第 5 节 基本数据处理 · 基本统计
学习了如何对 JavaScript 中的数组数据进行操作之后,我们就要回到刚开始选择购买这本小册的目的了:使用 JavaScript 开发灵活的数据应用。既然说是数据应用,那么便离不开统计计算,而数组就可以说是统计计算中的“第一要素”。
5.1 基本统计方法
我们经常能在各种地方听到这样的词语“平均”、“绝大部分”、“百分之三十”,这些都可以在统计学中找到对应的东西。比如“平均”就是平均值,或更专业的“数学期望值”,而“绝大部分”对应的就是“众数”。这些我们都可以将它们统称为数列的数学特征值。
5.1.1 平均值
如果没有学习过概率论的话,就可能会对平均值和数学期望值之间的关系和区别有所疑惑,那么我们这里就可以先简单地补一课。
数学期望值指的是在概率论中,一个数值集合总体中各种可能性的结合。举一个“栗子”,一个袋子中装有若干来自我国北方的板栗,以及若干来自我国南方的锥栗。那么经过无限次取出、记录并放回之后,我们可以假设计板栗为 -1,计锥栗为 1,经过简单的统计计算得出取出样本中板栗的概率 PαPα 为 3553,而锥栗的概率 PβPβ 为 2552。
| 值 | 板栗(-1) | 锥栗(1) |
|---|---|---|
| 概率 PP | 3553 | 2552 |
根据数学期望的计算公式可得,该袋子中栗子的期望值为 -15-51。
? E=\text{-}1\times\frac{3}{5}+1\times\frac{2}{5}=\text{-}\frac{1}{5} ?
那么如果说我们假设这“无限次”的取出就是 5 次的话,就可以用这样的一个数组来表达记录的结果:[ -1, 1, -1, -1, 1 ],其中板栗 3 次,锥栗 2 次。使用我们以往学习平均数的计算方法来计算的话就是。
? m=\frac{\text{-}1+1+\text{-}1+\text{-}1+1}{5}=\text{-}\frac{1}{5} ?
可以发现其实数学期望值的计算方法和平均值的计算方法是非常相似的。不过从数学概念上,平均数是指在有限的样本空间内对样本的平均数值,而数学期望值是指总体空间中各种可能性(比如在这个“栗子”中的板栗和锥栗)的可能性结合。
扯了那么远,其实我们会发现在 JavaScript 中,我们使用 Lodash 来实现平均值的计算是那么的简单。
const array = [ 1, 2, 3, 4, 5 ]const mean = _.mean(array)console.log(mean) //=> 3
结合转换聚合的概念,我们来计算前面 4.1.4 节中部门人员数据的人员平均年龄。
const crew = [{name: 'Peter',gender: 'male',level: 'Product Manager',age: 32},{name: 'Ben',gender: 'male',level: 'Senior Developer',age: 28},{name: 'Jean',gender: 'female',level: 'Senior Developer',age: 26},{name: 'Chang',gender: 'male',level: 'Developer',age: 23},{name: 'Siva',gender: 'female',level: 'Quality Assurance',age: 25}
]const ages = _.map(crew, function(person) {return person.age
})
const meanAge = _.mean(ages)console.log(meanAge) //=> 26.8
当然 Lodash 还提供了更为简单的函数来应对这样的数组计算。
const meanAge = _.meanBy(crew, 'age')// 或者const meanAge = _.meanBy(crew, function(person) {return person.age
})
5.1.2 众数
除了平均数以外,我们最常用到的数学特征值恐怕就要数众数了,因为我们常常希望知道在一个群体中的最大多数是什么。而这就意味着众数并不代表只能用在数值数列上,也可以用于其他可以对比相同的元素上,比如字符串。
虽然说在众数计算中,除了先计算出所有可能性的频次以外,还可以使用摩尔投票算法(Boyer–Moore majority vote algorithm)。而摩尔投票算法的前提是数列中绝对存在一个频次最高的元素,即主要元素(Majority Element)。摩尔投票算法的好处是相比于使用哈希(Hash、Map、Object等)进行频次统计经典方法的非线性时空复杂度,摩尔投票算法有非常良好的 O(n) 时间复杂度和 O(1) 的空间复杂度。但由于在很多情况下我们并不仅仅是想要单一的一个众数,而是想要“频次出现最多的若干个情况”,所以我们这里暂不会对这种算法进行介绍。
而既然我们需要使用最经典的逐一计算每种可能性的频次,那么就让我们再次回到第 2 节中我们提出的词频统计吧。
5.1.3 词频统计
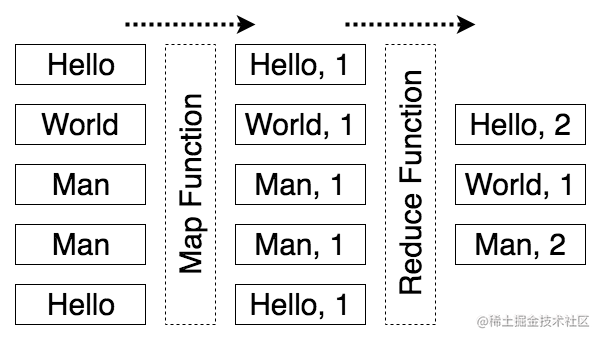
一般来对数组中的各种可能性进行频次统计,是先创建一个用于记录频次的对象,然后通过遍历数组中的每一个元素,并将其一个一个放入到前面创建的对象中以记录频次。但是自从我们学会了使用 Map 和 Reduce 开始我们就可以使用更直观的方式进行统计。
首先把每一个词使用变换函数将其变成一个以单词为第一元素,以 1 为第二元素的数组,我们可以将其称为 Tuple,相当于对象中的一个键值对。
"hello" -> [ "hello", 1 ]
既然我们将单词转换成了多个 Tuple 键值对的键,那么我们是不是可以使用这个特性更方便地进行 Reduce 呢?是的,我们可以将其称为 reduceByKey。在一般情况下的 Reduce 函数是用于遍历整个数组的,而 reduceByKey 则是根据 Tuple 集中的键首先进行一次分类组合,将具有相同键的值进行组合,然后对每一个组合集进行单独遍历。
不幸的是,无论是原生 JavaScript 中还是 Lodash 中并没有这样的 API。但是我们却可以使用 Lodash 的函数进行组合,对 Lodash 进行拓展。
_.reduceByKey = function(tuples, reduceCallback) {const grouped = _.groupBy(tuples, function(tuple) {return tuple[0]})return _.toPairs(_.mapValues(grouped, function(tuples) {return _.chain(tuples).map(function(tuple) {return tuple[1]}).reduce(reduceCallback).value()}))
}
我们在第 2 节中通过使用正则表达式将 MIT 开源协议中的一部分内容进行了数据清洗和分割。
const originalText = 'Permission is hereby granted, ...'const words = originalText.toLowerCase().match(/\w+/g)
那么我们按照 Map 和 Reduce 的思路进行一下词频统计,首先将单词字符串转换为 Tuple,然后再使用 reduceByKey 进行聚合统计。
const tuples = words.map(function(word) {return [ word, 1 ]
})const wordCountResult = _.reduceByKey(tuples, function(left, right) {return left + right
})console.log(wordCountResult) //=> [["permission", 2], ["is", 4], ["hereby", 1], ["granted", 1], ["free", 1], …]
现在我们有了一个统计了不同单词在 MIT 开源协议中频次的统计结果,接下来让我们继续进行下一步操作。
5.1.4 排序
既然我们已经对不同的单词频次进行了统计,那么我们应该要知道哪些单词出现次数最多,哪些出现最少吧?所以我们需要对上面的统计结果按照频次从大到小或从小到大排序。
排序算法有非常多种,但是这并不在我们的讨论范围内,如果感兴趣的话,可以参考 Wikipedia 中的排序算法页面。
我们可以直接使用 JavaScript 中的 array.sort 方法进行简单的排序。
array.sort 方法需要传入一个回调函数,这个回调函数是用于比对两个元素,以确定两者之间的排序。而在这过程中也可以将元素中真正需要用于排序的“元素”取出,也可以先将元素进行转换。比如本小册 4.1.4 小节中的 crew 数组中的 age 是用于排序部门人员年龄大小的元素。而这里则是每一个 Tuple 中的值,也就是数组的第二元素。
const sorted = wordCountResult.sort(function(leftTuple, rightTuple) {return rightTuple[1] - leftTuple[1]
})console.log(sorted) //=> [["the", 14], ["or", 9], ["software", 9], ["of", 8], ["to", 8], …]
5.1.5 裁剪
有了排序之后的统计结果,我们就可以从中取出一部分用于展示统计结果了,比如“频次最多的 5 个单词”和“频次最少的 5 个单词”等。
这里我们可以用到 JavaScript 原生的 array.slice,正如这个方法的字面意思那样,这个方法的用途就是对数组进行切片,比如前 5 个元素的切片、后 5 个元素的切片和中间某个范围的切片等。
比如我们需要知道词频统计结果中,频次最多的 5个单词是哪些。那么我们就可以对已经经过从大到小排序的统计结果中,选取前 5 个元素的切片。
const top5 = sorted.slice(0, 5)
array.slice 方法传入两个参数,一个是目标切片的起始位置,一个是结束位置。选取前 5 个元素也就是选取从下边为 0 的元素开始到下标为 5 的前一个元素结束。是不是觉得很复杂?那我们可以选择使用 Lodash 提供的 _.take 函数。
_.take 函数除了第一个参数为被处理数组外,还接受一个参数为个数 n,也就是该函数会返回数组中前 n 个元素的切片。
const top5 = _.take(sorted, 5).map(function(tuple) {return tuple[0]
})console.log(top5) //=> ["the", "software", "or", "to", "of"]
而如果需要知道出现频次最少的 5 个单词,那就取统计结果的后 5 个元素即可。而 Lodash 同样提供了一个 _.takeRight 函数,用于从数组的右端(也就是末端)开始选取元素。
const minimal5 = _.takeRight(sorted, 5)console.log(minimal5) //=> [["from", 1], ["out", 1], ["connection", 1], ["with", 1], ["above", 1]]
小结
在学会了如何使用数组存储和操作数据之后,在本节中我们学会了如何使用一些基本的数学和统计知识来对数组中的元素进行基本的运算。非常好,我们要保持好这样的学习节奏。
到此我们已经完成了 JavaScript 中基本数据结构及其基本处理方法的学习,接下来我们正式要开始学习较为复杂的数据处理、数据可视化以及动态数据应用的开发了,你准备好了吗?
习题
- 设某次投票结果为如下
[ 1, 2, 3, 2, 2, 3, 1, 4, 4, 1, 2, 1, 1, 3, 4 ],请统计投票结果并找出票数最多的选项; - 假设某一时间记录软件记录下一个人一天 24 小时中每一个小时的工作状态,其中分别以范围为 1 ~ 8 的自然数标识,1 为生产力最差的程度,而 8 则为生产力最佳的状态。而该软件记录了某人一天的数据为
[ 1, 1, 1, 1, 1, 1, 1, 1, 6, 7, 8, 4, 3, 7, 8, 8, 6, 6, 4, 3, 3, 3, 1, 1 ]。假设区间 1 ~ 3 为生产力较低,4 ~ 5 为生产力一般,6 ~ 8 为生产力较高。请统计并分析这份数据中一天的工作状态。
视频链接:
基于 JavaScript 开发灵活的数据应用 - 小问iwillwen - 掘金小册使用 JavaScript、ECharts、Vue.js 等开发工具,完成各种数据结构的处理、转换、动态过滤以及数据可视化的开发。。「基于 JavaScript 开发灵活的数据应用」由小问iwillwen撰写,2412人购买![]() https://s.juejin.cn/ds/kuJRw4W/
https://s.juejin.cn/ds/kuJRw4W/