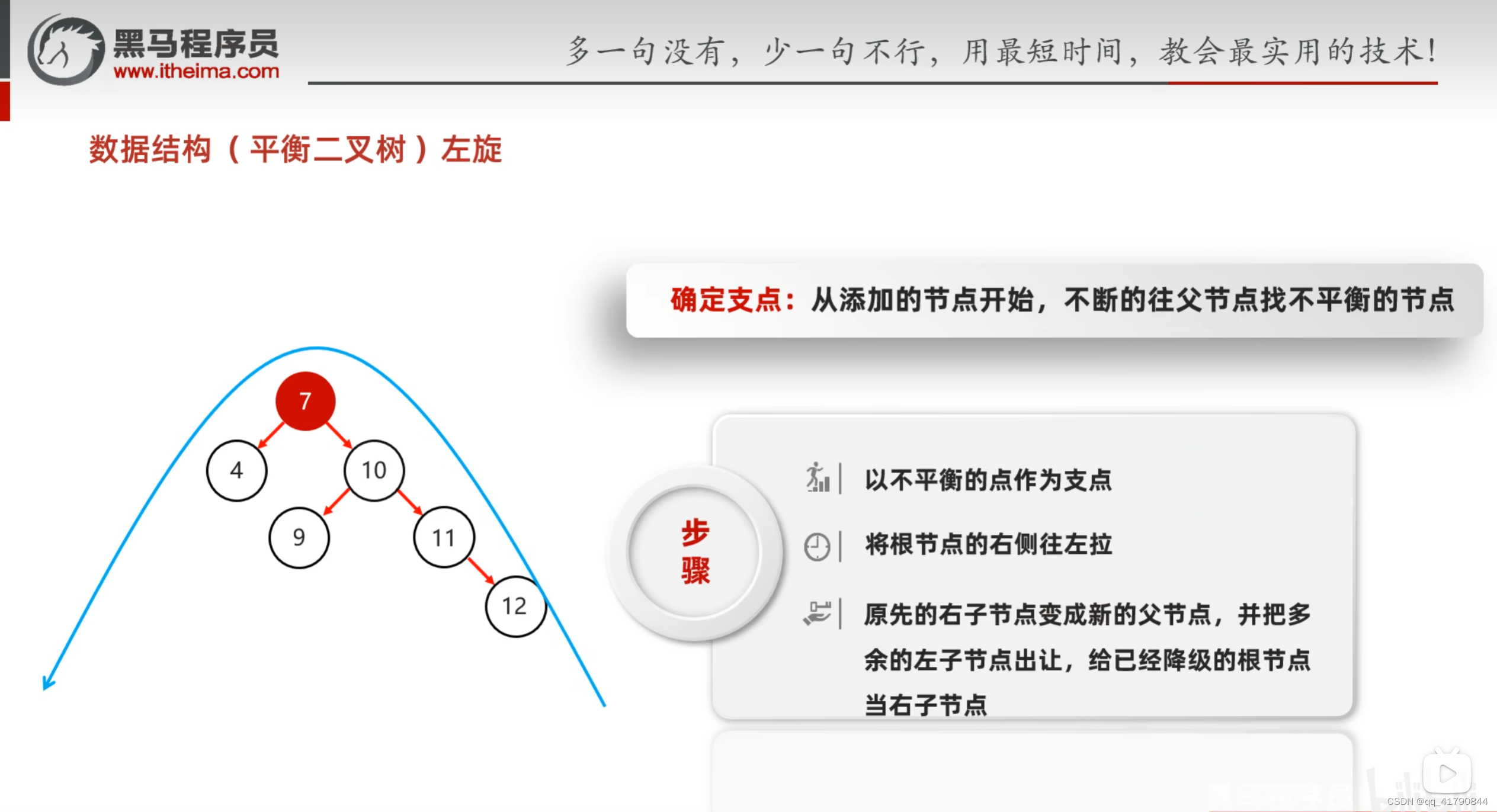
平衡二叉树的纠正
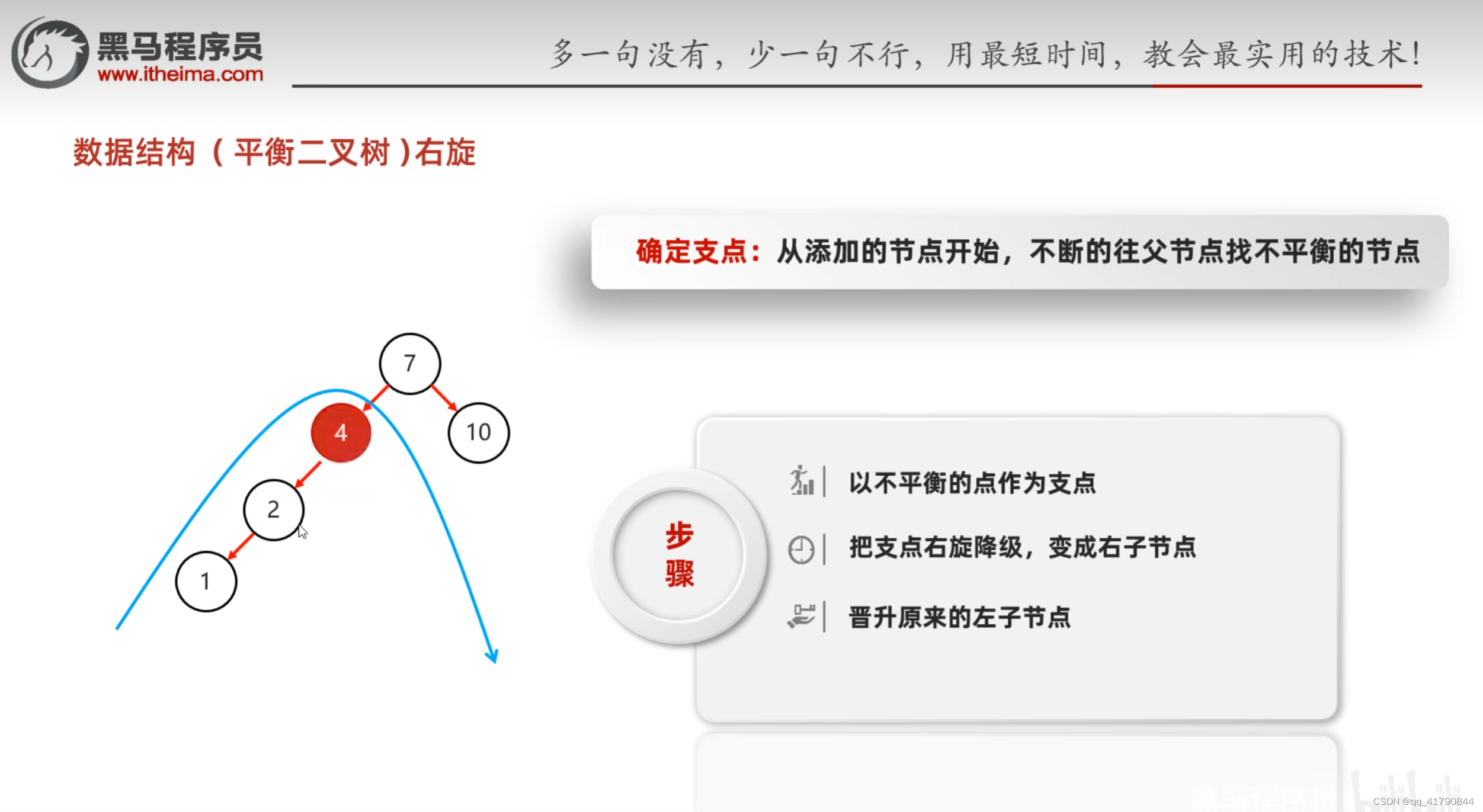
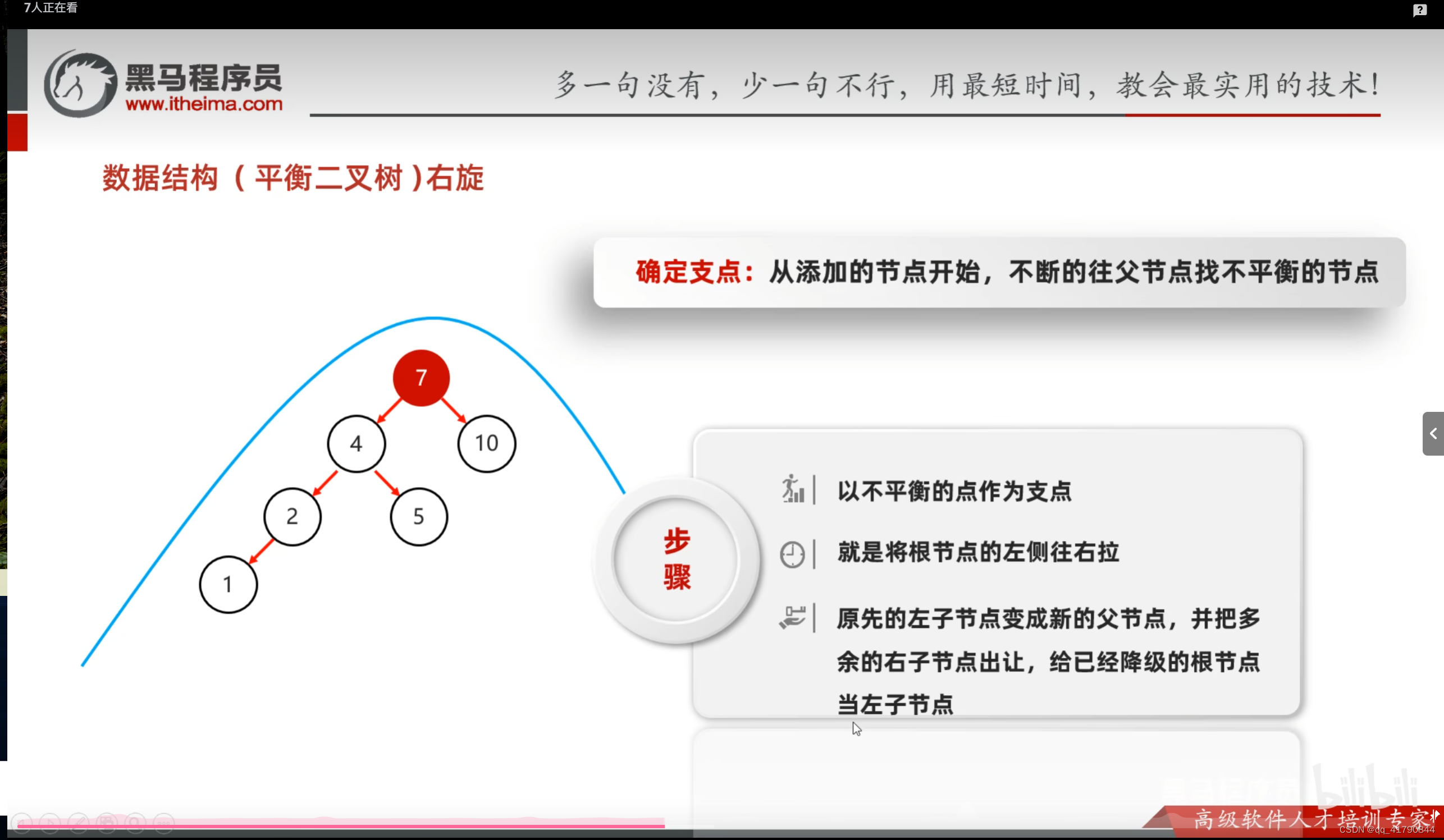

左左,右右可以解决,左右,右左需要先转换成左左,右右。即递归的解决左左,右右。
红黑树是一种二叉查找树,但不是高度平衡的,平衡二叉树的查找效率很高,但维护平衡二叉树的时间较多。红黑树的维护成本低。
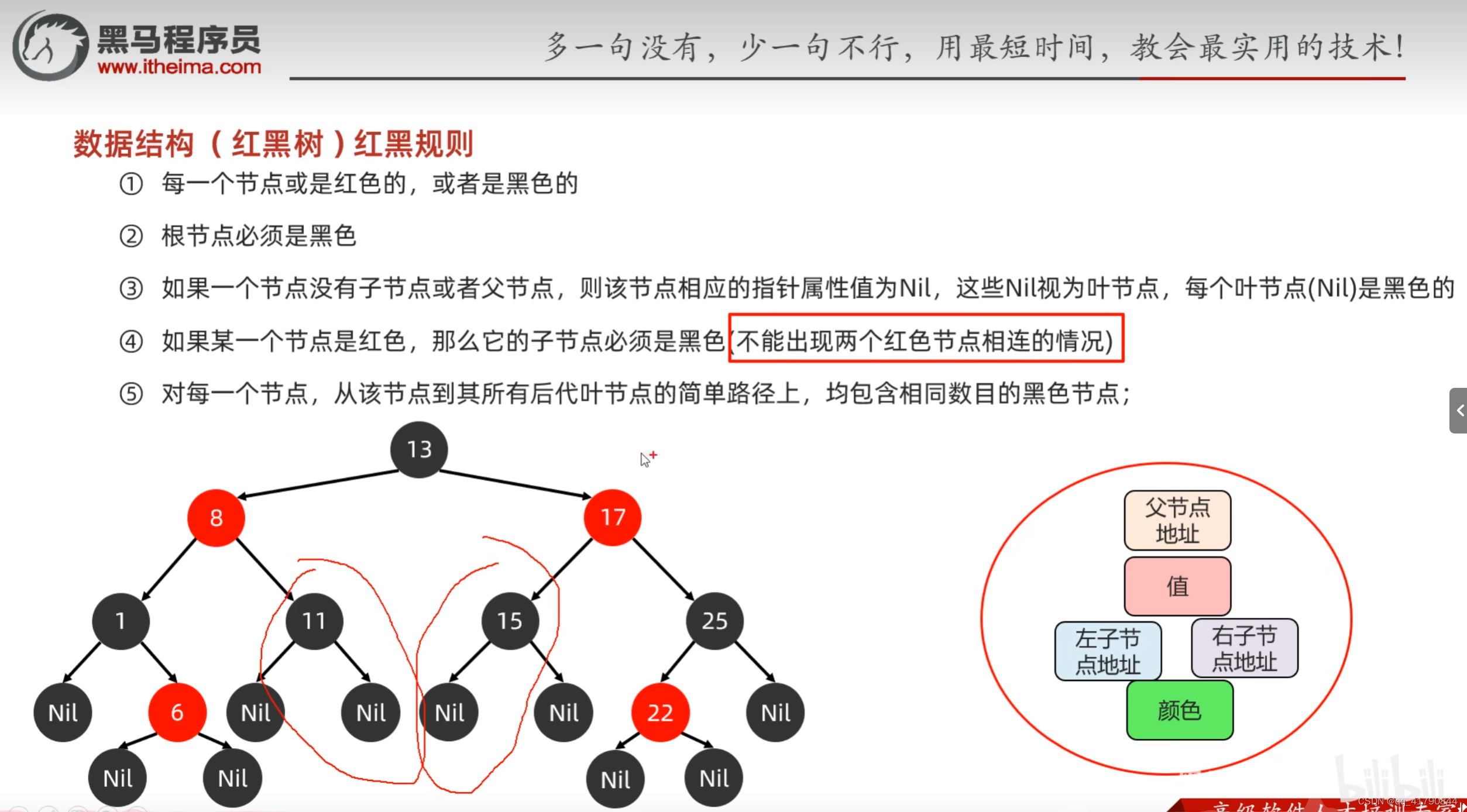
红黑树:1.二叉查找树,满足大小关系,但不是高度平衡的,需要满足特定的红黑规则。
红黑规则:
1.每一个节点要么是红色,要么是黑色的;
2.根节点必须黑色。
3.某一结点是红色,那么子节点应该是黑色(不能出现两个红色节点相连的情况)
4.如果一个节点没有子节点或父节点,则该节点相应的指针属性值为NULL,这些NULL视为叶子节点,每个叶子节点都是黑色的。
5.对每一个节点,从该节点到所有后代叶子节点的简单路径上,均包含相同数目的黑色节点。
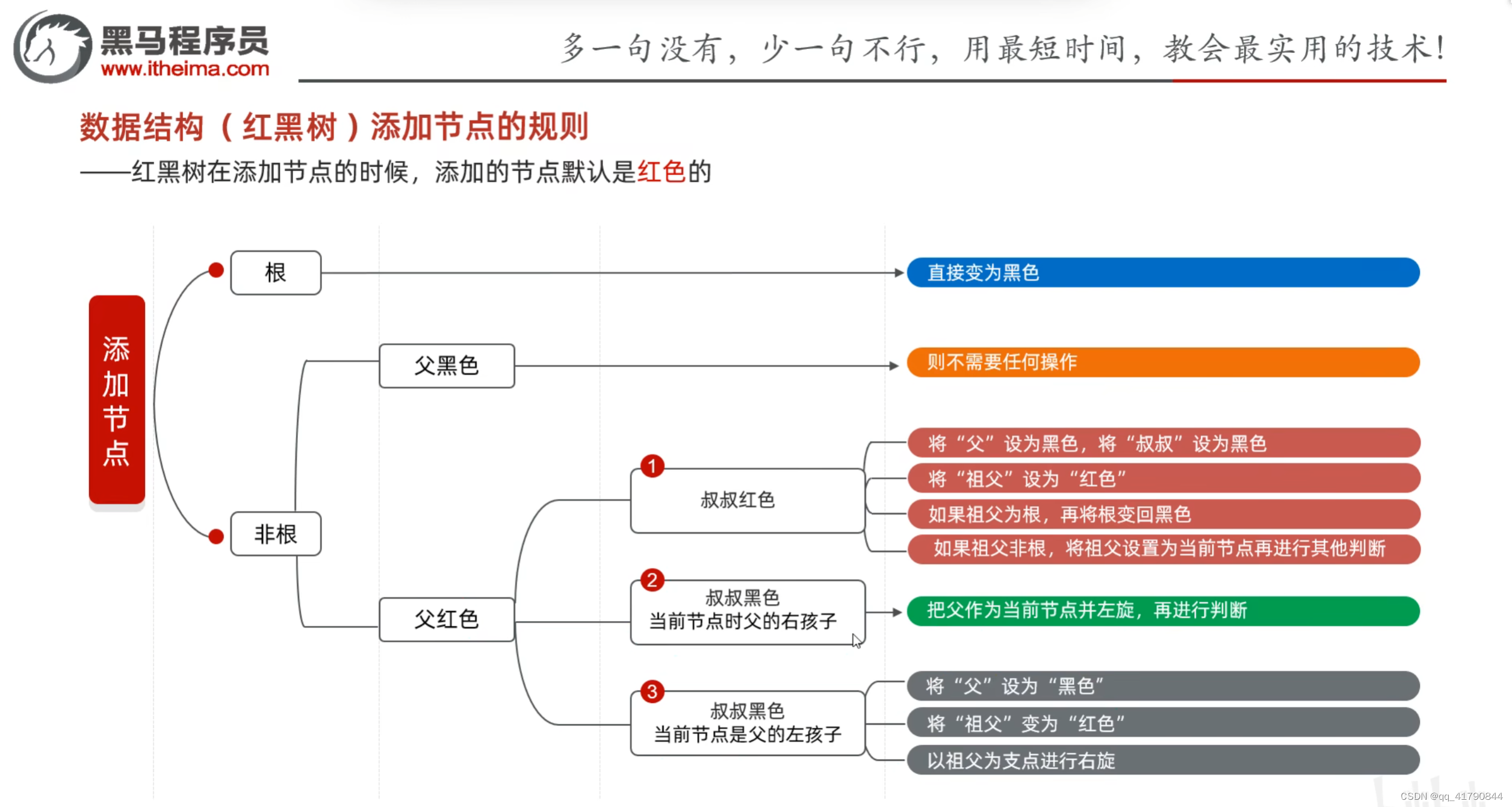
红黑树添加规则:
1.新添加节点默认红色(维护成本低,添加红节点不会违反规则5,顶多违反规则4)
2.
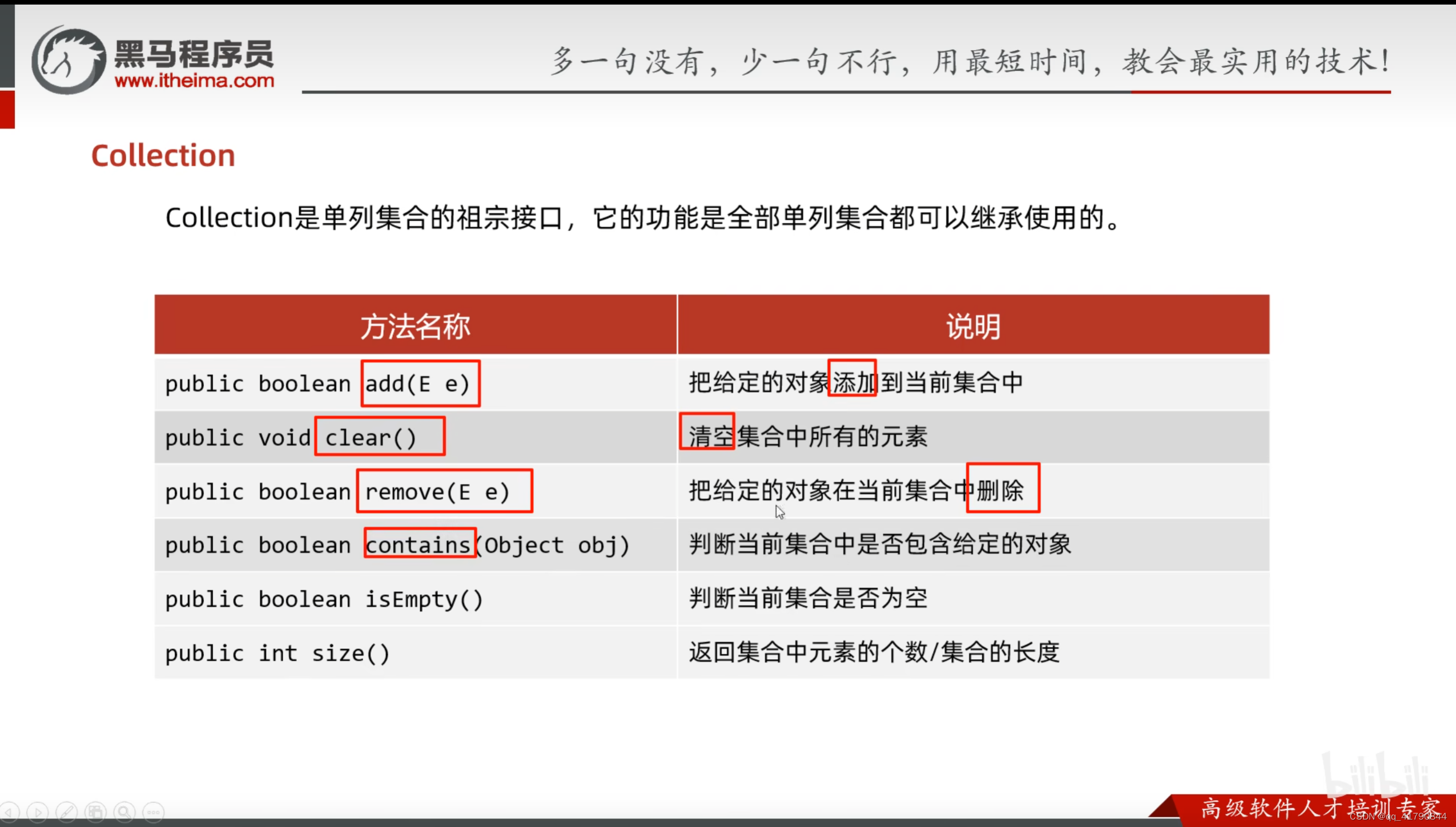 set的方法继承于collection,没有增加的方法
set的方法继承于collection,没有增加的方法
set根据对象来添加,set集合是无序的,存取的顺序是不同的,即他不是链表存储的,可能是桶排序。遍历的方式就是迭代器,与增强for,以及Lambda表达式
各个Set集合:


import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import java.util.function.Consumer;public class Main {public static void main(String[] args) {//从添加的结点开始,不断往父节点中不平衡的节点。//平衡二叉树的旋转。//以不平衡点为支点//把左支点左旋降级,变成左子节点//晋升原来的右子节点。//利用Set集合,添加字符串,使用多种方式遍历;//迭代器,增强for,Lambda表达式Set<String>s=new HashSet<>();s.add("mike");s.add("michael");System.out.println(s);Iterator<String>it=s.iterator();while(it.hasNext()){it.next();//获取元素,移动指针.}for(String a:s){System.out.println(a);};s.forEach(new Consumer<String>() {@Overridepublic void accept(String stl) {System.out.println(stl);}});s.forEach( stl-> System.out.println(stl));Set<String>hashs=new HashSet<>();hashs.add("a"); hashs.add("b"); hashs.add("c"); hashs.add("d");for(String sa:hashs){System.out.println(sa);}hashs.forEach(new Consumer<String>() {@Overridepublic void accept(String sa) {System.out.println(sa);}});Iterator<String>all=hashs.iterator();while(all.hasNext()){all.next();}
}
}不同的类都需要重写hashCode方法;重写方法:alt+insert,电脑帮助重写;
 哈希表的底层存储:
哈希表的底层存储:
HashSet采用哈希表存储,而哈希表采取数组+链表+红黑树来存储;此前采用的是可变数组+链表,可以看到增加的红黑树可以改进搜索效率。之所以采用链表也是类似于十字链表,在元素稀疏的情况下增加遍历效率。加载因子就是可变数组每次扩容多少的意思。
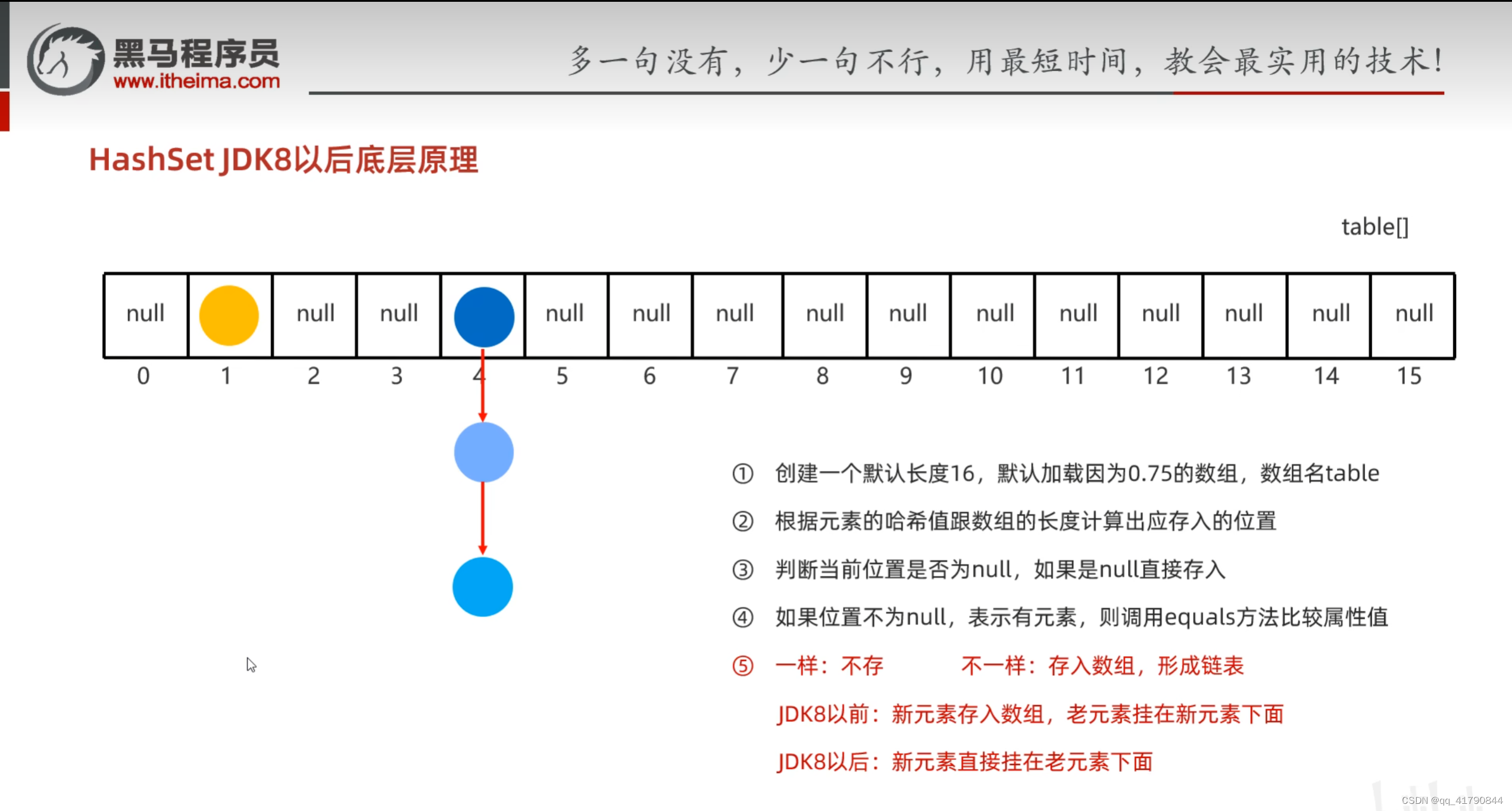 当链表过长时,链表将自动转换为红黑树。哈希表总体采用可变数组,链表,红黑树来组成。,如下表:
当链表过长时,链表将自动转换为红黑树。哈希表总体采用可变数组,链表,红黑树来组成。,如下表:
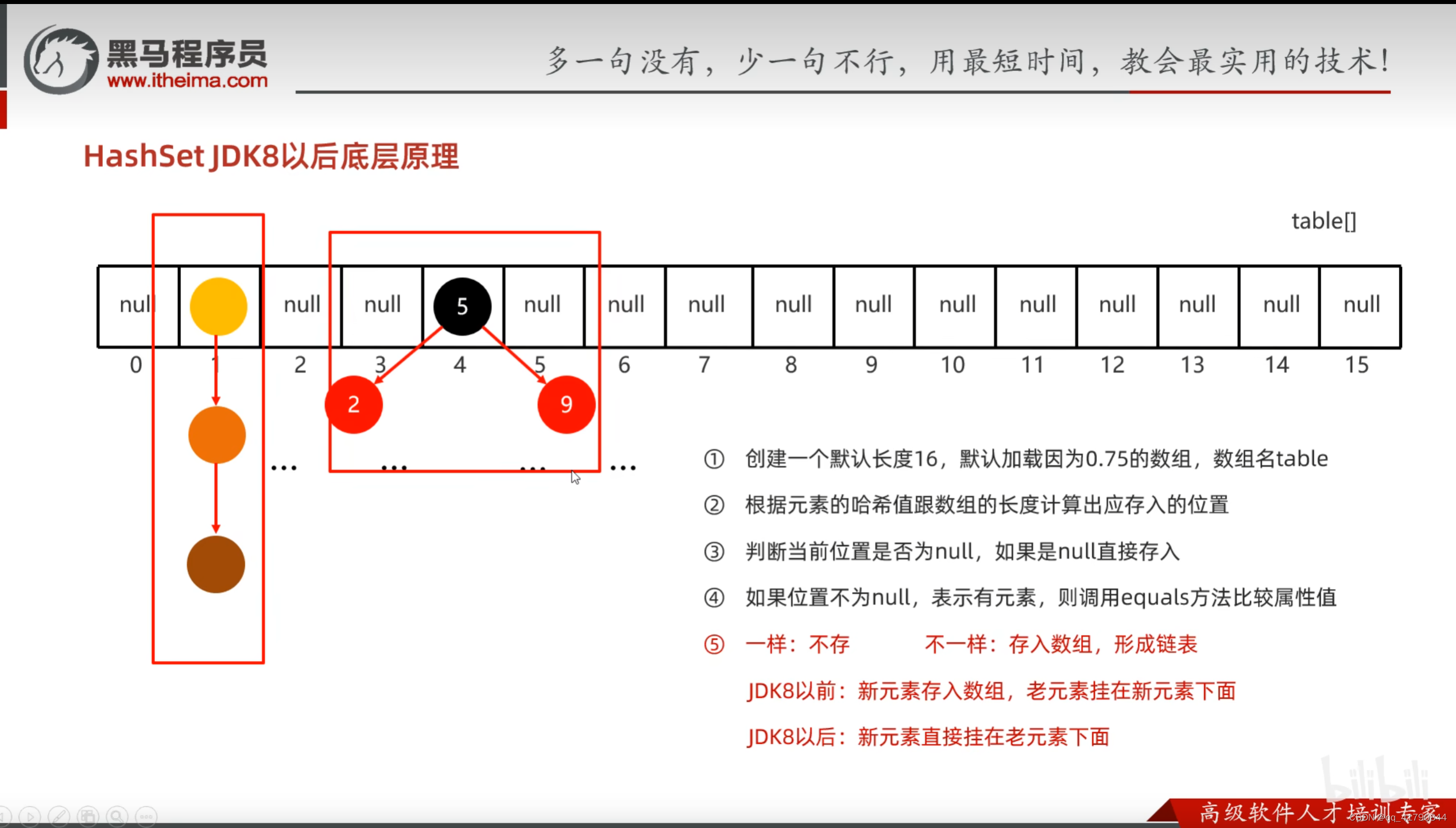
 HashSet底层原理如上。JDK8采用尾插法形成链表,之前采用头插法。
HashSet底层原理如上。JDK8采用尾插法形成链表,之前采用头插法。
红黑树转换条件:
 存储自定义对象时,需要重写hashCode,equals方法,
存储自定义对象时,需要重写hashCode,equals方法,

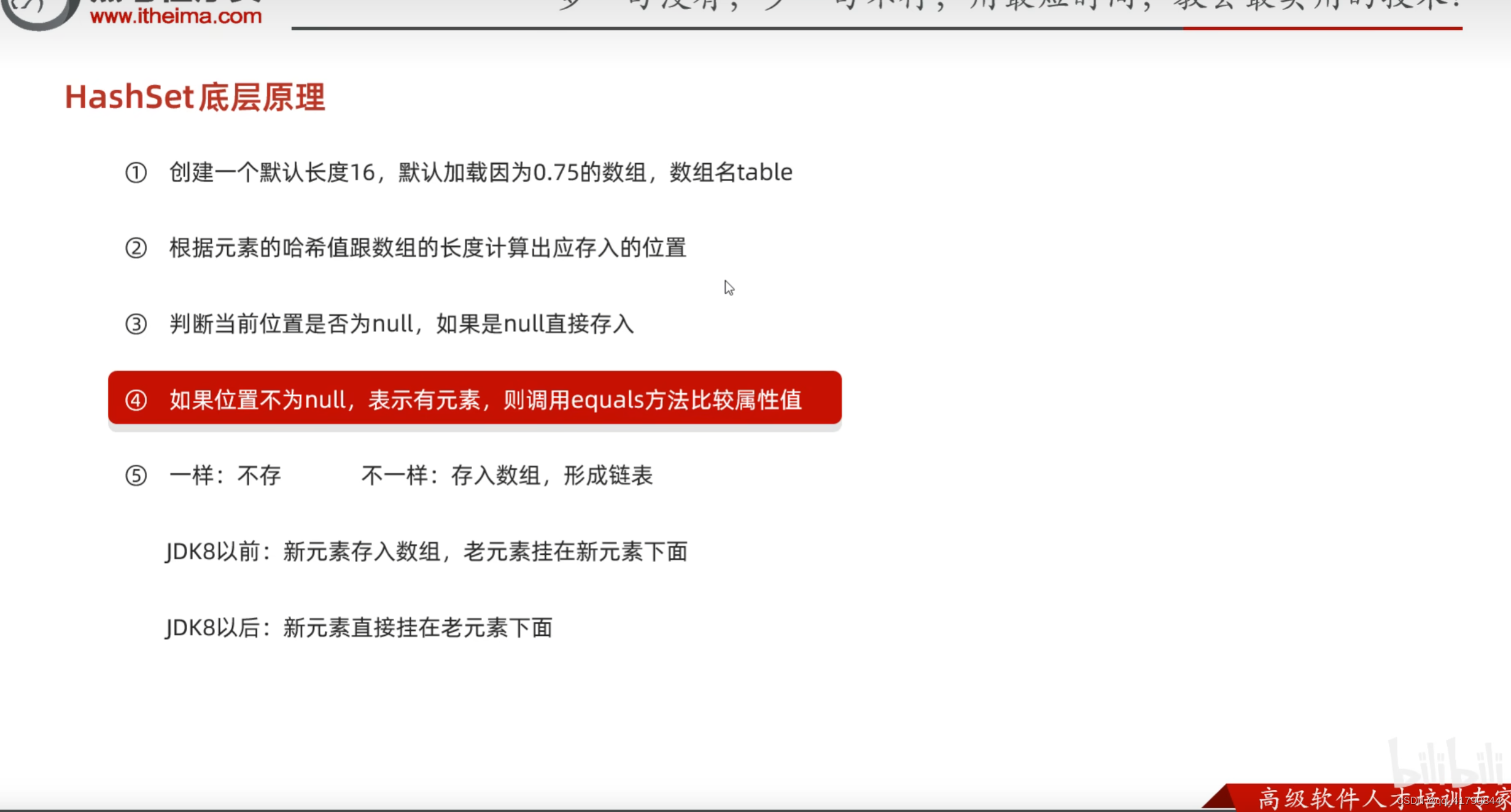
HashSet的三个问题:
HashSet使用hashCode与equals方法保证数据去重的,
 底层数据结构时变长数组,红黑树与链表的形式。
底层数据结构时变长数组,红黑树与链表的形式。
HashSet根据哈希值计算出索引,在使用链表插入该值;
存取是无序的;
练习
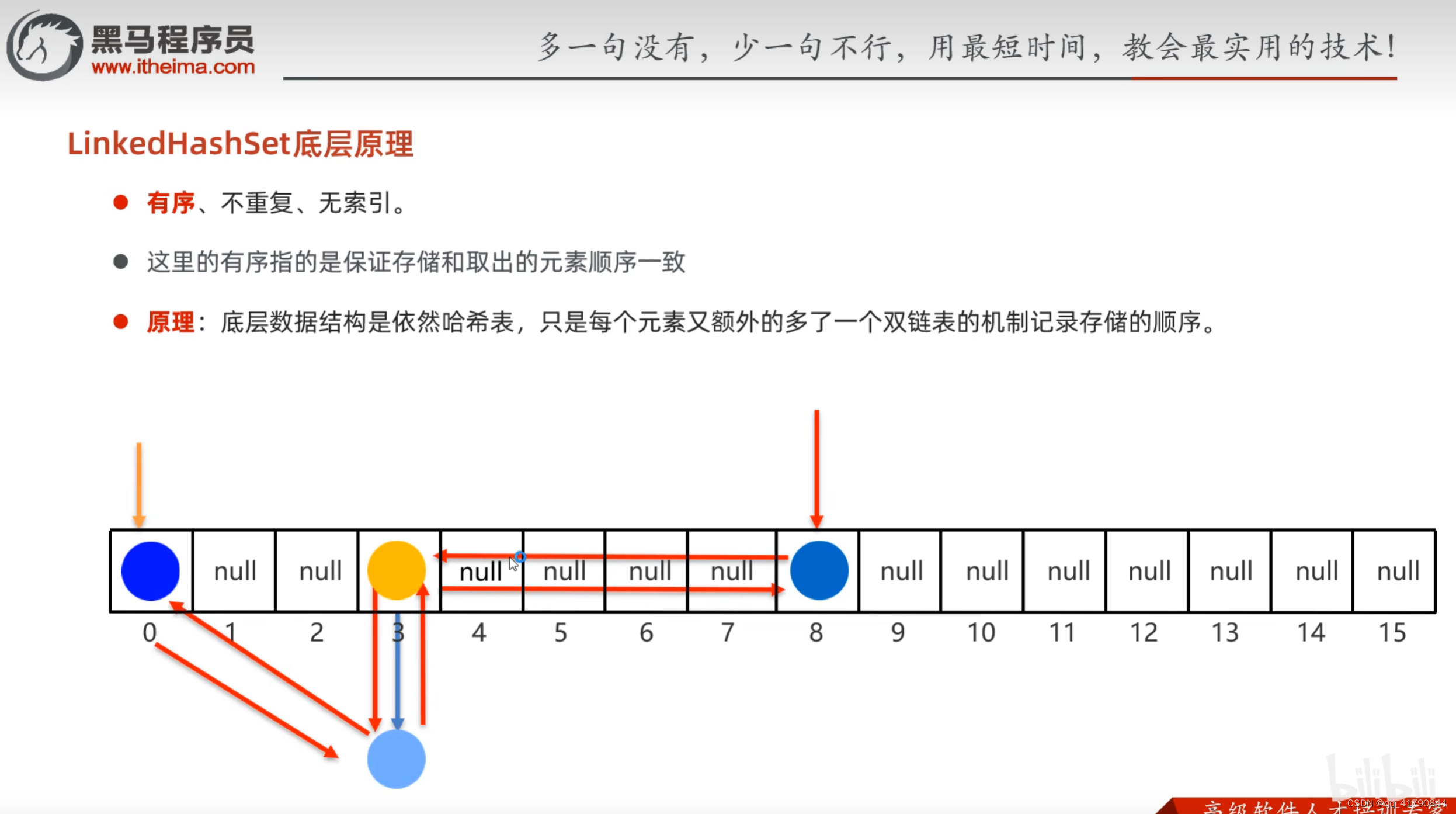
//1.创建三个学生对象//自定义对象需要重写hashCode,equals方法;String,Integer等系统定义类不需要重写。Student s1=new Student("zhangsan",23); Student s2=new Student("lisi",24);Student s3=new Student("wangwu",25); Student s4=new Student("zhangsan",23);//创建集合;//2.创建集合HashSet<Student>hs=new HashSet<>();System.out.println(hs.add(s1)); System.out.println(hs.add(s2));System.out.println(hs.add(s3)); System.out.println(hs.add(s4));//打印集合;System.out.println(hs);LinkedHashSetkeyi可以保证元素的存储与取出是有序的。这是通过增加一个双向链表来实现的。理解为有一个元素记录最后一个添加的元素的地址,然后相互指向。LinkedHashSet在遍历时使用双向链表作为基础数据结构遍历,而不是使用可变数组作为基础数据结构。
TreeSet
TreeSet里的元素需要制定比较方式;通过继承Comparable接口并重写compareTo方法来实现。TreeSet集合底层不是哈希表,他也不是哈希表,不需要重写hashcode,equals方法;

第二种排序方式:重写compare方法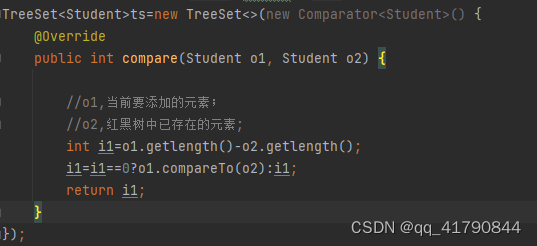
选用TreeSet第三种构造方法,重写Comparator的compare方法;