目录
集群最少三个主节点的原因
为什么是三个?
为什么是奇数?
16384个槽和1000个主节点
集群最少三个主节点的原因
https://redis.io/docs/management/scaling/
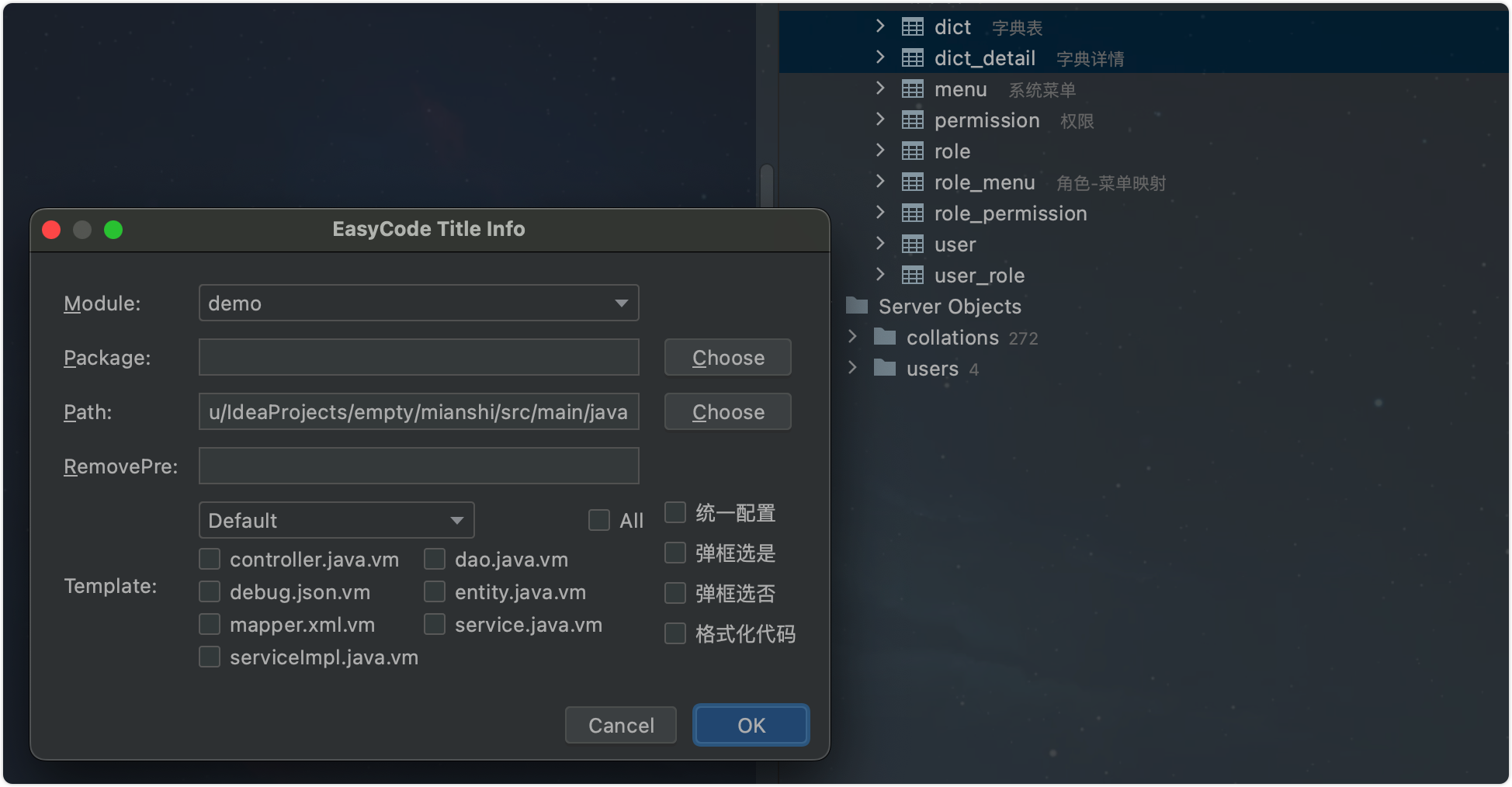
官网建议,搭建 redis 集群最少三主三从。
但是这么做是出于什么考虑呢?
https://worktile.com/kb/p/34708
https://blog.csdn.net/qq_35549286/article/details/127057374
借鉴这位的解答
为什么是三个?
cluster各节点之间需要互相通信确认对方是否存活。
假设有A、B两个节点,
B发现联系不上A,是不能确定A和B谁出了问题的,假设集群中还有一个C节点的话,
如果B、C可以互相联系,但是都联系不上A,
那么这时候就可以确定A出问题了,需要把A从集群中踢出去。
为什么是奇数?
集群可用原则:可用节点数量>集群总节点数量的二分之一,节点数量为奇数个是出于节省资源的考虑。
因为不管是四个还是三个节点,一旦挂了两个,整个集群都是不可用的。
即为了节省资源和节点通信考虑,集群的节点数量为奇数,即
y=2x+1,x为正整数,y为主节点数
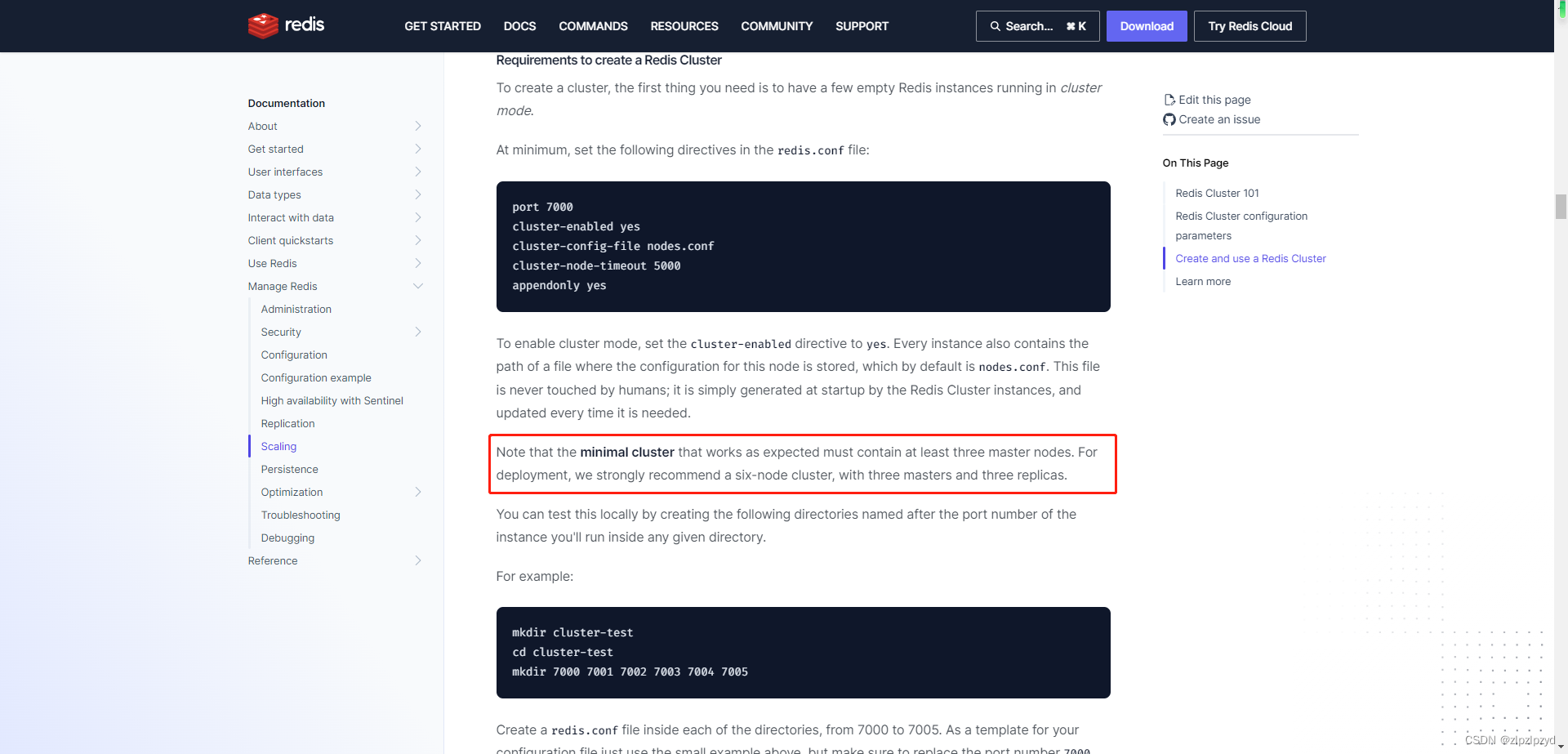
16384个槽和1000个主节点
https://redis.io/docs/reference/cluster-spec/#overview-of-redis-cluster-main-components
https://redis.io/docs/management/scaling/#redis-cluster-101

crc16算法 产生的结果是 2^16,即65536,但是取用了 16384,是出于什么原因?
https://github.com/redis/redis/issues/2576
github上回复了。
https://blog.csdn.net/qq_35971258/article/details/126839944
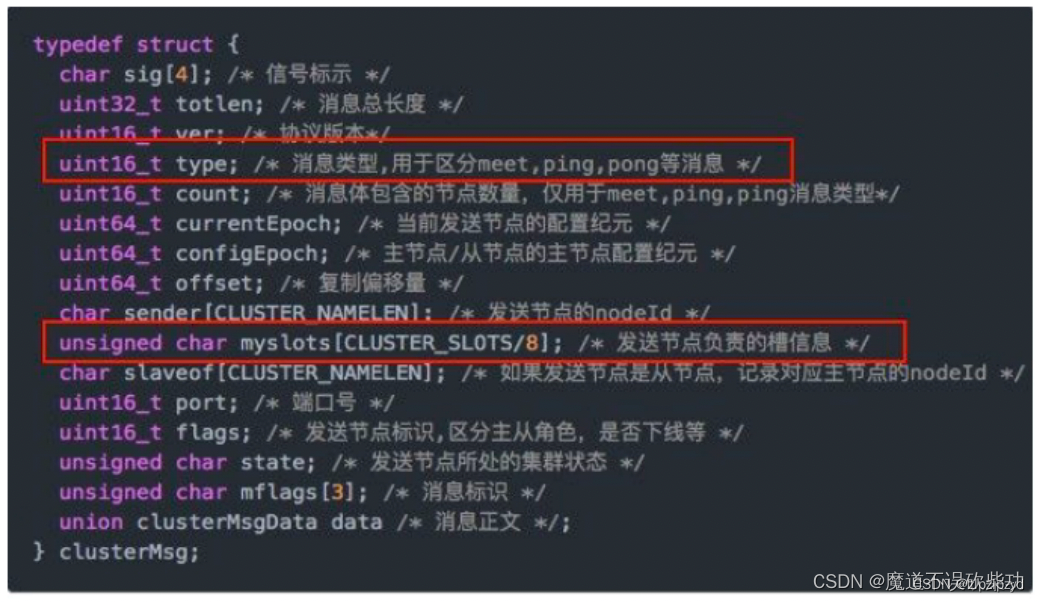
由于集群之间基于Gossip协议进行数据发送,总发送数据次数计算方式如下
n*(n-1),n为主节点数
由于节点不给自己发数据,因此一个节点对其他节点发送数据次数为 n-1。这是极端的情况,这样处理方便计算。redis中Gossip协议是随机取维护的节点列表中的5个中的一个进行数据发送。
按照上面的文章的意思,节点之间传递ping数据包如果是 16384,myslots数组会是2048个字节,即2KB,如果是65536,即8KB,如果1000个主节点相互传输数据,总数据量为1000*999*2KB=1998000KB。
由于网络传输的单位是bit,转换单位就是1998000*1024*8=16,367,616,000,网卡单位和带宽是 bit,但是计算机表示数据使用的是字节,例如接入的带宽是 1gb,实际上一秒最多传输 128 MB的数据。
1gb 对应的是 bit 总数是1,073,741,824,16,367,616,000/1,073,741,824≈15.24,即16gb的网卡才能满足要求,但是一般的服务器网卡达不到这么高,如果有这些节点相互发送数据会造成网络拥堵,这还只是算了主节点,没算副本节点,更不用说8KB的数据了。
内存和cpu执行速度很快。集群的节点数多了这个时候性能瓶颈就在网络上了。所以,主节点数少且是大于3的奇数为好,具体节点数看业务实际情况处理。