1. Kafka简介

Apache Kafka 是LinkedIn公司开发的一款开源的高吞吐、分布式的消息队列系统,它具有高伸缩性、高可靠性和低延迟等特点,因此在大型数据处理场景中备受青睐。Kafka 可以处理多种类型的数据,如事件、日志、指标等,广泛应用于实时数据流处理、日志收集、监控和分析等领域。
2. 设计架构
-
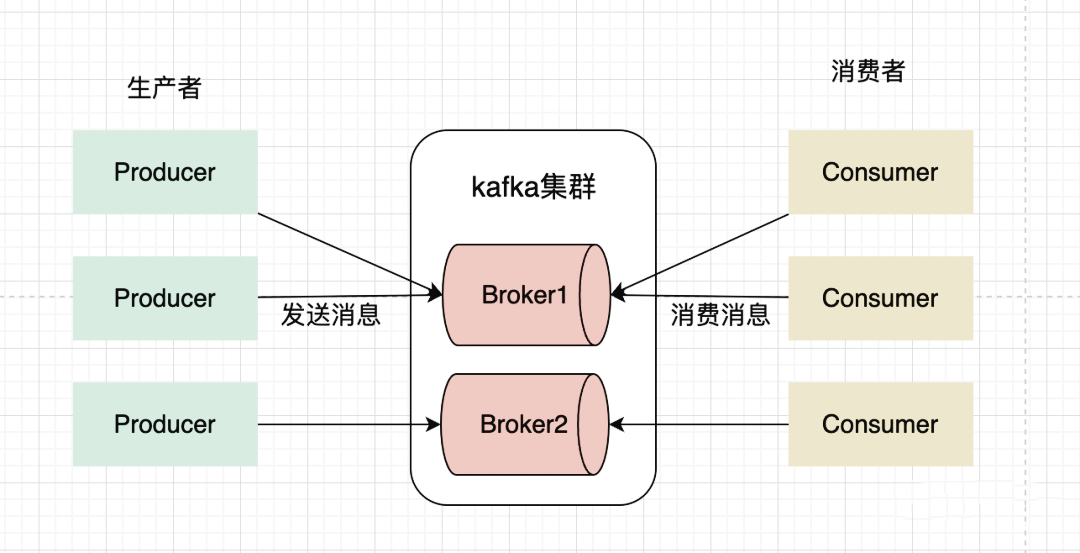
Producer :消息生产者,就是向 kafka broker 发消息的客户端。 -
Consumer :消息消费者,向 kafka broker 取消息的客户端。 -
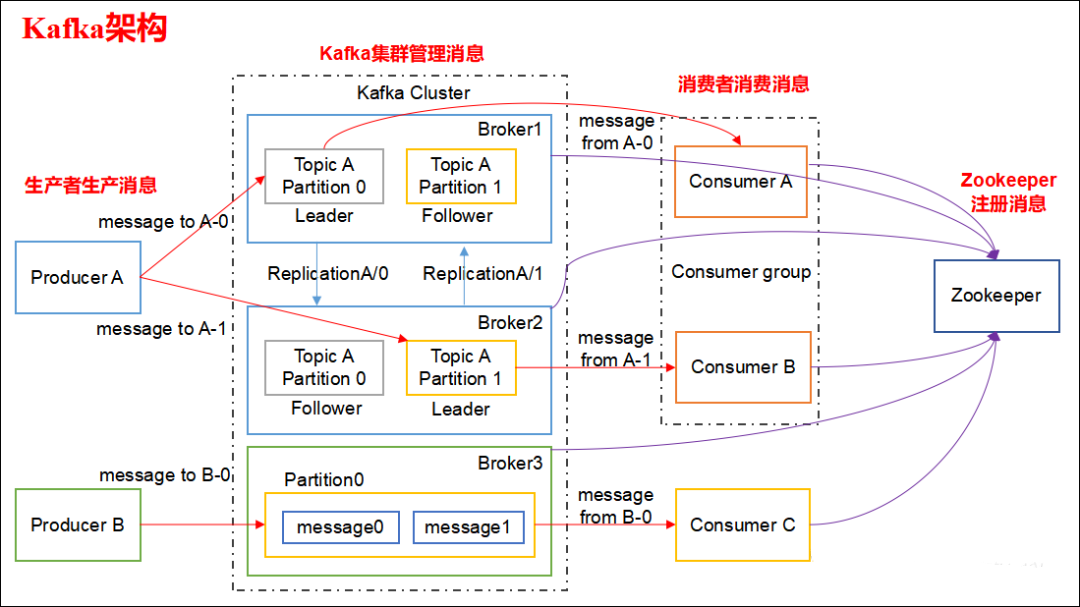
Topic :一个Topic是消息的分类或主题,它是Kafka中进行消息发布和订阅的基本单位。Producer(生产者)将消息发布到一个或多个Topic,而Consumer(消费者)订阅一个或多个Topic并消费其中的消息。 -
Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。 -
Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。 -
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。 -
Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
3. Kafka特点
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。 -
可扩展性:kafka集群支持热扩展 -
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失 -
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败) -
高并发:支持数千个客户端同时读写
4. 使用场景
-
日志收集:可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。 -
消息系统:解耦和生产者和消费者、缓存消息等。 -
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。 -
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。 -
流式处理:比如spark streaming和 Flink。 -
系统解耦:在重要操作完成后,发送消息,由别的服务系统来完成其他操作 -
流量削峰:一般用于秒杀或抢购活动中,来缓冲网站短时间内高流量带来的压力 -
异步处理:通过异步处理机制,可以把一个消息放入队列中,但不立即处理它,在需要的时候再进行处理
5. 安装、配置和启动Kafka
要安装、配置和启动Kafka,请按照以下步骤进行操作:
-
下载Kafka:从Apache Kafka官网下载最新版本的Kafka,并解压到本地目录。
-
配置Kafka:编辑Kafka的配置文件(
config/server.properties),根据需求修改以下配置项:-
advertised.listeners:Kafka Broker的地址和端口配置。 -
zookeeper.connect:ZooKeeper的地址和端口配置。
-
-
启动ZooKeeper:打开一个终端窗口,启动ZooKeeper服务器:
bin/zookeeper-server-start.sh config/zookeeper.properties。 -
启动Kafka Broker:在另一个终端窗口中,启动Kafka Broker服务器:
bin/kafka-server-start.sh config/server.properties。
顶尖架构师栈
关注回复关键字
【C01】超10G后端学习面试资源
【IDEA】最新IDEA激活工具和码及教程
【JetBrains软件名】 最新软件激活工具和码及教程
工具&码&教程
本文由 mdnice 多平台发布


![计算机视觉与深度学习-卷积神经网络-纹理表示卷积神经网络-纹理表示-[北邮鲁鹏]](https://img-blog.csdnimg.cn/759031e1316e495e99808c0728f83ee3.png)

