文章目录
- 延时队列简介
- 应用场景
- 案例:
- 考虑:
- 实现:
- 整体思路:
- 具体实现
- 生产者
- 消费者
- 运行结果
- redis分布式延时队列优势
- redis分布式延时队列劣势
延时队列简介
延时队列是一种特殊的消息队列,它允许将消息在一定的延迟时间后再进行消费。延时队列的主要特点是可以延迟消息的处理时间,以满足定时任务或者定时事件的需求。
总之,延时队列通过延迟消息的消费时间,提供了一种方便、可靠的方式来处理定时任务和定时事件。它在分布式系统中具有重要的作用,能够提高系统的可靠性和性能。
延时队列的实现方式可以有多种,本文介绍一种redis实现的分布式延时队列。
应用场景
-
定时任务:可以将需要在特定时间执行的任务封装为延时消息,通过延时队列来触发任务的执行。
-
订单超时处理:可以将订单消息发送到延时队列中,并设置订单的超时时间,超过时间后,消费者从队列中获取到超时的订单消息,进行相应的处理。
-
消息重试机制:当某个消息处理失败时,可以将该消息发送到延时队列中,并设置一定的重试时间,超过时间后再次尝试处理。
案例:
12306火车票购买,抢了订单后,45分钟没有支付,自动取消订单
考虑:
数据持久化:redis是支持的,可以使用rdb,也可以使用aof
有序存储:因为只要最小的没过期,后面的肯定就没过期,这样的话检查最小的节点就行了,考虑使用redis中的zset结构
高可用:考虑哨兵或者cluster
高伸缩:因为12306用户量非常大,可能导致redis中存储的任务空间非常大,所以考虑扩展节点,从这个角度来说,使用cluster集群模式,哨兵只有一个节点即主节点写数据。
实现:
整体思路:
- 生产消费者模型:因为12306的用户量非常大,所以考虑生产者和消费者有多个节点;
- 采用cluster模式实现高可用以及高伸缩性;
- 采用zset存储延时任务(zadd key score member,score表示时间);
- 为了让数据均匀分布在cluster集群中的多个主节点中:构建多个zset,每个zset对应一个消费者,生产者随机向某个zset中生产数据。
具体实现
生产者
需要安装hiredis-cluster集群,安装编译如下:
git clone https://github.com/Nordix/hiredis-cluster.git
cd hiredis-cluster
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=RelWithDebInfo -
DENABLE_SSL=ON ..
make
sudo make install
sudo ldconfig
需要安装libevent库,最后编译时执行gcc producer.c -o producer -levent -lhiredis_cluster -lhiredis -lhiredis_ssl编译生产者可执行程序
#include <hiredis_cluster/adapters/libevent.h>
#include <hiredis_cluster/hircluster.h>
#include <event.h>
#include <event2/listener.h>
#include <event2/bufferevent.h>
#include <event2/buffer.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <sys/time.h>int64_t g_taskid = 0;#define MAX_KEY 10static int64_t hi_msec_now() {int64_t msec;struct timeval now;int status;status = gettimeofday(&now, NULL);if (status < 0) {return -1;}msec = (int64_t)now.tv_sec * 1000LL + (int64_t)(now.tv_usec / 1000LL);return msec;
}static int _vscnprintf(char *buf, size_t size, const char *fmt, va_list args) {int n;n = vsnprintf(buf, size, fmt, args);if (n <= 0) {return 0;}if (n <= (int)size) {return n;}return (int)(size-1);
}static int _scnprintf(char *buf, size_t size, const char *fmt, ...) {va_list args;int n;va_start(args, fmt);n = _vscnprintf(buf, size, fmt, args);va_end(args);return n;
}void connectCallback(const redisAsyncContext *ac, int status) {if (status != REDIS_OK) {printf("Error: %s\n", ac->errstr);return;}printf("Connected to %s:%d\n", ac->c.tcp.host, ac->c.tcp.port);
}void disconnectCallback(const redisAsyncContext *ac, int status) {if (status != REDIS_OK) {printf("Error: %s\n", ac->errstr);return;}printf("Disconnected from %s:%d\n", ac->c.tcp.host, ac->c.tcp.port);
}void addTaskCallback(redisClusterAsyncContext *cc, void *r, void *privdata) {redisReply *reply = (redisReply *)r;if (reply == NULL) {if (cc->errstr) {printf("errstr: %s\n", cc->errstr);}return;}int64_t now = hi_msec_now() / 10;printf("add task success reply: %lld now=%ld\n", reply->integer, now);
}int addTask(redisClusterAsyncContext *cc, char *desc) {/* 转化为厘米秒 */int64_t now = hi_msec_now() / 10;g_taskid++;/* key */char key[256] = {0};// 为了让数据均匀分布在cluster集群中的多个主节点中:
// 构建多个zset,每个zset对应一个消费者,生产者随机向某个zset中生产数据,// 生产者可以有很多个,只需要保证向task_group:0-task_group:9中均匀的生产数据即可int len = _scnprintf(key, 255, "task_group:%ld", g_taskid % MAX_KEY);key[len] = '\0';/* member */char mem[1024] = {0};len = _scnprintf(mem, 1023, "task:%ld:%s", g_taskid, desc);mem[len] = '\0';int status;// 为每一个任务延时5秒中去处理status = redisClusterAsyncCommand(cc, addTaskCallback, "","zadd %s %ld %s", key, now+500, mem);printf("redisClusterAsyncCommand:zadd %s %ld %s\n", key, now+500, mem);if (status != REDIS_OK) {printf("error: err=%d errstr=%s\n", cc->err, cc->errstr);}return 0;
}void stdio_callback(struct bufferevent *bev, void *arg) {redisClusterAsyncContext *cc = (redisClusterAsyncContext *)arg;struct evbuffer *evbuf = bufferevent_get_input(bev);char *msg = evbuffer_readln(evbuf, NULL, EVBUFFER_EOL_LF);if (!msg) return;if (strcmp(msg, "quit") == 0) {printf("safe exit!!!\n");exit(0);return;}if (strlen(msg) > 1024-5-13-1) {printf("[err]msg is too long, try again...\n");return;}addTask(cc, msg);printf("stdio read the data: %s\n", msg);
}int main(int argc, char **argv) {printf("Connecting...\n");// 连接cluster集群,可以从cluster集群中任意一个节点出发连接集群redisClusterAsyncContext *cc =redisClusterAsyncConnect("127.0.0.1:7006", HIRCLUSTER_FLAG_NULL);printf("redisClusterAsyncContext...\n");if (cc && cc->err) {printf("Error: %s\n", cc->errstr);return 1;}struct event_base *base = event_base_new();redisClusterLibeventAttach(cc, base);redisClusterAsyncSetConnectCallback(cc, connectCallback);redisClusterAsyncSetDisconnectCallback(cc, disconnectCallback);// nodeIterator ni;// initNodeIterator(&ni, cc->cc);// cluster_node *node;// while ((node = nodeNext(&ni)) != NULL) {// printf("node %s:%d role:%d pad:%d\n", node->host, node->port, node->role, node->pad);// }struct bufferevent *ioev = bufferevent_socket_new(base, 0, BEV_OPT_CLOSE_ON_FREE);bufferevent_setcb(ioev, stdio_callback, NULL, NULL, cc);bufferevent_enable(ioev, EV_READ | EV_PERSIST);printf("Dispatch..\n");event_base_dispatch(base);printf("Done..\n");redisClusterAsyncFree(cc);event_base_free(base);return 0;
}// 需要安装 hiredis-cluster libevent
// gcc producer.c -o producer -levent -lhiredis_cluster -lhiredis -lhiredis_ssl
说明:
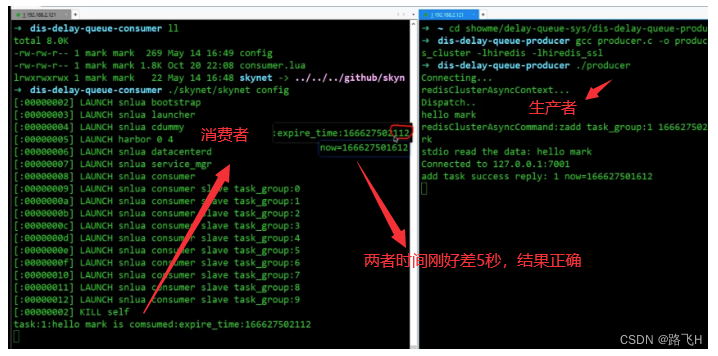
这里构建了10个zset,分别是task_group:0,task_group:1,…,task_group:9作为10个zset的key,zset的数据其实就代表着消费者的数量,通常消费者的功能是一摸一样的,生产者就不管你有多少个了,只需要将任务均匀的打散在不同的zset中就行了(具体实现可以搞一个全局的id,每一次添加任务时id++,然后再对zset个数10取模,最终可以得到0-9之间的一个数,然后再与task_group拼接,这样就可以将任务均匀的打散在不同的zset中)。
消费者
消费者是采用skynet+lua脚本实现的,每个消费者会不断的去检查redis中的任务有没有过期,如果过期,就取出来删除(这里只是demo,只是打印之后删除任务)
local skynet = require "skynet"local function table_dump( object )if type(object) == 'table' thenlocal s = '{ 'for k,v in pairs(object) doif type(k) ~= 'number' then k = string.format("%q", k) ends = s .. '['..k..'] = ' .. table_dump(v) .. ','endreturn s .. '} 'elseif type(object) == 'function' thenreturn tostring(object)elseif type(object) == 'string' thenreturn string.format("%q", object)elsereturn tostring(object)end
endlocal mode, key = ...
if mode == "slave" thenlocal rediscluster = require "skynet.db.redis.cluster"local function onmessage(data,channel,pchannel)print("onmessage",data,channel,pchannel)endskynet.start(function ()local db = rediscluster.new({{host="127.0.0.1",port=7001},},{read_slave=true,auth=nil,db=0,},onmessage)assert(db, "redis-cluster startup error")skynet.fork(function ()while true dolocal res = db:zrange(key, 0, 0, "withscores")if not next(res) thenskynet.sleep(50)elselocal expire = tonumber(res[2])local now = skynet.time()*100if now >= expire thenprint(("%s is comsumed:expire_time:%d"):format(res[1], expire))db:zrem(key, res[1])elseskynet.sleep(10)endendendend)end)elseskynet.start(function () -- // 启动10个程序,并把"slave"传入mode,task_group:i传入到key中,即每个程序只消费一个for i=0,9 doskynet.newservice(SERVICE_NAME, "slave", "task_group:"..i)
运行结果
redis分布式延时队列优势
1.Redis zset支持高性能的 score 排序。
2.Redis是在内存上进行操作的,速度非常快。
3.Redis可以搭建集群,当消息很多时候,我们可以用集群来提高消息处理的速度,提高可用性。
4.Redis具有持久化机制,当出现故障的时候,可以通过AOF和RDB方式来对数据进行恢复,保证了数据的可靠性
redis分布式延时队列劣势
使用 Redis 实现的延时消息队列也存在数据持久化, 消息可靠性的问题:
- 没有重试机制 - 处理消息出现异常没有重试机制, 这些需要自己去实现, 包括重试次数的实现等;
- 没有 ACK 机制 - 例如在获取消息并已经删除了消息情况下, 正在处理消息的时候客户端崩溃了, 这条正在处理的这些消息就会丢失, MQ 是需要明确的返回一个值给 MQ 才会认为这个消息是被正确的消费了。
总结:如果对消息可靠性要求较高, 推荐使用 MQ 来实现