一、 RNN
简单RNN
二、LSTM
受计算机的逻辑门启发,引入记忆单元(memory cell),并通过各种门来控制记忆单元。
1 遗忘门、输入门、输出门
首先,通过输入 X t X_t Xt 和 上一个隐状态 H t − 1 H_{t-1} Ht−1 与全连接层相乘 再加上偏置,最后经过激活函数sigmoid, 得到三个门:遗忘门 f f f, 输入门 i i i, 输出门 o o o
I t = σ ( X t W x i + H t − 1 W h i + b i ) , F t = σ ( X t W x f + H t − 1 W h f + b f ) , O t = σ ( X t W x o + H t − 1 W h o + b o ) , \begin{split}\begin{aligned} \mathbf{I}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i),\\ \mathbf{F}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f),\\ \mathbf{O}_t &= \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o), \end{aligned}\end{split} ItFtOt=σ(XtWxi+Ht−1Whi+bi),=σ(XtWxf+Ht−1Whf+bf),=σ(XtWxo+Ht−1Who+bo),
2 候选记忆元
接着,通过输入 X t X_t Xt 和 隐状态 H t − 1 H_{t-1} Ht−1 与全连接层相乘 再加上偏置,最后经过激活函数tanh, 得到候选记忆单元 C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) , \tilde{\mathbf{C}}_t = \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c), C~t=tanh(XtWxc+Ht−1Whc+bc),
3 记忆元
然后,计算遗忘门 f f f、输入门 i i i 分别与上一个隐状态 H t − 1 H_{t-1} Ht−1和候选记忆元 C ~ t \tilde{\mathbf{C}}_t C~t 按元素相乘再相加: C t = F t ⊙ C t − 1 + I t ⊙ C ~ t . \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t. Ct=Ft⊙Ct−1+It⊙C~t.
如果遗忘门始终为1且输入门始终为0, 则过去的记忆元 C t − 1 \mathbf{C}_{t-1} Ct−1,将随时间被保存并传递到当前时间步。 引入这种设计是为了缓解梯度消失问题, 并更好地捕获序列中的长距离依赖关系。
4 隐状态
最后,计算隐状态:
H t = O t ⊙ tanh ( C t ) . \mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t). Ht=Ot⊙tanh(Ct).
只要输出门接近1,我们就能够有效地将所有记忆信息传递给预测部分, 而对于输出门接近0,我们只保留记忆元内的所有信息,而不需要更新隐状态
三、GRU
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。 这些机制是可学习的,并且能够解决了上面列出的问题。 例如,如果第一个词元非常重要, 模型将学会在第一次观测之后不更新隐状态。 同样,模型也可以学会跳过不相关的临时观测。 最后,模型还将学会在需要的时候重置隐状态
1 重置门、更新门
首先,通过输入 X t X_t Xt 和 上一个隐状态 H t − 1 H_{t-1} Ht−1 与全连接层相乘 再加上偏置,最后经过激活函数sigmoid, 得到重置门 R t \mathbf{R}_t Rt, 更新门 Z t \mathbf{Z}_t Zt
R t = σ ( X t W x r + H t − 1 W h r + b r ) , Z t = σ ( X t W x z + H t − 1 W h z + b z ) , \begin{split}\begin{aligned} \mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{W}_{hr} + \mathbf{b}_r),\\ \mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{t-1} \mathbf{W}_{hz} + \mathbf{b}_z), \end{aligned}\end{split} Rt=σ(XtWxr+Ht−1Whr+br),Zt=σ(XtWxz+Ht−1Whz+bz),
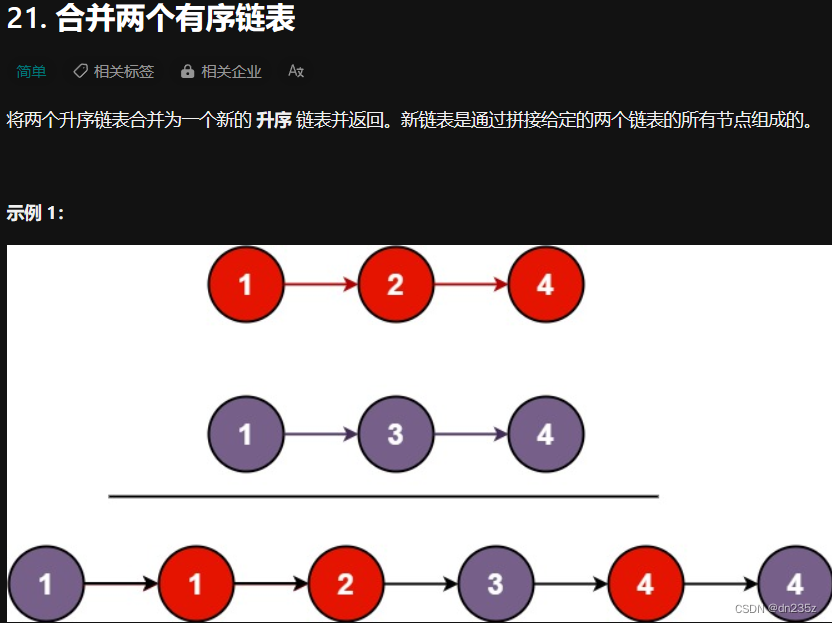
2 候选隐状态
然后, 输入 X t X_t Xt 乘以全连接层 加上 R t \mathbf{R}_t Rt和 H t − 1 \mathbf{H}_{t-1} Ht−1的元素相乘后的结果 乘以全连接层
H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) , \tilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h), H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh),
R t \mathbf{R}_t Rt和 H t − 1 \mathbf{H}_{t-1} Ht−1的元素相乘可以减少以往状态的影响。 每当重置门 R t \mathbf{R}_t Rt中的项接近1时, 我们恢复一个普通的循环神经网络。 对于重置门 R t \mathbf{R}_t Rt中所有接近0的项, 候选隐状态是以作为输入的多层感知机的结果。 因此,任何预先存在的隐状态都会被重置为默认值
3 隐状态
最后,使用更新门 Z t \mathbf{Z}_t Zt在 H t − 1 \mathbf{H}_{t-1} Ht−1和 H ~ t \tilde{\mathbf{H}}_t H~t之间进行按元素的凸组合
H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t . \mathbf{H}_t = \mathbf{Z}_t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t. Ht=Zt⊙Ht−1+(1−Zt)⊙H~t.
每当更新门 Z t \mathbf{Z}_t Zt接近1时,模型就倾向只保留旧状态。 此时,来自 X t X_t Xt的信息基本上被忽略, 从而有效地跳过了依赖链条中的时间步 t t t。 相反,当 Z t \mathbf{Z}_t Zt接近0时, 新的隐状态 H t \mathbf{H}_t Ht 就会接近候选隐状态 H ~ t \tilde{\mathbf{H}}_t H~t。 这些设计可以帮助我们处理循环神经网络中的梯度消失问题, 并更好地捕获时间步距离很长的序列的依赖关系。 例如,如果整个子序列的所有时间步的更新门都接近于1, 则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列结束。
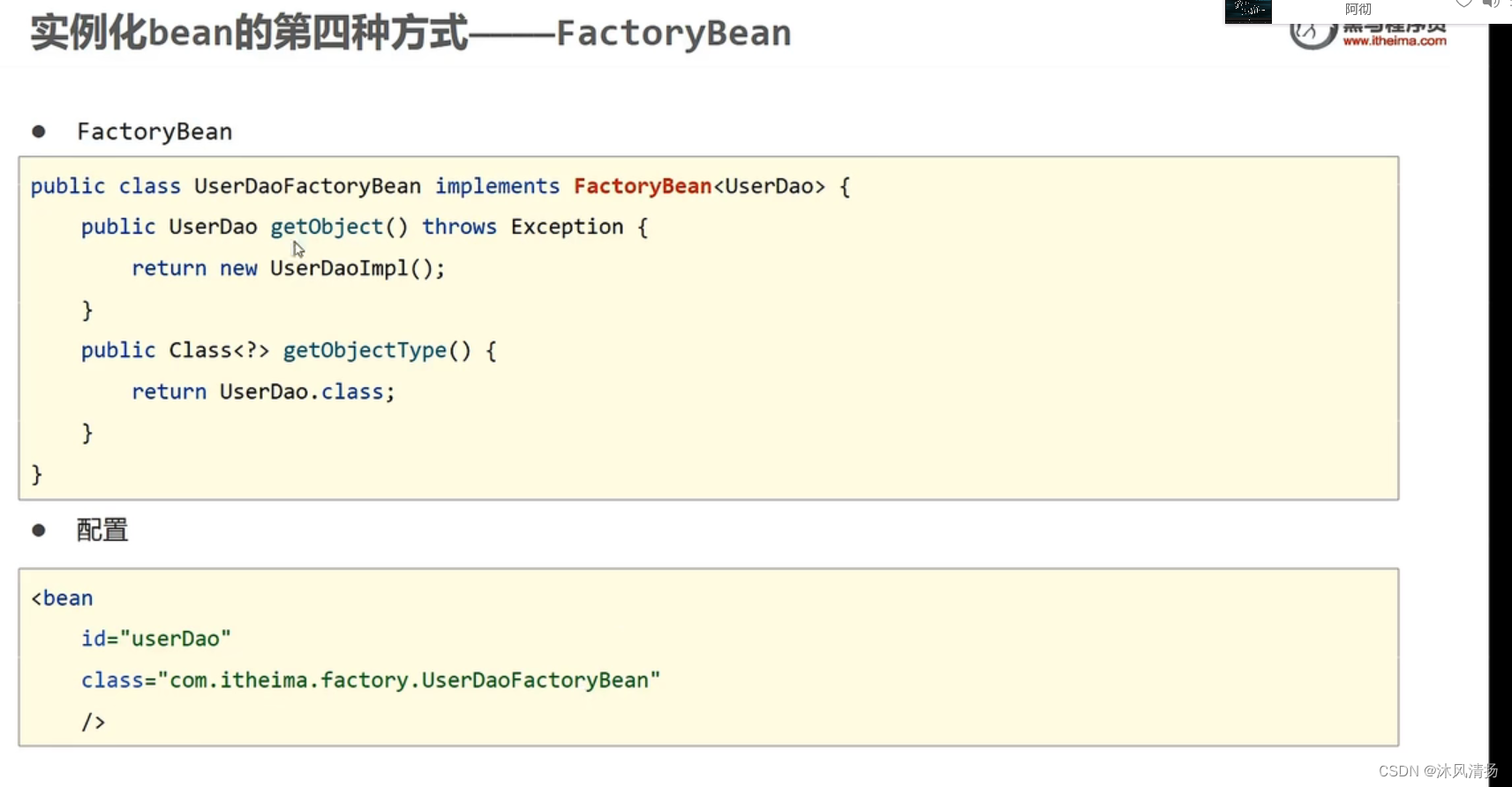
pytorch LSTM实现
LSTMCell
Inputs: input, (h_0, c_0)
input of shape (batch, input_size) or (input_size): tensor containing input features
h_0 of shape (batch, hidden_size) or (hidden_size): tensor containing the initial hidden state
c_0 of shape (batch, hidden_size) or (hidden_size): tensor containing the initial cell state
If (h_0, c_0) is not provided, both h_0 and c_0 default to zero.
Outputs: (h_1, c_1)
h_1 of shape (batch, hidden_size) or (hidden_size): tensor containing the next hidden state
c_1 of shape (batch, hidden_size) or (hidden_size): tensor containing the next cell state
rnn = nn.LSTMCell(10, 20) # (input_size, hidden_size)
input = torch.randn(2, 3, 10) # (time_steps, batch, input_size)
hx = torch.randn(3, 20) # (batch, hidden_size)
cx = torch.randn(3, 20)
output = []
for i in range(input.size()[0]):hx, cx = rnn(input[i], (hx, cx))output.append(hx)
output = torch.stack(output, dim=0)