| MySQL | PostgreSQL | |
|---|---|---|
| 数据类型支持 | 支持JSON,但不如PostgreSQL | 支持更多的数据类型,如数组、hstore、JSON、JSONB、范围类型等 |
| 扩展性 | 有一些扩展性,但不如PostgreSQL | 支持自定义数据类型、函数、操作符,具有强大的扩展性 |
| SQL兼容性 | 遵循SQL标准,但有一些自定义扩展 | 更接近ANSI SQL标准,支持窗口函数、公共表表达式等 |
| 性能优化 | 对简单查询进行了优化,特别是读密集型摸作 | 有一个复杂的查询优化器,对于复杂查询很有优势 |
| 外部连接 | 有限的外部连接支持 | 支持外部表、外部连接,可以与其他数据周或数据源进行连接 |
| 程序语言支持 | 主要支持SQL和JavaScript,通过MySQL Shell支持Python | 支持多补存储过程语言,如PL/pgSQL、PL/TCl、PL/Python等 |
| 地理信息系统 | 有空间扩展,但不如PostGIS强大 | 通过PostGIS扩展提供强大的GIS支持 |
| 复制和分区 | 支持基于二进制日志的复制,也支持表分区 | 支持逻辑复制、表分区、双向复制等 |
| 学习曲线 | 由于其广没的使用和丰富的社区资源,相对容易上手 | 对于初学者可能稍微陡峭一些,特别是在高级特性和优化方面 |
| 市场份额 | 在Web应用领域有很大的市场份频,被广泛采用 | 在企业级应用和特定领域(如GIS)中堂欢迎,但在小型Web应用中的市场份额较小 |
| 管理工具 | 有丰宫的管理工具,如MySQL Workbench,以及大量的第三方工具 | 尽等有–些第三方工具,但可能不如MySOL丰富 |
| 维护团队 | MySQL的背后是一个成熟的商业公司,使得MySQL的开发过程更为慎重 | PostgreSQL的背后是一个庞大的志愿开发组,PostgreSQL的反应更为迅速 |
| MVCC | MySQL采用了一种基于“回滚段”的方法来保存元组的历史版本(前像),如果事务更新了一条元组,它可以“原地”更新这条元组(新元组的 Size 需要小于等于旧元组的 Size),历史元组会以 Undo 日志记录的形式保存到回滚段中,这样就实现了元组的原地更新(Inplace Update)。当有并发事务需要访问历史元组时,可以从回滚段中“回滚”出这条元组,如果事务异常终止,则可以利用 Undo 日志将数据恢复。当所有可能访问历史元组的事务全部结束后,Undo 日志中的历史元组就可以被清理。由于 Undo 日志被集中存储到某一个回滚段,所以清理也较为便捷。 | PostgreSQL 将历史元组和最新元组都保存在 Heap 表中,这种方式的好处是无须做回滚操作,如果一个写事务异常终止,则其他事务将无法读到这条元组。此方法虽然可以避免事务回滚带来的消耗,但仍被广为诟病。假设一个事务不停地更新数据,那么一条元组就会产生大量的历史版本。其他事务在访问时需要查看这些元组是否满足可见性要求,这会增加读操作的时延,降低数据扫描的效率。为了防止数据膨胀,PostgreSQL 数据库采用 Vacuum 机制清理表中的无效元组。如果使用 Vacuum FULL 命令,则还会负责对所有的元组进行搬迁,避免清理页面的过程中产生大量的“空洞”。 |
| 进程模型 | 多线程优点:▶︎ 资源效率:线程共享相同的内存空间,这通常导致更低的内存使用和更快的上下文切换。▶︎ 高并发性:多线程模型通常能够更好地处理高并发情况,尤其是在多核 CPU 上。▶︎ 线程间通信:线程间通信通常比进程间通信更简单和更快。适合短暂任务:对于短暂的、需要快速响应的任务,多线程模型可能更为合适。缺点:▶︎ 稳定性问题:一个线程的问题可能会影响到同一进程中的其他线程。例如,一个线程导致的内存泄可能会影响整个进程。▶︎ 复杂的同步:在多线程环境中,数据同步和锁定可能会变得更加复杂。全局变量和静态变量:由于线程共享内存,全局变量和静态变量的使用可能会导致问题。 | PostgreSQL 采用多进程优点:▶︎ 稳定性:由于每个连接都有自己的进程,一个进程崩溃不太可能影响其他进程。这为系统提供了额外的稳定性。▶︎ 内存隔离:每个进程都有自己的内存空间,这可以减少内存泄漏或其他问题对整个系统的影响。▶︎ 开发简单性:多进程模型在某些情况下可能更容易开发和维护。缺点:▶︎ 资源开销:进程通常比线程需要更多的资源。每个进程都有自己的内存空间,这可能导致更的内存使用。▶︎ 上下文切换:进程之间的上下文切换可能比线程之间的上下文切换更加昂贵。▶︎ 进程间通信:进程间通信(IPC)可能比线程间通信更复杂和开销更大。 |
| 数据结构 | 索引组织表:数据直接存储在主键索引的叶子节点中,这意味着表数据按主键的顺序存储。由于数据与主键索引紧密结合,所以通常可以更快地访问基于主键的查询。优点:▶︎ 查询性能:由于数据是按键值排序的,范围查询和某些类型的查找可以更快。▶︎ 空间效率:通常使用较少的磁盘空间,因为它们减少了数据的冗余和碎片。▶︎ 数据完整性:由于数据是按键值存储的,这可以确保数据的完整性和一致性。 | 堆表:数据存储在一个称为"堆"的无序结构中。索引存储指向堆中行的指针(CTID),而不是实际的行数据。优点:▶︎ 简单性:堆表是最基本的表结构,不需要特定的排序或组织。▶︎ 快速插入:数据可以迅速地添加到表的末尾,不需要重新排序或调整数据。▶︎ 灵活性:可以轻松地添加或删除索引,而不影响表的基本结构。缺点:▶︎ 查询速度:由于数据没有特定的组织方式,查询可能需要全表扫描,尤其是在没有索引的情况下。▶︎ 空间使用:可能会有更多的碎片,因为删除的行可能不会立即被回收,需要额外的操作如表重组来回收空间。 |
| 开源协议 | MySQL 采用 GPLv2 是一个“传染性”的开源许可证,这意味着任何基于 GPLv2 许可的代码进行修改或扩展,并且要分发的派生作品,也必须在 GPLv2 下发布。这确保了软件的自由性,但也可能限制了与非 GPL 软件的集成。 | PostgreSQL License 是一个宽松的开源许可证,类似于 MIT 许可证。它允许用户自由使用、修改和分发,无需公开源代码。它也不强制任何特定的版权声明,这使得它与许多其他开源和专有许可证兼容。 |
MySQL与PostgreSQL对比
news/2024/11/29 7:50:56/
相关文章

基于Vue+ELement搭建登陆注册页面实现后端交互
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《ELement》。🎯🎯 …

若依注解学习(一)@Log
Log 涉及到: Log,LogAspect,SecurityUtils,SysUser,SysOperLog,BusinessStatus,StringUtils,ServletUtils AsyncManager,AsyncFactoryÿ…

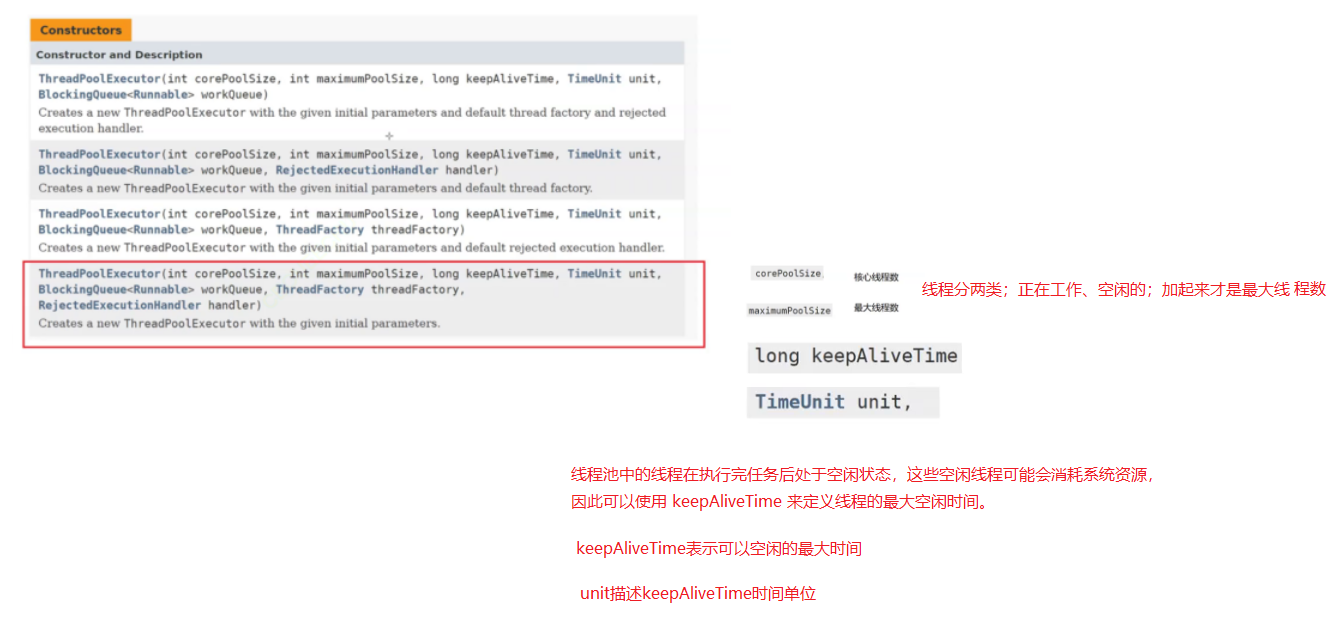
多线程-定时器、线程池
阻塞队列介绍标准库阻塞队列使用基于阻塞队列的简单生产者消费者模型。实现一个简单型阻塞队列 (基于数组实现) 定时器标准库的使用 线程池使用线程数目确定 阻塞队列介绍
不要和之前学多线程的就绪队列搞混; 阻塞队列:也是一个…
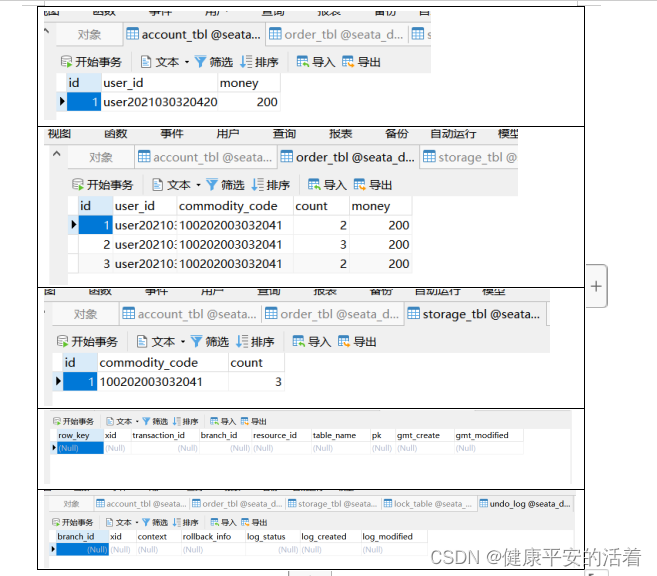
springcloud3 分布式事务解决方案seata之AT模式5
一 seata的AT模式
1.1 AT模式与XA模式 XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。 XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。 XA模式强一致;AT模式最终一致
1.2 …
vue3 父子组件传值
一,子传父
父组件
<script setup>
import HelloWorld from ./components/HelloWorld.vue
import { ref } from vue//直接赋值页面不会自动渲染,使用ref存储响应式数据
import { defineExpose } from "vue";父传子
let val ref();
con…
OpenAI官方吴达恩《ChatGPT Prompt Engineering 提示词工程师》(3)摘要
摘要/ Summarizing
如何使用大模型来概括文本
环境准备
和(①指南)一样需要搭建一个环境 导入OpenAI、加载API密钥以及这个getCompletion辅助函数
import openai
import osfrom dotenv import load_dotenv, find_dotenv
_ load_dotenv(find_dotenv(…