一、 One-stage目标检测算法
- 使用CNN卷积特征
- 直接回归物体的类别概率和位置坐标值(无region proposal)
- 准确度低,速度相对two-stage快
二、One-stage基本流程

输入图片------对图片进行深度特征的提取(主干神经网络)------对目标的位置进行定位和分类,One-stage和Two-stage的区别就在于是否包含了候选区域推荐的过程。Two-stage流程图如下:
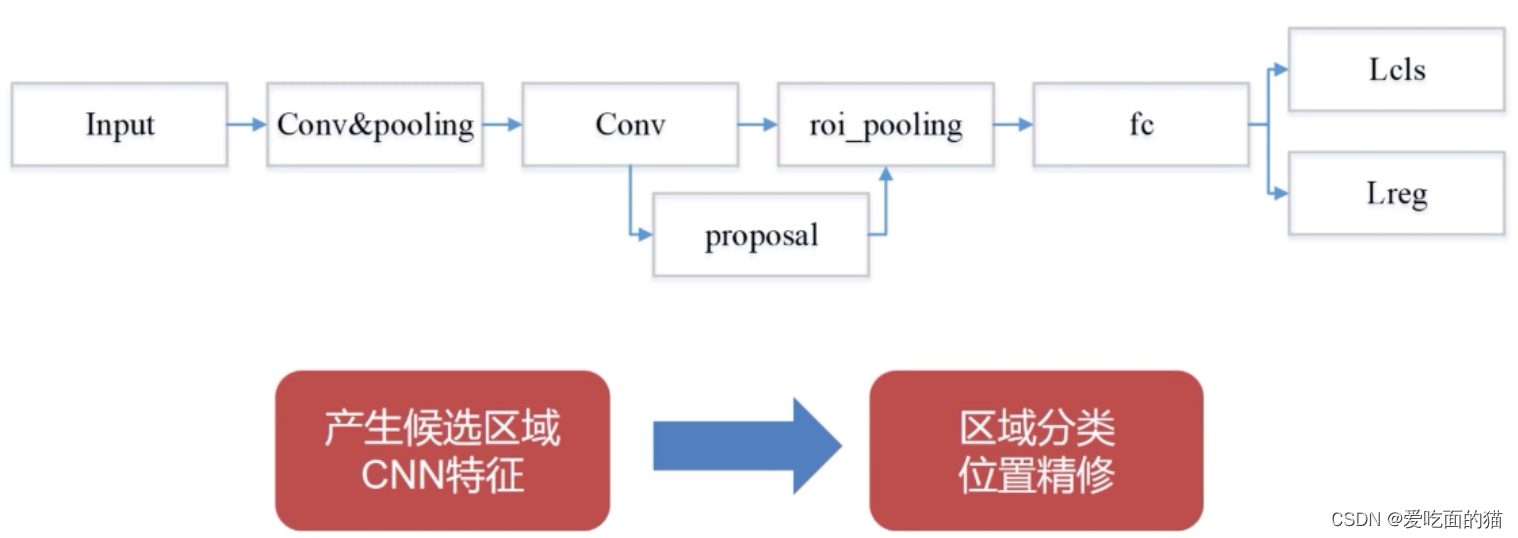
三、One-stage常见算法
One-stage常见算法
- YOLOV1/V2/V3
- SSD/DSSD等
- Retina-Net
- …
 四、One-stage的核心组件
四、One-stage的核心组件
1、One-stage的两个核心组件
- CNN网络(主干网络)
- 回归网络
2、主干CNN网络设计原则
- 从简单到复杂,再从复杂到简单的卷积神经网络
- 多尺度特征融合的网络
- 更轻量级的CNN网络
3、回归网络
回归网络将通过CNN主干网络卷积层获取的feature maps作为回归网络的输入,通过回归网络主要完成了区域回归、目标区域类别的判定。
回归网络中有两个主要内容:
- 回归区域(置信度、位置、类别)
- Anchor机制(SSD)
回归区域(置信度、位置、类别)
通过回归网络直接输出最终目标的bounding box位置信息。这里的位置信息就是下图中的红框和蓝框的位置信息,这都是区域回归最终输出结果。所以说回归网络是目标检测算法One-stage中的重要组部分。

图中右侧图片里红色小框中有目标区域置信度会更高。其他小框的置信度会低。
置信度:是指是否存在目标,如果存在,表示代表目标区域,如果不是目标表示是背景区域
类别:表示是否是目标区域,一般用概率表示,概率高表示是目标区域。类别主要是通过对anchor box的回归得到。
位置:图像的位置,主要通过对anchor box的回归得到。
Anchor机制:
找到不同的推荐区域(属于Two-stage的RPN网络的核心组件,One-stage则没有此组件,One-stage和Two-stage的区别在于是否有RPN推荐区域提取,但不影响One-stage使用RPN的思想,如:Anchor机制)在SSD目标回归(左边),经过主干网络卷积之后得到的feature map,考虑feature map中的每一个点都是一个Anchor,基于当前的Anchor来提取不同尺度的长宽比,对于不同尺度的长宽比所对应的目标区域,利用此目标区域来进行位置的回归和类别的判定。
yolo没有Anchor机制(右边)用的是各自坐标(左上右下)
4、回归网络预测过程(Yolo)

过程:对整个图片进行划分,S * S 的格子,针对每个网格分别预测当前这个网格为中心的目标区域的位置信息(中上部图),预测出Bounding boxes和置信度,此外还会对每个格子预测目标类别的概率分布值(中下图),(B *5+C)*S *S 维的向量(最终输出) (B:每个格子预测多少的bouding boxes数;5:四个坐标加一个置信度;C:类别),最终的输出就对应到了这里的bouding box坐标的位置,以及bouding box置信度和对于每一个格子所对应的类别的概率分布,在拿到这些值之后,再利用每一个网格预测的类别信息和bouding box 所对应的置信度进行相乘,就能够拿到每一个bouding box所对应的类别置信度信息,利用类别置信度信息再结合NMS算法,对预测出的所有的Bouding box进行筛选过滤,得到最终预测结果。这个过程也是yolo算法在拿到回归网络预测结果之后得到最终的输出所经过的运算过程。实际上对于SSD和faster RNN这样的检测网络,最终输出的bouding box本身预测出的概率分布,可直接用于NMS算法所需要的类别置信度分数,在yolo算法中需要额外将中间两个图的结果进行融合(两个置信度相乘得到最终能分数置信度,最为NMS输入)。
yolo是纯粹的端到端的回归网络,检测效率会更高。但是在yolo算法中通长使用各自划分,认为每一个格子点都是目标检测的中心点,有可能我们划分的格子都不是目标的中心点,因此基于中心点预测目标区域所对应的bouding box信息的前提假设会导致我们预测出来的检测相比于SSD,faster rcnn准确率低。再有,由于在yolo中划分格子的时候会忽略掉其中的小物体,比如说鸟类识别检测鸟群,可能会漏检。但整体检测速度快。
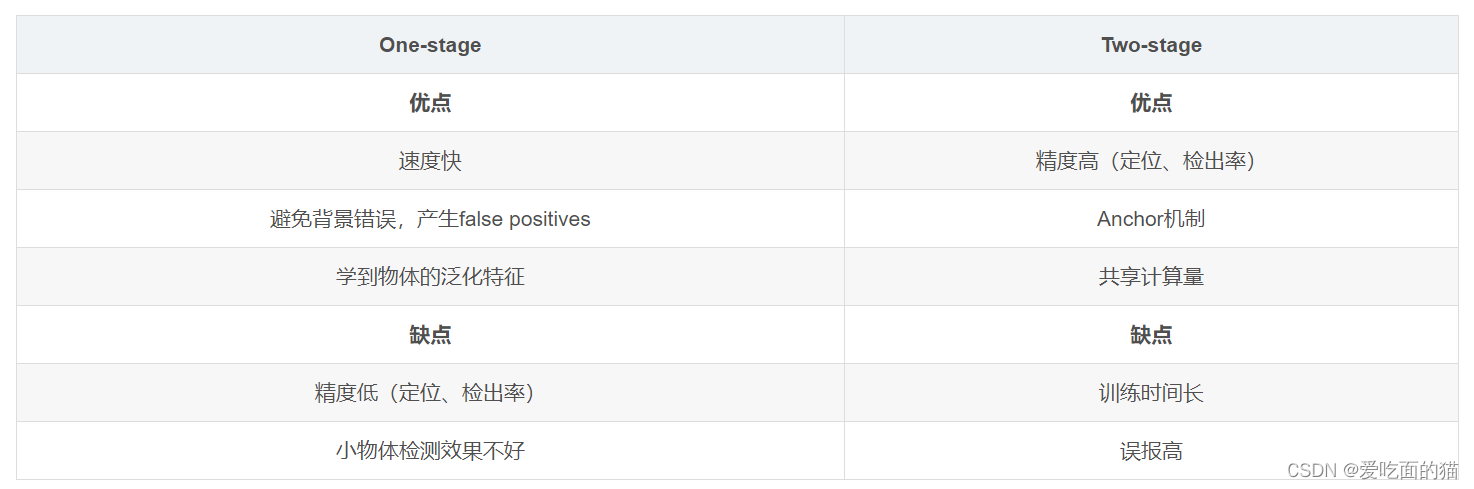
五、One-stage VS Two-stage
上一篇:04目标检测-Two-stage的目标检测算法