- 阻塞队列介绍
- 标准库阻塞队列使用
- 基于阻塞队列的简单生产者消费者模型。
- 实现一个简单型阻塞队列 (基于数组实现)
- 定时器
- 标准库的使用
- 线程池使用
- 线程数目确定
阻塞队列介绍
不要和之前学多线程的就绪队列搞混;

阻塞队列:也是一个队列,先进先出。带有特殊的功能 ;阻塞
1:如果队列为空,执行出队列操作,就会阻塞阻塞到另一个线程往队列里添加元素(队列不空)为止
2:如果队列满了,执行入队列操作,也会阻塞阻塞到另一个线程从队列取走元素位置(队列不满)
消息队列:
先简单介绍消息队列:特殊的队列,相当于在阻塞队列的基础上,加上一个消息类型,按照类别进行先进先出。
因为这个消息队列使用起来太香;所以有大佬把这样的数据结构单独实现成一个程序;可以单独的部署到一组服务器上。使储存、转发能力大大提升。现在已经发展可以和mysql、redis相提并论的一个重要组件。
消息队列之所以这么好用和阻塞队列阻塞特性关系非常大;基于这种特性可以实现 “生产者消费者模型”
生产者消费者模型(常用的并发设计模式):比如包饺子;一个人负责制作饺子皮;一个人负责包;一个人负责下锅。不会说每个人单独包一个饺子,这样会导致撵面杖不够用,影响效率。两个好处。
1:实现发送方与接收方之间的解耦。
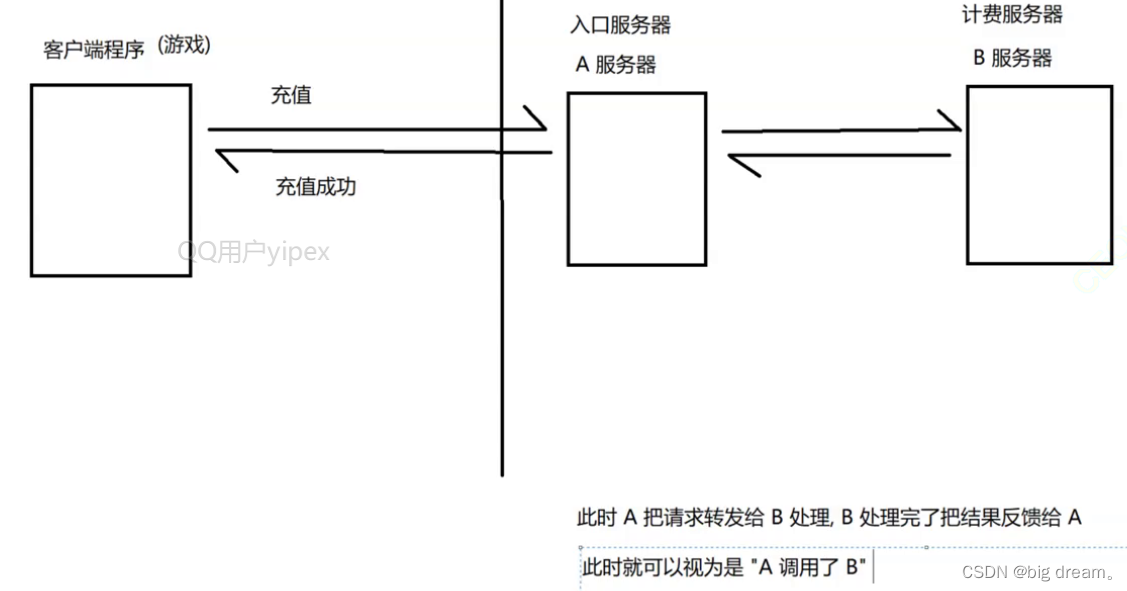
比如下面这种是耦合度比较高;A要调用B(A把请求转发给B处理,B把结果反馈给A),A得知道B的存在。如果B挂了,很容易引起A的bug。。如果你要增加一个C服务器,对A也需要修改代码,对A又得重新测试等又不知道是否改动A会对B有影响。
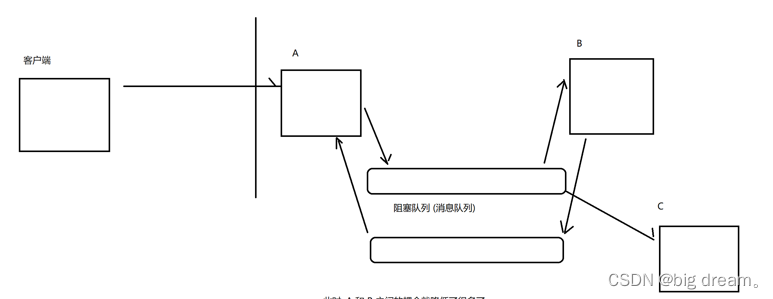
这种模型下;A、B耦合就降低很多;A中无B,B中无A的代码。两边有一方挂了都互相没任何影响;因为阻塞队列是正常的。B挂了,A仍然可以插入元素,满了就阻塞。A挂了,B仍然可以从队列获取元素;空了就阻塞。增加一个C服务器对A是无感知的。
2:削峰填谷的作用,保证系统的稳定性。
服务器开发也很类似;说不定坤哥唱一首只因你太美;热搜瞬间上来,很多用户给你发请求,如果没有削峰填谷的准备服务器很容易就挂掉。
标准库阻塞队列使用

Queue提供:入队列 offer 、出队列 poll、取队首元素 peek。
阻塞队列主要方法:入队列 put、出队列 take。抛异常阻塞得需要唤醒,空队列你再取就阻塞。阻塞队列也有offer和poll方法,但是这些是不带阻塞功能的。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.PriorityBlockingQueue;public class test14 {//标准库阻塞队列使用public static void main(String[] args) throws InterruptedException {
// BlockingDeque<String> q=new PriorityBlockingQueue<>() 基于堆;带有优先级阻塞队列BlockingDeque<String> q=new LinkedBlockingDeque<>();//基于链表实现
// BlockingDeque<String> q=new ArrayBlockingQueue<>(); 基于数组实现q.put("hello");System.out.println(q.take());//输出结果helloq.take();//空的时候取就会阻塞}
}基于阻塞队列的简单生产者消费者模型。
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;public class test15 {//基于阻塞队列生产者消费者模型static int i=0;public static void main(String[] args) {BlockingDeque<Integer> blockingDeque=new LinkedBlockingDeque();Thread t1=new Thread(()->{//生产者while (true){try {blockingDeque.put(i);System.out.println(i);//生产的元素i++;Thread.sleep(500);//生产的很慢;消费者就得阻塞先;等到元素生产出来} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();Thread t2=new Thread(()->{//消费者while (true){try {System.out.println(blockingDeque.take());//消费的元素} catch (InterruptedException e) {throw new RuntimeException(e);}}});t2.start();}
}执行效果
实现一个简单型阻塞队列 (基于数组实现)
先复习一下循环队列的实现。
public class test16 {//简单阻塞队列的实现;;先复习一遍循环队列private int[] elem;public int front;//队头public int rear;//队尾public test16(int k) {//创建这个对象,就有循环队列k大小数组elem=new int[k];}//判满;入队的前提条件,入队是满就直接返回。或者你在满的时候扩容,入之前判断是否满;如果满扩容再入public boolean isfull(){//怎么判;队尾+1 回到头。但是刚好队头在原点就会产生;位置相同;但是队尾+1的值不等于0.if((rear+1)%elem.length==front){return true;}return false;}//判空;出队的前提条件,出队是空直接返回public boolean isnull(){//对头==队就是空if(rear==front){return true;}
return false;}//入队方法;
public boolean offer1(int i) {if(isfull()){//满的情况返回入队失败return false;}//怎么入;是入在后面还是前面呢;队列尾入;这时候浪费的那个空间直接赋值进去;队尾往后移就好了elem[rear]=i;//会不会有点不合适;万一前面是没有元素呢rear=(rear+1)%elem.length; //这个队尾两种情况;第一种是单纯的加1;未到数组最后位置//比如我把前面空间删除。刚好到最后一个位置;就得回归原点。%elem.length//这里分开写效果会更好;rear++; if(rear>=elem.length){ rear=0; }//相比之下rear++;read=read%elem.length 。这个不易读,不直观;每次得理解好一会 。效率上又没有优势return true;}//出队方法public Int poll1(){//头出、怎么出呢。感觉不合理;出队应该返回这个元素.所以得先记录if(isnull()){return -1;}int value=front;front=(front+1)%elem.length;//往后移一位;elem.length避免逛了一圈return elem[value];}//获取队首public int peek1(){if(isnull()){return -1;}return elem[front];}//获取队尾public int Rear(){if(isnull()){return -1;}//得注意;不能直接返回read-1.因为如果read是原点;那么减1不就变成负一if(rear==0){return elem[elem.length-1];}elsereturn elem[rear-1];}public static void main(String[] args) {}
}我们在此基础上加上阻塞功能就好了;也就是在多线程环境下使用;得保证线程安全。
在线程里使用这些方法时;如果出现符合阻塞条件情况就阻塞。
public class test17 {static int i;public static void main(String[] args) throws InterruptedException {//看看能不能基于我们创建这个阻塞队列实现生产者消费者模型my blockingDeque=new my(100);//这里浪费一个空间;达到98;就会阻塞Thread t1=new Thread(()->{//生产者while (true){try {blockingDeque.offer1(i);System.out.println(i);//生产的元素i++;Thread.sleep(50);//生产的很慢;消费者就得阻塞先;等到元素生产出来} catch (InterruptedException e) {throw new RuntimeException(e);}}});t1.start();Thread t2=new Thread(()->{//消费者while (true){try {System.out.println(blockingDeque.poll1());//消费的元素} catch (InterruptedException e) {throw new RuntimeException(e);}}});// t2.start();}}class my {//简单阻塞队列的实现;;先复习一遍循环队列private int[] elem;public int front;//队头public int rear;//队尾public my(int k) {elem = new int[k];}public void offer1(int i) throws InterruptedException {synchronized (this) {if (isfull()) {this.wait();}elem[rear] = i;rear = (rear + 1) % elem.length;// 这个 notify 唤醒 poll1 中的 waitthis.notify();}}//出队方法public int poll1() throws InterruptedException {synchronized (this) {if (isnull()) {this.wait();//两个wait是不可能同时触发的;因为一个队列不可能既是空又是满。只要this是同一个对象就不会.}int value = front;front = (front + 1) % elem.length;// 这个 notify 唤醒 offer1 中的 waitthis.notify();return elem[value];}}public boolean isfull() {if ((rear + 1) % elem.length ==front) {return true;}return false;}public boolean isnull() {//队头==队尾就是空if (rear == front) {return true;}return false;}}
上述代码还有一丝丝的瑕疵;offer1中wait被唤醒的时候;if的条件一定就不成立?(也就是队列一定是不满的?)
我们当前代码是取元素的时候;就唤醒,是不存在这个问题。万一其它操作也可能唤醒这个wait;但是情况又是队列不满的呢?
所以我们改成
whlie (isnull()) {this.wait();}
定时器
到一定时间就执行一个准备好的代码/方法。注册一个任务;任务会在指定时间进行执行。
标准库的使用
定时器:指定一个时间去执行一个任务,让程序去代替人工准时操作。
import java.util.Timer;
import java.util.TimerTask;public class test18 {//标准库定时器的使用public static void main(String[] args) {System.out.println("任务启动前");Timer timer=new Timer();//有很多方法;参数。可以注册多个任务。也得看官方文档timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("任务启动后");}}, 3000);}}线程池使用
并发量的提升我们会发现;线程的创建也会消耗不少资源;使用我们使用线程池降低线程的创建和销毁开销。因为线程池是事先就将线程创建好放入"线程池"中,后面需要的时候,直接从池子中取。这样就省去线程的创建和销毁开销;省一些CPU。
先看一下标准库的线程池怎么使用:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;// 使用一下标准库的线程池
public class ThreadDemo26 {public static void main(String[] args) {ExecutorService pool = Executors.newFixedThreadPool(10);for (int i = 0; i < 1000; i++) {int n = i;pool.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello " + n);}});}}
}
ExecutorService pool = Executors.newFixedThreadPool(10);相当于new操作;这个操作很奇葩;用某个类的静态方法直接构造出一个对象来(相当于把new操作隐藏到方法后面)
工厂模式:上述的这种设计模式;用普通方法代替构造方法创建对象;但是有坑;如果创建多种对象;构造不同情况对象;多个构造方法得通过重载方式创建
submit方法:给线程池提交任务;线程池的线程都是前台线程;会阻止进程结束。定时器也是如此
有个问题:

lanbda表达式;这里的run方法属于Runnable;这个方法的执行时机是在未来的某个节点;后续线程池队列中;排到他就让对应的线程去执行。这个for循环的i是主线程的局部变量;主线程执行完就销毁了;run任务还没在线程池排到队;i就已经销毁。
变量捕获:内部类(Runnable的匿名内部类)捕获了外部方法中的局部变量n。
匿名内部类(包括Lambda表达式)可以访问它们周围方法的局部变量,n是一个局部变量,但它是final的,因为它在for循环内部不会被修改。
jdk1.8之前只能捕获final;而1.8后无需显式声明它们为final;只要代码没修改这个变量就可以捕获。
n是在每次迭代中都创建了一个新的变量实例,而i是在不同迭代中都指向相同的变量实例。所以i是没法捕获。
上述线程池的使用;就是一个工厂类;包装ThreadPooIExecutor实现的;让我们使用更方便。
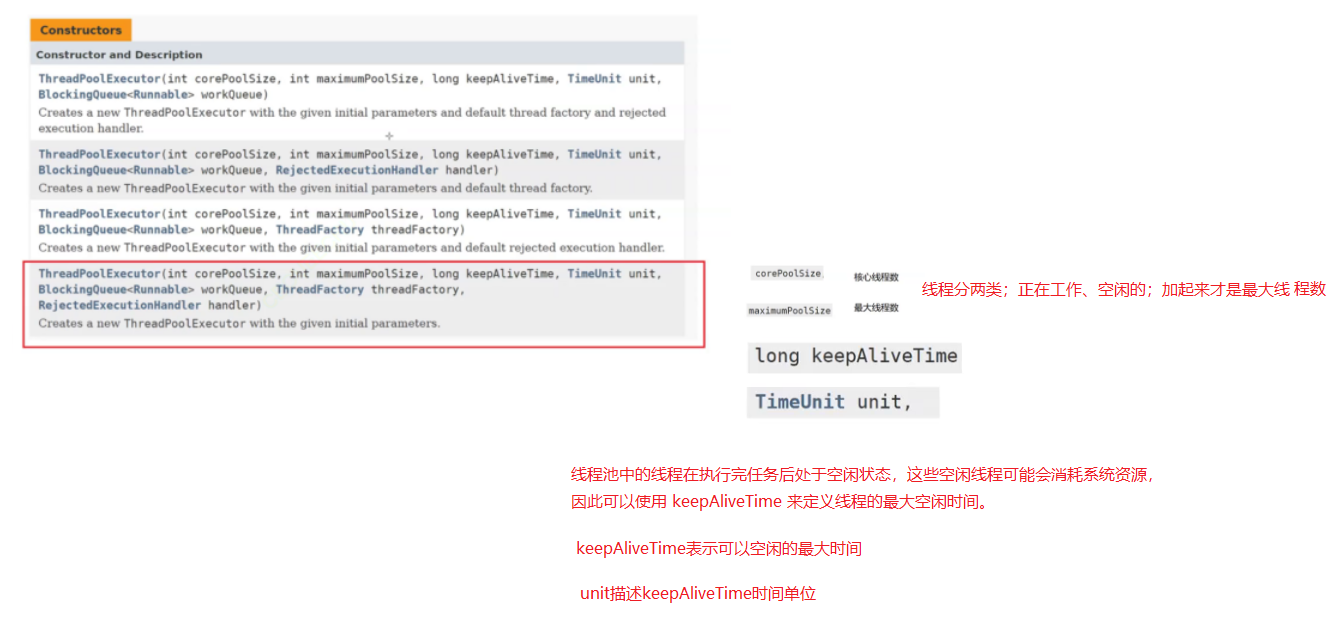
ThreadPoolExecutor提供了更多的可选参数,可以进一步细化线程池行为的设定;后续再详细介绍;以及自定义的定时器、线程池的实现。
线程数目确定
1:CPU每个线程要执行的任务都是狂转CPU(进行一系列算术运算)此时线程池线程数多也不应该超过 CPU 核数
2:IO密集型每个线程干的工作就是等待 0(读写硬盘,读写网卡,等待用户输入…)不吃 CPU此时这样的线程处于阻塞状态不参与 CPU 调度;你就可以设置多一点
实际中:实践出真知;通过测试/实验的方式;看看哪个效果最好