# 背景知识
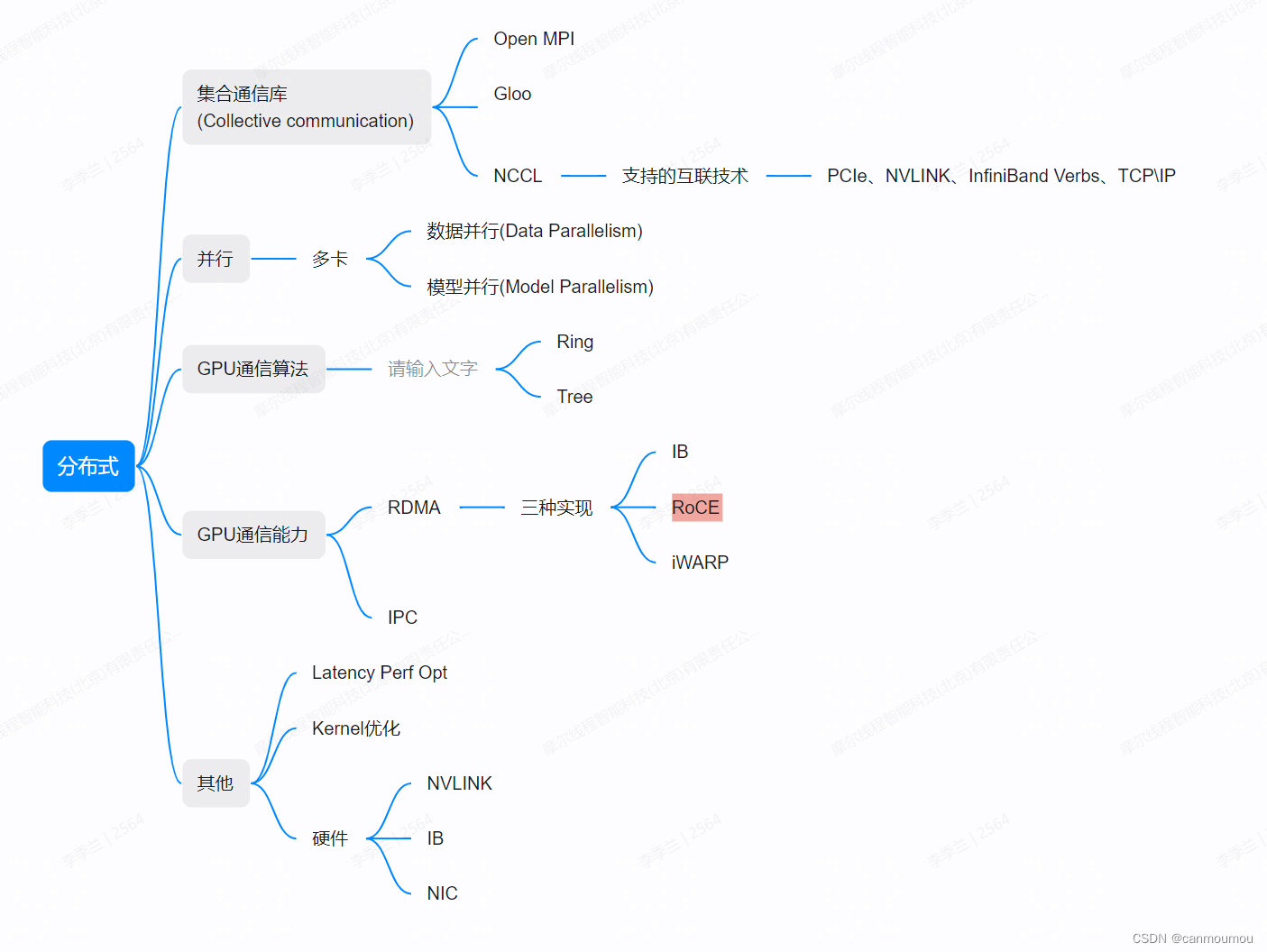
大模型和分布式训练对数据的吞吐量以及并行度都有很高的要求,NCCL就是在这个背景下诞生的。
如果你是一个只会写写Python,调用PyTorch和Horovod的算法萌新,可能对于分布式底层的东西不太了解,在下岗热潮中被主管逼着转变成算子或者通讯库的搬砖工,就会像我一样两眼蒙蔽。因此本文只对自己踩到的坑做一个整理,如果有说错的地方,那就是我说错了。
1. 从PyTorch开始理解结构
以PyTorch为例,其中spmd接口下的相关定义是用于处理分布式的。但主要是处理单机多CPU情况,因此我们今天只考虑多机(多节点)情况。
SPMD(Single Program/Multiple Data),即单程序多份数据进行任务并行。SPMD的本质是对问题进行域分解,它将一个大的问题区域分解成若干个较小的问题区域,然后对其并行求解。
其中用于实现多节点分布式的组件有以下三个:
- Distributed Data-Parallel Training (DDP)
- RPC-Based Distributed Training (RPC)
- Collective Communication (c10d)
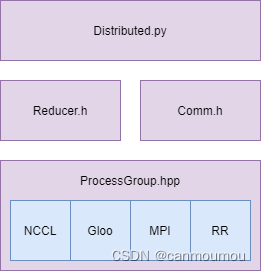
从上图可知,1.6版本左右的PyTorch调用结构如下,最后在ProcessGroup.hpp可以找到对NCCL、Gloo和MPI的调用。
而这些蓝色的部分就是基本的分布式通讯库,他们负责实现通讯和一部分计算功能。
2. 通讯方式
已知显卡与主板通过PCIE相连,任何数据都要从PCIE和CPU穿过,这么做的效率肯定是很低的。
因此在GPUDirect技术出现以后,我们可以把GPU通信分为GPU控制的GPU通信和CPU控制的GPU通信两种。感兴趣相关的细节可以通过此文查看:【研究综述】浅谈GPU通信和PCIe P2P DMA
我们知道通信技术有很多,例如DMA,P2P。DMA和P2P都是一种能力,而非具体的协议。
2.1 DMA & P2P
DMA(Direct Memory Access,直接内存访问),允许在计算机主板上的设备直接把数据发送到内存中去,数据搬运不需要CPU的参与。
传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。
通常,我们也将主机称为节点。
第二代GPUDirect技术被称作GPUDirect P2P(Peer to Peer),重点解决的是节点内GPU通信问题。两个GPU可以通过PCIe P2P直接进行数据搬移,避免了主机内存和CPU的参与。
那么一台机器中的数据搬运是DMA,多台主机的DMA如何实现呢?这就出现了RDMA这一协议。
2.2 RDMA
RDMA( Remote Direct Memory Access )意为远程直接地址访问,通过RDMA,本端节点可以“直接”访问远端节点的内存。所谓直接,指的是可以像访问本地内存一样,绕过传统以太网复杂的TCP/IP网络协议栈读写远端内存,而这个过程对端是不感知的,而且这个读写过程的大部分工作是由硬件而不是软件完成的。
利用机器本身的DMA能力,以及网卡等其他硬件实现的远程DMA。这就和RPC远程过程调用有类似之处。
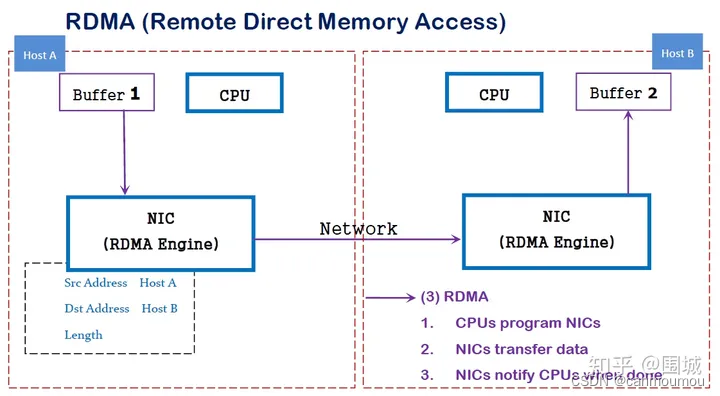
RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输。具有RDMA引擎的以太网卡(RNIC)--而不是host--负责管理源和目标之间的可靠连接。
为了支持RDMA实现,有以下三种网络协议:
| InfiniBand(IB) | 从一开始就支持RDMA的新一代网络协议。由于这是一种新的网络技术,因此需要支持该技术的网卡和交换机。 |
| RDMA过融合以太网(RoCE) | 即RDMA over Ethernet, 允许通过以太网执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡必须是支持RoCE的特殊的NIC。 |
| 互联网广域RDMA协议(iWARP) | 即RDMA over TCP, 允许通过TCP执行RDMA的网络协议。这允许在标准以太网基础架构(交换机)上使用RDMA,只不过网卡要求是支持iWARP(如果使用CPU offload的话)的NIC。否则,所有iWARP栈都可以在软件中实现,但是失去了大部分的RDMA性能优势。 |
IB是最简单的方式,其次是RoCE,当然本文不做赘述,有大篇讲的好的博客,甚至直接看论文和文档也是可以的。NCCL已经支持这些协议。
2.3 MPI
MPI有多种实现方式,例如OpenMPI,MPICH。
MPI 全名叫 Message Passing Interface,即信息传递接口,作用是可以通过 MPI 可以在不同进程间传递消息,从而可以并行地处理任务,即进行并行计算。NCCL中利用MPI来处理多机通讯的部分。
直接下载:
#apt安装mpi
sudo apt-get update
sudo apt install openmpi-bin openmpi-doc libopenmpi-dev
#验证是否安装成功
mpirun --version自己编译可参考前文:分布式学习 - MPICH编译与实践_mpich 编译指定 mpich cc_canmoumou的博客-CSDN博客
3. NCCL
NCCL在单机多卡环境下的编译与运行参考我的前文:【分布式】NCCL部署与测试 - 01_canmoumou的博客-CSDN博客
NCCL本身具备了基本的通信协议支持、环路算法、原语操作等等。
由于数据运输和计算都是在GPU上完成,需要launch kernel,因此阅读源码前要具备基本的CUDA知识。
3.1 NCCL 多机多卡实践
环境配置
1. 两台多卡服务器,需要配置好无密钥登陆(ssh),以及NFS共享目录。NFS挂载方式如果我有空另外再写。
2. 检查IB设备及性能,确定有一块或多块IB网卡,安装nv_peer_mem驱动
3. 配置BIOS:配置IOMMU等
如何检查:
# check system physical memory size
sudo dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'sudo cat /var/log/dmesg | grep -e "AMD-Vi: Interrupt remapping enabled" -e "IOMMU enabled"若发现IOMMU被disabled,请到BIOS界面更改:
选择enable Intel VT for Directed I/O (VT-d)选项
或者enable IOMMU选项
4. 打开CPU高性能模式,并配置网络
查看IB网络是否正常
|
|
5. 下载其他依赖,下载NCCL源码并保证单机单卡可以运行,下载mpich。
编译运行
我们通过NCCL-TEST运行程序,其中NCCL原仓库代码不需要重新编译,只有NCCL-TEST需要重新编译,必须增添MPI_HOME,并设置MPI=1
# 单机编译nccl-test:
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl# 多机编译
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl MPI_HOME=/path/to/mpi MPI=1
将编译好的build文件放到NFS目录下,这样两台机器都可以在共享目录看到此文件。
再在共享目录外设置算法拓扑(topo.txt)和图结构(graph.txt),并添加mpi_hosts文件。mpi_hosts文件内放两张机器的ip地址:
# MPI CLUSTERS
X.X.X.X manager slots=1
X.X.X.X worker1 slots=1运行:
|
|
请注意,-np的值为mpi_hosts内各个slots之和。
使用mpich运行的时候,以单机的方式运行,也就是单机四卡是-g 4,多机四卡的参数也是-g 4.