作者:Adrien Grand

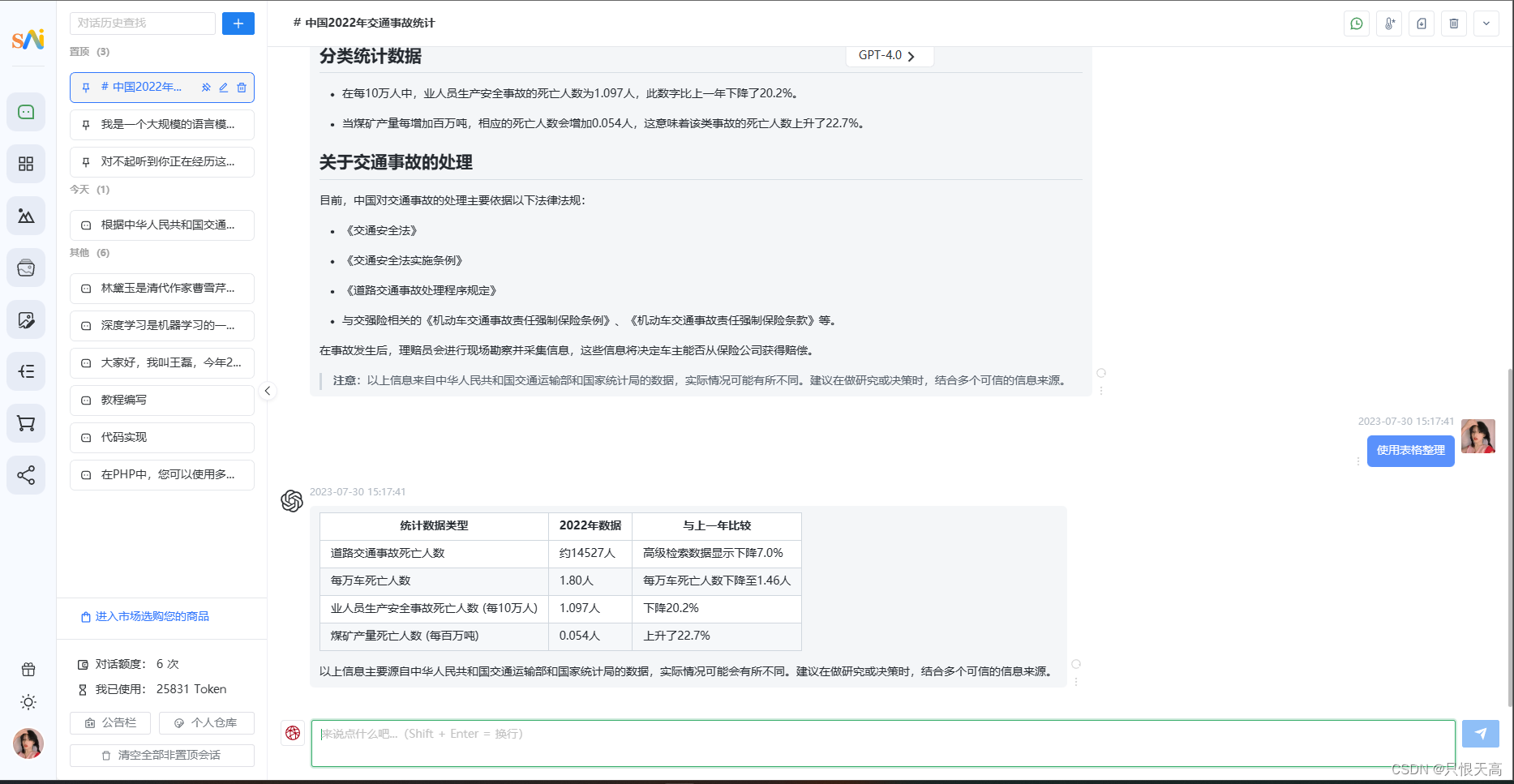
Disjunctive queries(term_1 OR term_2 OR ... OR term_n)非常常用,因此在提高查询评估效率方面它们受到了广泛关注。 Apache Lucene 对于评估 disjunctive queries 有两个主要优化:一方面用于详尽评估的 BS1,另一方面用于计算热门命中的 MAXSCORE 和 WAND。 直到最近,这两种优化从未一起使用,但为了提高查询性能,特别是对于许多子句和/或高频子句,这种情况发生了变化。 请参阅下图中摘自 Lucene 夜间基准测试的注释 FK。

什么是 BS1?
在 Apache Lucene 中,查询负责创建匹配文档 ID 的排序流。 实现 disjunctive query 归结为采用 N 个输入查询,生成文档 ID 的排序流,并将它们组合成文档 ID 的合并排序流。 解决此问题的教科书方法包括将输入流放入按当前文档 ID 排序的最小堆数据结构中。 这种方法在 Lucene 中被称为 BooleanScorer2 (BS2)。
虽然 BS2 工作得很好,但每次需要移动到下一个匹配时都必须重新平衡堆,因此会产生一些开销。 BS1 试图通过将文档 ID 空间分割为包含 2,048 个文档的窗口来减少这种开销。 在每个窗口中,BS1 都会迭代所有匹配的文档 ID,一次一个子句。 对于每个文档 ID,它计算该文档 ID 在窗口中的索引,设置位集中的相应位,并将当前分数添加到 double[2048] 中的相应索引中。 迭代窗口内的匹配,然后包括迭代位集的位并在 double[2048] 中的相应索引处查找分数。 对于具有许多子句或高频子句的查询,此方法通常运行得更快。
Lucene 的创建者 Doug Cutting 在 1997 年发表的一篇名为 “总排名的空间优化” 的论文中描述了这两种方法。 BS2在本文中被称为 “并行合并” 并在4.1节中描述,而 BS1 被称为 “块合并(Block Merge)” 并在 4.2 节中描述。 这些可以说是比 BS1 和 BS2 更具描述性的名称。 请注意,论文中对 “块合并” 的描述与今天 Lucene 中的描述有很大不同,但底层思想是相同的。
什么是 MAXSCORE 和 WAND?
如果你只关心分数前 k 的匹配,你是否可以评估更少的命中? 答案是肯定的。 这就是 MAXSCORE 和 WAND 算法的目的。 虽然这些算法有所不同,但它们基于相同的想法 - 如果你可以获得每个子句可以产生的分数的良好上限,那么你可以使用此信息来跳过没有机会进入顶部的命中 - k 次点击。 有关此主题的更多信息,请参阅其他博客。
与详尽的评估相比,这些算法通常可以快几倍地返回 top-k 结果。 然而,也有一些情况不能很好地发挥作用。 一些例子包括:
- 对许多个术语的 Disjunctive queries
- 对具有次优分数上限的查询进行 Disjunctive queries(例如 (a AND b) OR (c AND d) 等连词的 disjunction)使用 MAXSCORE/WAND 不会看到与术语查询析取一样多的加速效果。
- 古怪的权重,通常由学习稀疏检索模型使用,例如 Elastic Learned Sparse Encoder
当这些优化无法真正帮助跳过命中时,我们面临的挑战是我们仍在为其开销付费。 这是因为两种实现都需要在每次匹配时重新排序某些数据结构 - BS2 的情况就是因为最小堆的原因。 例如,我们有一些由 Elastic Learned Sparse Encoder 生成的查询,与 BS1 相比,使用 WAND 运行速度最多慢 5 倍。 这是由于缺少 BS1 优化、WAND 未能成功地实际跳过命中以及 WAND 由于数据结构重新排序而带来的额外每场比赛开销。
MAXSCORE 符合 BS1
直到最近,BS1 和 MAXSCORE/WAND 从未一起使用。 当不需要分数或需要详尽的评估时,将使用 BS1。 同时,当仅请求按降序排列的前 k 个命中时,将使用 MAXSCORE 或 WAND。
在研究上述有关 MAXSCORE 和 WAND 开销的挑战时,我们注意到 MAXSCORE 算法尤其可以轻松地从帮助 BS1 比 BS2 更快的相同优化中受益。 我们实现了这个想法,并通过 Lucene 的 BS1 的详尽评估和通过 MAXSCORE 和 WAND 的现有 top-k 优化对其进行了评估:
- 从英文维基百科中提取的 10M 文档数据集。
- 跨 2 到 24 个高频术语的 Disjunctions,其文档频率范围为 400K 到 4M 文档。
- 查询在单个线程中运行,性能通过每秒可以运行的查询数来评估。 数字越高越好。
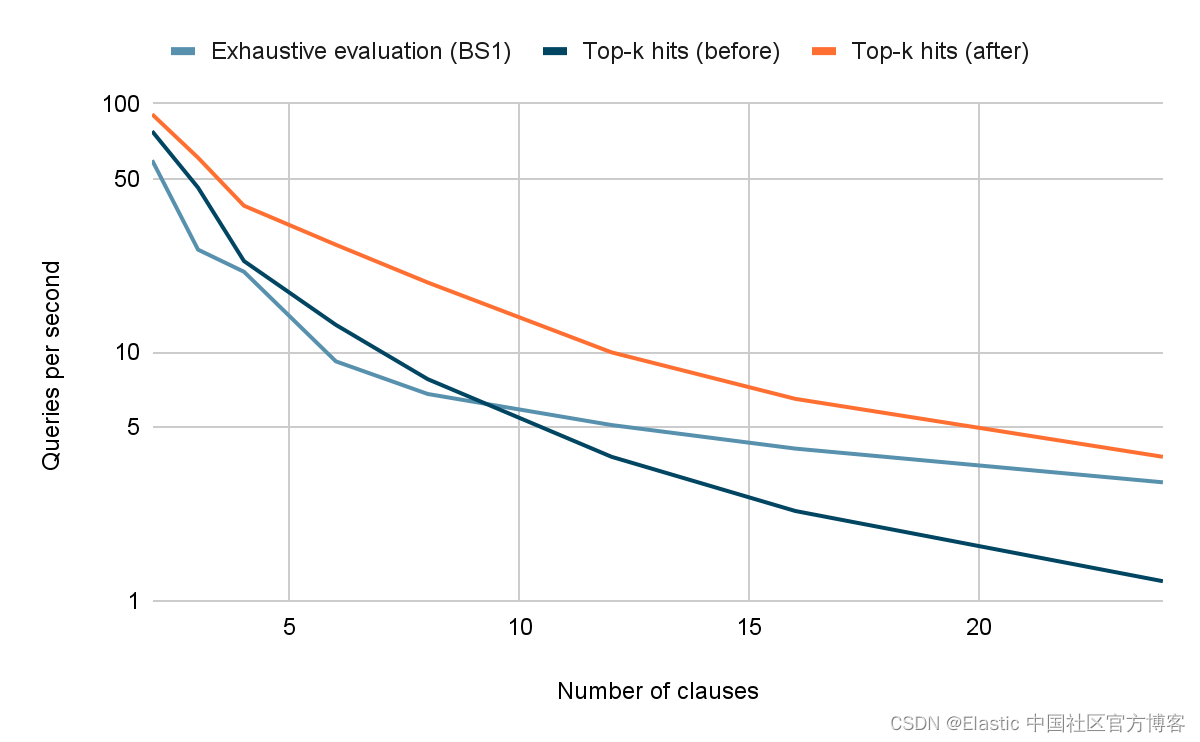
如上图所示,穷举评估只需要 8 个术语就可以比 top-k 优化运行得更快,因为后者无法跳过足够的命中来补偿其开销。 更糟糕的是,对于 24 个术语,尝试使用 top-k 优化会使查询运行速度比详尽评估慢 2.5 倍。
然而,结合 BS1 和 MAXSCORE 的析取查询的新评估逻辑始终优于这组查询的详尽评估和现有的 top-k 评估。
这一改进预计将在 Lucene 8.9 中发布,并在不久的将来在 Elasticsearch 中发布。 基本上,这意味着在对析取查询进行 top-k 搜索时,查询性能应该会更好,尤其是在以下情况下:
- 有很多子句,
- and/or 某些子句出现频率很高,
- 和/或某些条款产生次优分数上限。
感谢您阅读此博客 - 我们希望您能享受查询加速带来的乐趣! 如果你想了解有关 top-k 查询处理优化的更多信息,请查看另一篇博客,我们在其中描述了如何在 Elasticsearch 7.0/Lucene 8.0 中引入这些优化。
原文:Bringing speedups to top-k queries with many and/or high-frequency terms | Elastic Blog