1.mq消息重复消费
rocketmq,kafka,rabbitmq等都保证at least one,至少一次,可能存在重复消费,要靠业务代码解决
原因:生产者发送重复消息or消费者消费重复消息

也就是说生产者在Broker响应时间后又发了一个(网络波动)

也就是说消费者走完业务逻辑了但是没有commit就挂了,会重复消费(服务挂掉,或者rocketmq进行rebalance)
2.mq消息堆积
MQ消息堆积是指在MQ队列中积累了大量的未消费消息,导致系统出现性能问题或者消息积压的现象。下面是一些常见的解决方案:
调整MQ参数:可以通过调整MQ参数来优化系统性能,例如增加队列的容量或调整消息的过期时间等。另外,也可以增加消费者线程的数量,以加速消息的消费速度。
定期清理过期消息:定期清理过期消息可以有效地减少MQ队列中的消息数量,避免消息堆积的现象。可以使用MQ提供的清理工具,或者自行编写定时清理脚本来完成。
使用流量控制:流量控制可以有效地限制消息的发送速率,避免消息过多导致的系统性能问题。可以在MQ中配置流量控制策略,根据系统实际情况设置合适的流量控制策略。
增加消费者节点:增加消费者节点可以有效地提高消息的消费速度,从而避免消息堆积的现象。可以根据系统的实际情况,适当增加消费者节点的数量,提高消费能力。
使用异步消息机制:使用异步消息机制可以提高消息的处理效率,避免消息堆积的现象。可以将MQ与异步消息框架结合起来使用,提高消息的处理速度。延迟队列,蓄水池之类的。
3.如何实现mq的幂等性(网站付款成功发货,使用mq做异步通知发货)
来处理重复mq的重复消费问题
幂等:同样的参数或者数据去调用同一个接口,无论重复调用多少次,总能保证数据的业务正确性,不能出错,这就是接口的幂等性
具体业务的解决方法:

4.log,debug,warn,error,fatal怎么用
debug 级别最低,可以随意的使用于任何觉得有利于在调试时更详细的了解系统运行状态的东东;
info 输出信息:用来反馈系统的当前状态给最终用户的;
后三个,警告、错误、严重错误,这三者应该都在系统运行时检测到了一个不正常的状态。
warn, 可修复,系统可继续运行下去;
Error, 可修复性,但无法确定系统会正常的工作下去;
Fatal, 相当严重,可以肯定这种错误已经无法修复,并且如果系统继续运行下去的话后果严重。
5.java基础



前两个b都会拆箱成int形式,所以都是true
第三个拆不了,直接程序报错
两个都是Integer才会使用常量池,而且要在-128 - 127中
6.效率问题
ArrayList a,b;HashSet c,d ;a,b,c,d各自有100w元素。
a.contain(b);c.contian(d);
hashset要比arraylist快得多
7.索引问题
1.user age varchar
select * from user where age =1 走不走索引
2.select * from user where id = 1走不走索引
3.select * from user where id in ( 1,2 )走不走索引
4.select * from user where id in ( 1,200 )走不走索引
1.隐式类型转换不走索引
2.主键走索引
3.in通常是走索引的,当in后面的数据在数据表中超过30%(上面的例子的匹配数据大约6000/16000 = 37.5%)的匹配时,会走全表扫描
8.java中用什么操作redis
jedis:简单,线程不安全,手动管理连接池
spring data redis:集成spring框架,不用管理连接池;api不全面
redisson(线程安全,分布式锁):线程安全,api复杂
lettuce(支持sentinel cluster):支持异步和响应式,api复杂
9.redis中的大value会有什么影响
大 Value
由于 Redis 是单线程运行的,如果一次操作的 value 很大会对整个 redis 的响应时间造成负面影响,因为 Redis 是 Key - Value 结构数据库,大 value 就是单个 value 占用内存较大。
Redis使用过程中经常会有各种大Value 的情况:
单个简单的key存储的value很大
hash, set,zset,list 中存储过多的元素(以万为单位)
由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆。
大 Value 会造成哪些故障:
数据倾斜问题:大 Value 会导致集群不同节点数据分布不均匀,造成数据倾斜问题,大量读写比例非常高的请求都会落到同一个 redis server 上,该 redis 的负载就会严重升高,容易打挂。
QPS 倾斜:分片上的 QPS 不均。
大 Value 会导致 Redis 服务器缓冲区不足,造成 get 超时。
由于值太大而过大,会对性能产生较大影响。读取值时,其他请求处于等待状态。如果该值占用太多内存,则读取速度会很慢。
大 Value,有些 key 访问 QPS 虽然不高,但是由于 value 很大,造成网卡负载较大,网卡流量被打满,单台机器可能出现千兆 / 秒,IO 故障。
超级大的一个Value存到redis中去, 这样其实不好, 我们可以把value进行压缩
10.redis的分布式锁
方案一:SETNX + EXPIRE
方案二:SETNX + value值是(系统时间+过期时间)
方案三:使用Lua脚本(包含SETNX + EXPIRE两条指令)
方案四:SET的扩展命令(SET EX PX NX)
方案五:SET EX PX NX + 校验唯一随机值,再释放锁
方案六: 开源框架:Redisson
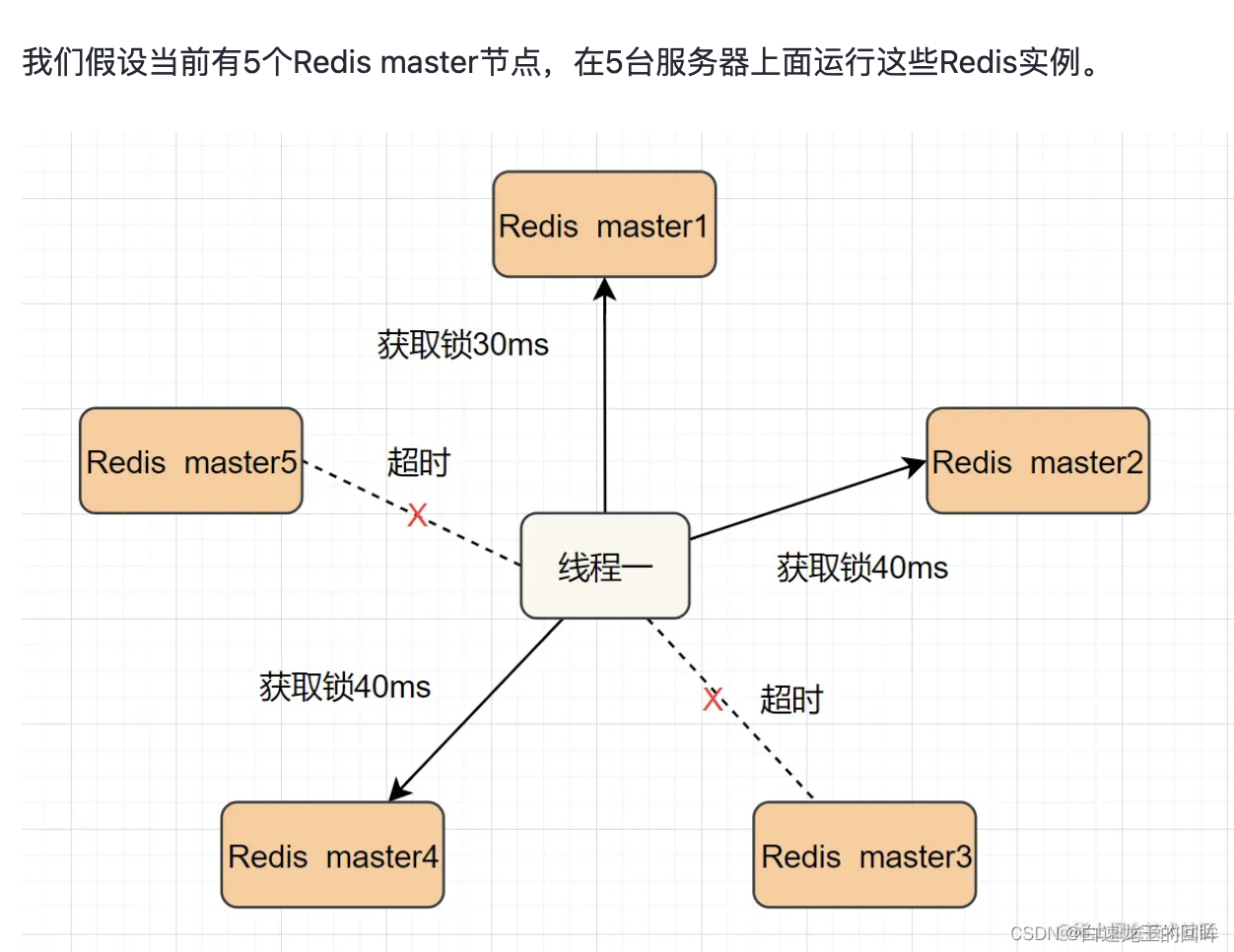
方案七:多机实现的分布式锁Redlock
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁
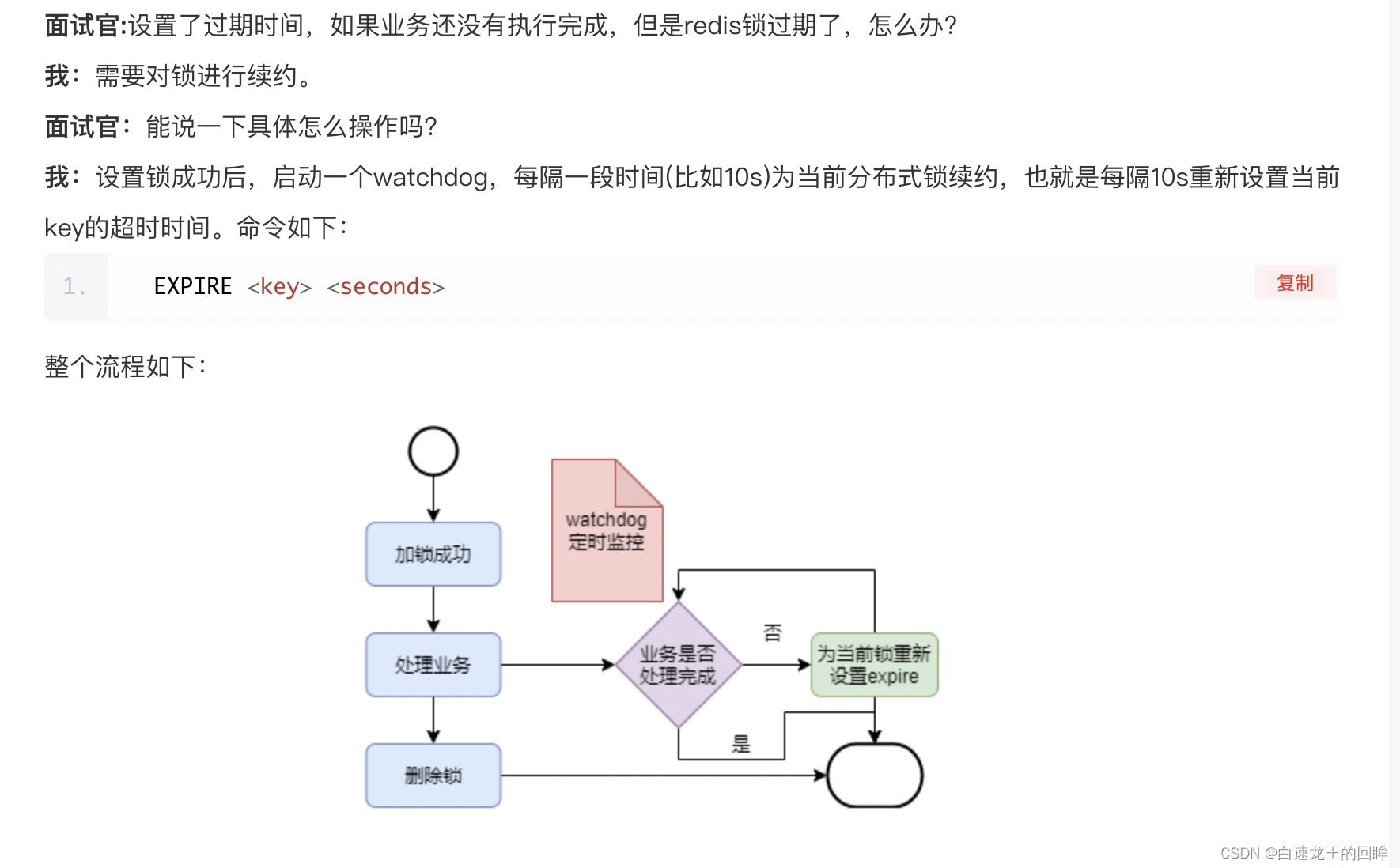
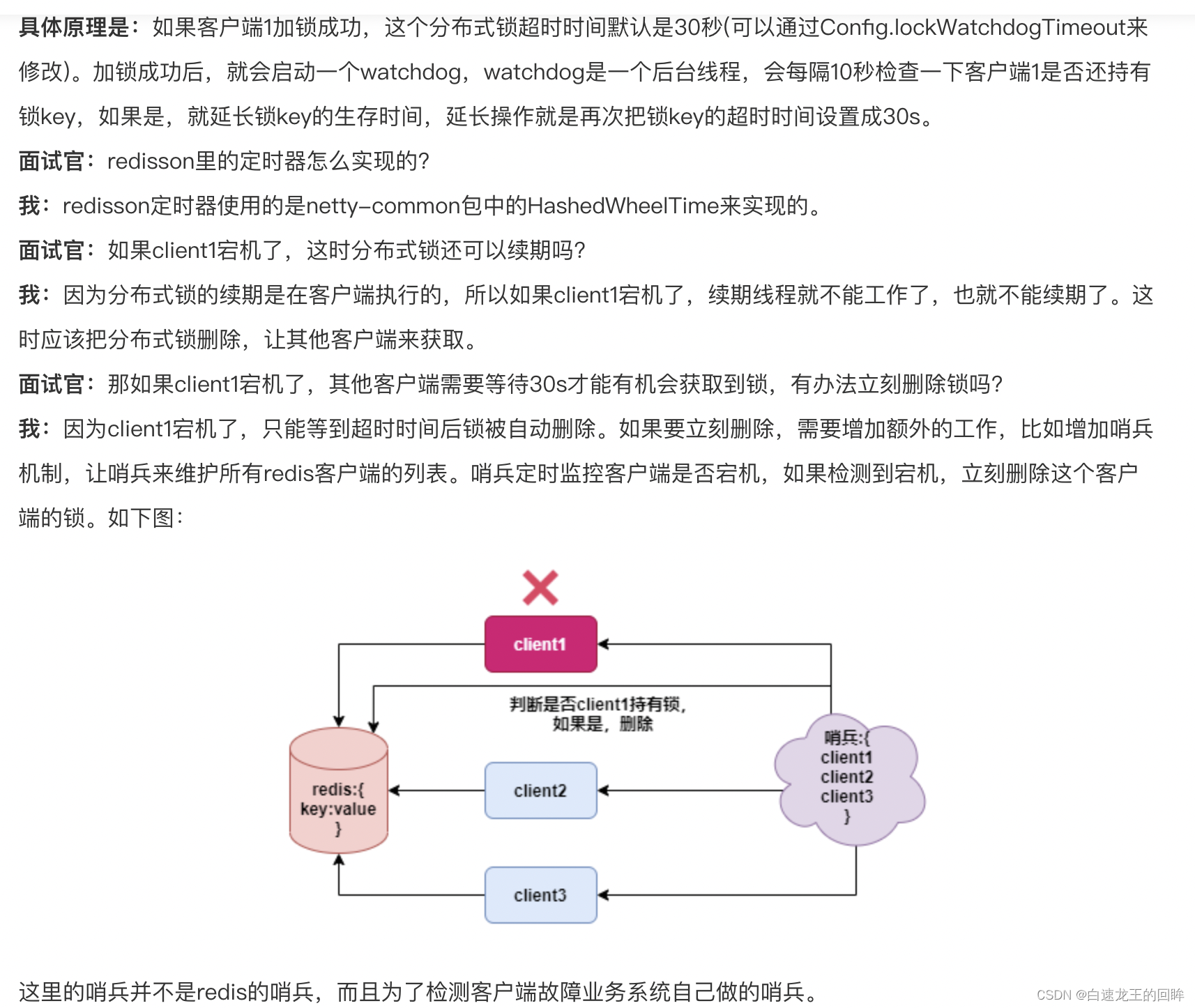
11.redis的锁设置了过期,但是业务没到期,怎么使用watchdog?