# encoding: utf-8
# 版权所有 2023 涂聚文有限公司
# 许可信息查看:
# 描述:
# Author : geovindu,Geovin Du 涂聚文.
# IDE : PyCharm 2023.1 python 311
# Datetime : 2023/9/17 5:40
# User : geovindu
# Product : PyCharm
# Project : LukfookLeaveCalculation
# File : ExportExcel.py
# explain : 学习import openpyxl as openws
import pandas as pd
import numpy as np
import pandasql
import os
import sys
import Common.Utils
import BLL.EmpLoyeeHolidaysGet
import Model.Employee
import Model.HolidayList
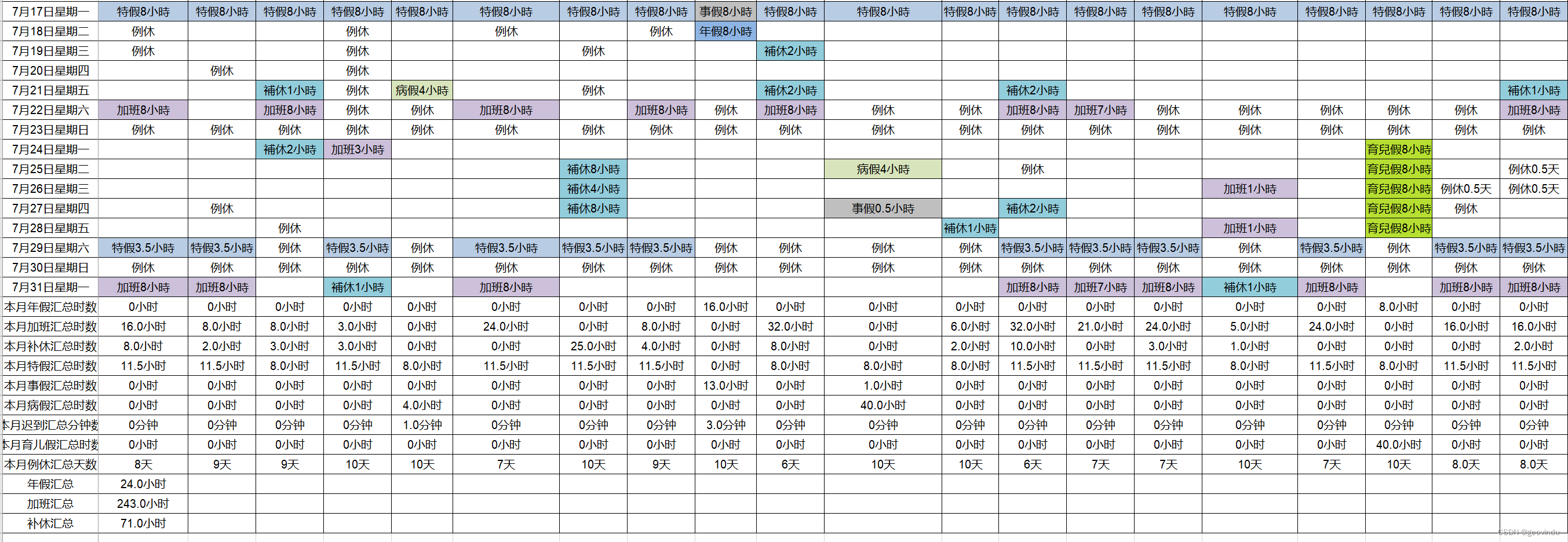
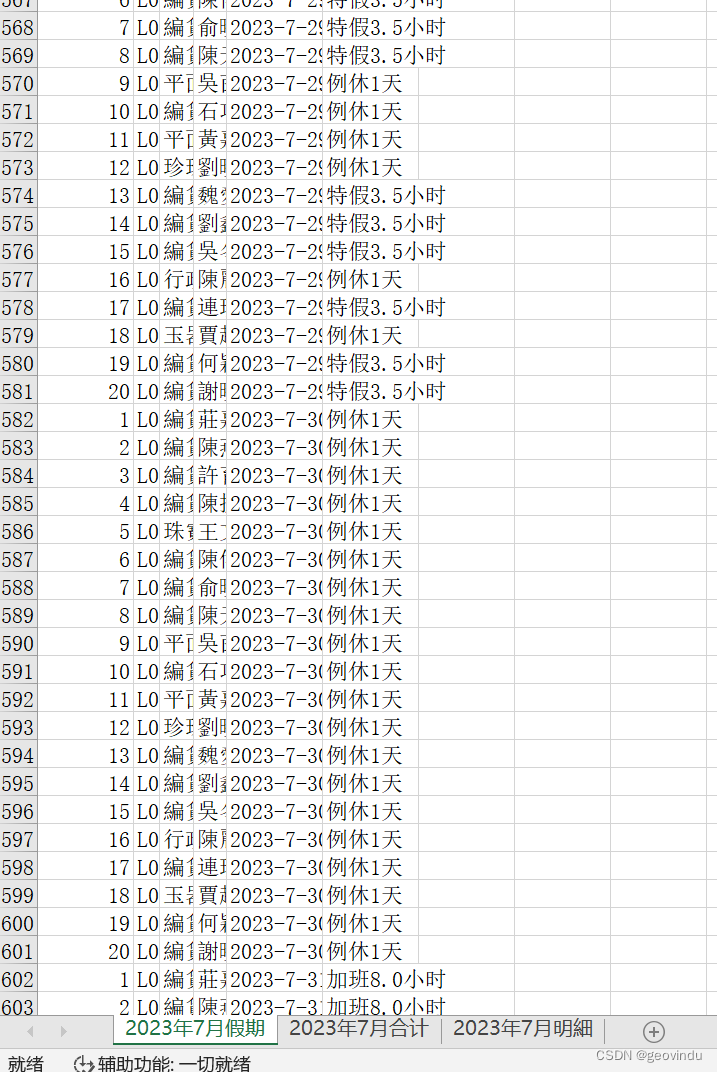
from openpyxl import load_workbookclass ExportExcelFile(object):"""输出处理好的EXCEL文件"""def __init__(self):self.sourcefile=""self.newfile=""def exportFile(self,sourcefile:str,newfile:str):"""文件处理,:param sourcefile:源文件:param newfile:新文件:return:None"""unstr = Common.Utils.Utils()thbll = BLL.EmpLoyeeHolidaysGet.EmpLoyeeHolidaysGet()dataframe1 = pd.read_excel(sourcefile)datarowcol = dataframe1.shapeexcelRows = datarowcol[0] #得玻行excelColumns = datarowcol[1] #得到列titls = dataframe1.columns.to_list()year = thbll.getYear(titls[1])dmps = []# 姓名,工号,序号,部门 0行至3行为员工资料 第一行为标题,不算行的内容 可以切片方式GET数据# 序号idlist = []dataId = dataframe1.loc[0:0]for idx, datadd in dataId.iterrows():#print("[{}]: {}".format(idx, datadd))idlist = datadd.to_list()for idd in range(1, len(idlist)):# employvee=Model.Employee.employee()# employvee.EmployeeId=idd# dmps.append(employvee)print(idd)# 工号nolist = []dataNo = dataframe1.loc[1:1]for idx, dataoo in dataNo.iterrows():#print("[{}]: {}".format(idx, dataoo))nolist = dataoo.to_list()#print("*******工号******")# 部门deplist = []dataDep = dataframe1.loc[2:2]for idx, datapp in dataDep.iterrows():#print("[{}]: {}".format(idx, datapp))deplist = datapp.to_list()#print("*******部门******")# 姓名namelist = []dataName = dataframe1.loc[3:3]for idx, datann in dataName.iterrows():#print("[{}]: {}".format(idx, datann))namelist = datann.to_list()#print("*******姓名******")for i in range(1, len(namelist)):employvee = Model.Employee.employee()employvee.EmployeeId = idlist[i]employvee.EmployeeNo = nolist[i]employvee.EmployeeName = namelist[i]employvee.EmployeeDep = deplist[i]dmps.append(employvee)for ob in dmps:print(ob.EmployeeId, ob.EmployeeNo, ob.EmployeeName, ob.EmployeeDep)AnnualLeave=0Overtime=0DeferredHoliday=0SpecialLeave=0PersonalLeave=0SickLeave=0ChildcareLeave=0LateTime=0RegularHoliday=0# 内容mon=0day=0getdate=[]getHolidays=[]readrows=(excelRows-1)-3 #索此值从零开始,所以总数减一,再减三行统计的data4 = dataframe1.loc[4:readrows] #第四行开始内空getrow=1emplist=[]for idx, datavalue in data4.iterrows():#strnum=Common.Utils.Utils.getAnnualLeave(data)employs = Model.Employee.employee()#print("[{}]: {}".format(idx, datavalue))slist=datavalue.tolist()hbll=BLL.EmpLoyeeHolidaysGet.EmpLoyeeHolidaysGet() #病假4小時_x000D_事假0.5小時 未处理#print(slist) #这是读取第1列的日期数据for i in range(0, 1):strvalue = str(slist[i])#print("get value:", strvalue.replace('nan', ''), type(strvalue))mon=hbll.getMonth(strvalue)day=hbll.getDay(strvalue)#print("*******时间************",mon,day)getdate.append(str(year)+'-'+str(mon)+'-'+str(day))#print(slist)hid=1for i in range(1,len(slist)):getdd = Model.HolidayList.HolidayList()getdd.HolidayDate = str(year) + '-' + str(mon) + '-' + str(day)#strvalue=str(slist[i]).replace(r'\s+|\\n', ' ', regex=True) _x000D_#isnan=np.isnan(slist[i])#if(isnan):strvalue = str(slist[i]).replace('_x000D_', ' ') # 规换单元格的换行符,否则处理不了正确数据#strvalue = str(slist[i]).replace('nan', ' ')#print("get value:",strvalue.replace('nan',''),type(strvalue))strnums = hbll.getHolidays(strvalue) # float str#print("hid:",hid)getdd.HolidayEmpId = hidif(len(strnums)>0):for sn in range(len(strnums)):#print("str:",strnums[sn].HolidayId,strnums[sn].HolidayName,strnums[sn].WorkTime)if strnums[sn].HolidayId==6:AnnualLeave=AnnualLeave+strnums[sn].WorkTimeif strnums[sn].HolidayId == 4:Overtime=Overtime+strnums[sn].WorkTimeif strnums[sn].HolidayId == 3:DeferredHoliday = DeferredHoliday + strnums[sn].WorkTimeif strnums[sn].HolidayId == 2:SpecialLeave=SpecialLeave+strnums[sn].WorkTimeif strnums[sn].HolidayId == 5:PersonalLeave=PersonalLeave+strnums[sn].WorkTimeif strnums[sn].HolidayId == 7:SickLeave=SickLeave+strnums[sn].WorkTimeif strnums[sn].HolidayId == 8:ChildcareLeave=ChildcareLeave+strnums[sn].WorkTimeif strnums[sn].HolidayId == 9:LateTime=LateTime+strnums[sn].WorkTimeif strnums[sn].HolidayId == 1:RegularHoliday=RegularHoliday+strnums[sn].WorkTimegetdd.Holdays = strnumselse:#print("0")getdd.Holdays =[]hid+=1getHolidays.append((getdd))employs.EmployeeHolidays=getHolidaysemploys.EmployeeActiveDate=getdategetrow+=1# getHolidays.append(strnums)#print("类型:", type(datavalue))emplist.append((employs))flist=[]getIdAnnualLeave=[]fdata=('ID','工号','部门','姓名','日期','假期')flist.append(fdata)#print("date:",getdate,len(getdate))#print(len(getHolidays))#for dddd in emplist:#print(dddd.EmployeeId,len(dddd.EmployeeHolidays)) #emplist[0].EmployeeHolidays:for sd in emplist[0].EmployeeHolidays:fdata=(sd.HolidayEmpId,thbll.getEmplee(dmps,sd.HolidayEmpId)[0],thbll.getEmplee(dmps,sd.HolidayEmpId)[1],thbll.getEmplee(dmps,sd.HolidayEmpId)[2],sd.HolidayDate,thbll.getHoliday(sd.Holdays))flist.append(fdata)#ananuaint=thbll.getEmpleeIdAnnualLeave(sd.HolidayEmpId,emplist[0].EmployeeHolidays)#getIdAnnualLeave.append(ananuaint)#print(sd.HolidayEmpId,thbll.getEmplee(dmps,sd.HolidayEmpId)[0],thbll.getEmplee(dmps,sd.HolidayEmpId)[1],thbll.getEmplee(dmps,sd.HolidayEmpId)[2],sd.HolidayDate,thbll.getHoliday(sd.Holdays))#print("**************")#print(getIdAnnualLeave)#print("*************",year,"年",mon,"月","考勤合计*************")#,day,"日"#print("年假合计:",AnnualLeave,"小时,加班合计:",Overtime,"小时,补休合计:",DeferredHoliday,"小时,特假合计:",SpecialLeave,"小时")#print("事假合计",PersonalLeave,"小时,病假合计:",SickLeave,"小时,迟到合计:",LateTime,"分钟,育儿假合计:",ChildcareLeave,"小时")#print("例休:",RegularHoliday,"天")#print("*****************************************************************")#年假for sd in emplist[0].EmployeeHolidays:ananuaint=[sd.HolidayEmpId,thbll.getHolidayAnnualLeave(sd.Holdays)]getIdAnnualLeave.append(ananuaint)#print(getIdAnnualLeave)dd=thbll.getEmpleeIdAnnualLeave(1,getIdAnnualLeave)#print("年假 id=1 sum:",dd)#加班getIDOvertimm=[]for sd in emplist[0].EmployeeHolidays:overtimeint=[sd.HolidayEmpId,thbll.getHolidayOvertime(sd.Holdays)]getIDOvertimm.append(overtimeint)#print(getIDOvertimm)dov=thbll.getEmpleeIdOvertime(1,getIDOvertimm)#print("加班 id=1 sum:",dov)#补休getIdDeferred=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getHolidayDeferred(sd.Holdays)]getIdDeferred.append(defint)#print(getIdDeferred)doef=thbll.getEmpleeIdeferred(1,getIdDeferred)#print("补休 id=1 sum:",doef)#特假 SpecialLeavegetIdSpecialLeave=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getSpecialLeave(sd.Holdays)]getIdSpecialLeave.append(defint)#事假getIdPersonalLeave=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getPersonalLeave(sd.Holdays)]getIdPersonalLeave.append(defint)#病假getIdSickLeave=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getSickLeave(sd.Holdays)]getIdSickLeave.append(defint)#迟到getIdLateTime=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getLateTime(sd.Holdays)]getIdLateTime.append(defint)#育儿假getIdChildcareLeave=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getChildcareLeave(sd.Holdays)]getIdChildcareLeave.append(defint)#例休getIdRegularHoliday=[]for sd in emplist[0].EmployeeHolidays:defint=[sd.HolidayEmpId,thbll.getRegularHoliday(sd.Holdays)]getIdRegularHoliday.append(defint)taum= []tva=("名称","合计")taum.append(tva)tva=("年假", str(AnnualLeave) + "小时")taum.append(tva)tva=("加班",str(Overtime)+"小时")taum.append(tva)tva=("补休",str(DeferredHoliday)+"小时")taum.append(tva)tva=("特假",str(SpecialLeave)+"小时")taum.append(tva)tva=("事假",str(PersonalLeave)+"小时")taum.append(tva)tva=("病假",str(SickLeave)+"小时")taum.append(tva)tva=("迟到",str(LateTime)+"分钟")taum.append(tva)tva=("育儿假",str(ChildcareLeave)+"小时")taum.append(tva)tva=("例休",str(RegularHoliday)+"天")taum.append(tva)sheetname1 = str(year) + "年" + str(mon) + "月假期"writer = pd.ExcelWriter(sheetname1+"明細.xlsx") # 这里是创建了可写入不同sheet的文件text1 = pd.DataFrame(flist,columns=['ID','工号','部门','姓名','日期','假期'])text1.to_excel(writer, sheet_name=sheetname1,header=0, index=False) # sheet命名为sheetname2=str(year)+"年"+str(mon)+"月合计"text2 = pd.DataFrame(taum) #,columns=['名称','合计']text2.to_excel(writer, sheet_name=sheetname2, header=0, index=False) # sheet命名为text3=dataframe1;sheetname3=str(year) + "年" + str(mon) + "月明細"text3.to_excel(writer,sheet_name=sheetname3, header=0, index=False)#writer.sheets.update()writer.close()dataframe2 = openws.load_workbook(sourcefile)# Define variable to read sheetsheet = dataframe2.activesetrow=datarowcol[0] #总共行setcol=datarowcol[1] #总共列#每个人的合计for idd in range(1, len(idlist)):sheet.cell(row=setrow - 1, column=1+idd).value = str(thbll.getEmpleeIdAnnualLeave(idd,getIdAnnualLeave)) + "小时"sheet.cell(row=setrow - 0, column=1+idd).value = str(thbll.getEmpleeIdOvertime(idd,getIDOvertimm))+"小时"sheet.cell(row=setrow + 1, column=1+idd).value = str(thbll.getEmpleeIdeferred(idd,getIdDeferred))+"小时"sheet.cell(row=setrow + 2, column=1 + idd).value = str(thbll.getEmpleeIdeferred(idd, getIdSpecialLeave)) + "小时"sheet.cell(row=setrow + 3, column=1 + idd).value = str(thbll.getEmpleeIdeferred(idd, getIdPersonalLeave)) + "小时"sheet.cell(row=setrow + 4, column=1 + idd).value = str(thbll.getEmpleeIdeferred(idd, getIdSickLeave)) + "小时"sheet.cell(row=setrow + 5, column=1 + idd).value = str(thbll.getEmpleeIdeferred(idd, getIdLateTime)) + "分钟"sheet.cell(row=setrow + 6, column=1 + idd).value = str(thbll.getEmpleeIdeferred(idd, getIdChildcareLeave)) + "小时"sheet.cell(row=setrow + 7, column=1 + idd).value = str(thbll.getEmpleeIdeferred(idd, getIdRegularHoliday)) + "天"sheet.cell(row=setrow + 2, column=1).value = "本月特假汇总时数"sheet.cell(row=setrow + 3, column=1).value = "本月事假汇总时数"sheet.cell(row=setrow + 4, column=1).value = "本月病假汇总时数"sheet.cell(row=setrow + 5, column=1).value = "本月迟到汇总分钟数"sheet.cell(row=setrow + 6, column=1).value = "本月育儿假汇总时数"sheet.cell(row=setrow + 7, column=1).value = "本月例休汇总天数"#合部汇总sheet.cell(row=setrow + 8, column=1).value = "年假汇总"sheet.cell(row=setrow + 9, column=1).value = "加班汇总"sheet.cell(row=setrow + 10, column=1).value = "补休汇总"sheet.cell(row=setrow + 8, column=2).value = str(AnnualLeave) + "小时"sheet.cell(row=setrow + 9, column=2).value = str(Overtime)+"小时"sheet.cell(row=setrow + 10, column=2).value = str(DeferredHoliday)+"小时"dataframe2.save(newfile) #创建新文件调用:
export=BLL.ExportExcel.ExportExcelFile()export.exportFile('2023年7月.xlsx','2023年7月new.xlsx')