式在onnxruntime下是: env Ort::Env(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING, "YOLOV8");sessionOptions Ort::SessionOptions();std::wstring w_modelPath charToWstring(mnnModelPath.c…