摘要-这项工作提供了一个架构,使机器人能够通过形状完成抓取规划。形状完成是通过使用3D卷积神经网络(CNN)来完成的。该网络是在我们自己的新的开源数据集上训练的,该数据集包含了从不同视角捕获的超过44万个3D样本。运行时,从单个视角捕获的2.5D点云被送入CNN, CNN填充场景的遮挡区域,允许对已完成的对象进行计划和执行抓取。运行时形状完成非常快,因为形状完成的大部分计算成本是在离线训练中承担的。我们探讨了不同因素对完井质量的影响。这些包括在训练数据中是否存在被完成的对象,以及有多少对象模型被用来训练网络。我们还将研究网络泛化到新对象的能力,从而允许系统在运行时完成以前不可见的对象。最后,在仿真和实际机器人硬件上进行了实验,以探索完成质量与完成的抓取网格模型的实用性之间的关系。
由于场景几何信息不完整,基于原始感知数据的抓取规划比较困难。在这项工作中,3D cnn可以通过形状完成实现稳定的机器人抓取规划。3D CNN被训练从目标对象的单个点云完成形状,本质上是填充对象的遮挡部分。这种推断封闭几何图形的能力可以应用于许多机器人任务。它可以帮助手臂运动和机器人导航的路径规划,准确地理解遮挡场景区域是否被占用,从而获得更好的轨迹。它还允许传统的抓握规划生成稳定的抓握通过完成的形状。在训练过程中,CNN展示了由数千张不同网格模型的综合渲染深度图像创建的占用网格。这些占用网格从一个角度捕捉,封闭区域被标记为空。对于每个训练示例,也会为给定的网格生成地面真实占用网格(整个3D体的占用网格)。从这些占用网格对CNN学习快速完成网格模型在运行时仅使用信息从单一的观点。图1中显示了几个例子。这种设置对于机器人应用程序是有益的,因为大部分的计算时间是在离线训练期间,因此在运行时,对象的部分视图点云可以通过CNN运行,平均在十分之一秒内完成,然后快速网格化。在运行时,点云被捕获、分割,并具有与提取的可抓取对象对应的区域。创建这些区域的占用网格,并通过训练的CNN分别传递。来自CNN的输出是占用网格,其中CNN已标记输入的所有遮挡区域为每个对象被占用或为空。这些新的占用网格要么通过一个快速移动立方体算法运行,要么进一步后处理,如果他们要被抓住。无论目标是完成的还是完成的,后期处理的结果是1)适合路径规划和场景理解的快速完成,或2)适合抓取规划的详细网格,其中高分辨率的可见区域被纳入到重建中。该框架可扩展到具有多个对象的拥挤场景,因为每个对象都是单独完成的。它也适用于不同的领域,因为它可以从任意的训练数据中学习,并进一步展示了泛化到对象的未见视图甚至是全新对象的能力。这项工作的贡献包括:1)一个新颖的CNN建筑形状完成;2)快速网格补全方法,使网格能够快速填充规划场景;3)第二种CUDA补全方法,通过整合观测点云的细节,创建适合抓取规划的详细网格;4)超过44万403体素网格对的开源数据集,用于训练。该数据集和相关代码可在http://shapecompletiongrasping.cs.columbia.edu免费获得。该网站使它很容易浏览和探索成千上万的完成和掌握相关的工作;5)仿真和现场实验结果对比了我们的方法和其他方法,证明了它在抓取任务方面的改进性能。
ii。使机器人能够抓取的一般形状补全的典型方法使用对称和挤压启发式,并且对于由几何基元表示的对象是合理的。我们的方法的不同之处在于,它根据训练范例学习完成任意对象,而不是要求对象遵循启发式。在机器人领域,一般形状补全的替代方法是物体识别和3D姿态检测。在这些方法中,对象识别对象数据库和姿态估计。这些技术填补了一个不同的用例:遇到的对象的数量很少,并且提前知道。我们的方法的不同之处在于它扩展到新的对象。计算机视觉社区也对形状完成感兴趣。[7][8],使用深度信念网络和Gibbs抽样,[9],使用随机森林。[10]使用基于范例的方法。其他人已经开发出了直接从二维图像学习三维占用网格的算法。[13]使用模型数据库完成。由于到目前为止机器人操作任务所需的手持对象的大型渲染数据集还不存在,因此很难将这些工作直接应用到机器人操作中。此外,[11][12]使用的是纯RGB图像,而不是机器人中常见的RGBD图像,这使得问题更加困难,因为完成的形状必须以某种方式放置在场景中,而且该过程没有利用可用的深度信息。大多数创建的结果分辨率太低,无法与当前需要网格的抓取计划器使用。我们的工作创建了一个新的数据集,专门用于使用2.5 d距离传感器完成对操作任务有用的对象,并提供了一种技术,将对象的高分辨率观察视图与我们相对高分辨率的CNN输出集成在一起,创建适合于抓取规划的完成。
我们的工作与[14][15]不同,两者都需要一个完整的网格来查询模型数据库和检索抓取用于类似的物体。这些方法可以与我们的框架一起使用,其中已完成的模型将充当查询网格。虽然可以在对象未完成的地方使用部分网格计划抓取(参见[16]),但它们仍然有其局限性和问题。形状完成可以用来缓解这个问题。本框架使用YCB[17]和Grasp Database[18]网格模型数据集。我们选择这些是因为世界各地的许多机器人实验室都有YCB对象的物理副本,而Grasp Database包含了特定于机器人操作的对象。我们用590个Grasp Database网格增强了18个更高质量的YCB网格。iii。为了训练一个网络来重建不同范围的对象,我们从YCB和Grasp Database中收集网格。模型通过binvox[19]运行,生成2563个占用网格。然后在Gazebo[20] 726中,对每个对象进行不同的均匀采样旋转,生成深度图像。深度图像用于为模拟相机可见的网格部分创建占用网格,然后将binvox生成的所有占用网格转换为正确地覆盖深度图像占用网格。然后将两组占用网格下采样至403,以创建大量的训练示例。输入集(X)包含占用网格,这些网格只被摄像机可见的对象区域所填满,而输出集(Y)包含整个模型所占用空间的地面真实占用网格。
表一中的CNN架构是使用交叉熵误差代价函数和优化器Adam[21]进行训练的。Jaccared Similarity Jaccared Similarity根据[22][23]初始化权值,并在NVIDIA Titan X GPU上以32批处理大小进行训练。我们使用Jaccard相似性(相交于联合)来比较生成的体素占用网格和地面真相。在训练期间,这个度量是为训练数据中的输入网格(训练视图)、训练数据中的网格的新视图(钉式视图)和训练数据中没有的对象的网格(钉式模型)计算的。
为了探究重构的质量如何随着训练集中模型数量的调整而变化,我们使用不同数量的mesh模型训练三个具有相同架构的网络。一组用14个YCB模型的部分视图进行训练,另一组用94个模型(14个YCB模型+ 80个抓取数据库)进行训练,第三组用486个模型(14个YCB模型+ 472个抓取数据库)进行训练。每个网络都被允许进行训练,直到学习达到稳定状态。其余4个YCB和118个抓取数据集模型作为保留集。图2显示了Jaccard相似性度量如何随着网络的列车而变化。我们注意到,使用较少模型进行训练的网络,当它们在训练期间看到的物体视图上进行测试时,其形状完成效果比使用大量模型进行训练的网络更好。这表明,对于数量较少的模型,该网络能够完全学习训练数据,但对于数量较多的模型,则很难做到这一点。相反,训练的模型当被要求完成新物体时,数量多的物体比数量少的物体表现得更好。因为,正如我们所看到的,在大量物体上训练的网络无法学习在训练中看到的所有模型,他们可能被迫学习一种更普遍的完成策略,这将适用于更广泛的物体,使他们能够更好地概括在训练中没有看到的物体。图2(a)显示了三个cnn在训练视图上的表现。在这种情况下,训练时使用的网格模型越少,完井效果越好。图2(b)显示了cnn如何在训练期间使用的网格对象的新视图上执行。在这里,cnn的做法大致相同。图2(c)显示了cnn对未见过物体的补全质量。在这种情况下,随着训练中使用的网格模型数量的增加,性能会随着系统学会了对更广泛的输入进行泛化而提高。
在运行时,从3D传感器获取目标对象的点云,进行缩放、体素化并通过CNN。CNN的输出(对象的完整体素网格)经过一个后处理算法返回一个完整的网格。最后,根据已完成的网格模型对抓取进行规划和执行。图3展示了一个新对象的运行时管道。
1)获取目标点云:使用Microsoft Kinect捕捉一个点云,然后使用PCL的[24]实现欧氏聚类提取进行分割。选择与待补全对象相对应的段。2)通过CNN完成:选择的点云被用来创建分辨率为403的占用网格。这个占用网格被输入到CNN, CNN的输出是一个等效大小的已完成形状的占用网格。为了使点云适合于403网格,它被按比例缩小,以便点云的包围盒适合于一个323体素立方体,然后位于403网格的中心,这样包围盒的中心就位于(20,20,18)。最后,从这个缩放和转换的点云中所占据的所有体素都被这样标记。将点云稍微偏离z维度的中心位置,会在网格的后半部分留下更多的空间供网络填充。3a)创建快速网格:如果被完成的物体没有被抓取,那么CNN输出的体素网格通过移动的立方体运行,并将生成的网格添加到规划场景中,填充闭塞。3b)创建详细网格:或者,如果这个对象将被抓取,那么就会发生后处理。这种后处理的目的是将来自物体可见部分的点与CNN的输出结合起来。这张局部视图的密度比403网格高得多,并且捕捉到了可见表面的更细微的细节。这种合并是困难的,因为捕获的云和403 CNN输出之间的点密度差异很大,如果天真地合并这些点,可能会导致空洞和不连续性。
Alg. 1展示了我们如何通过以下步骤将密集的局部视图与403体素网格集成在一起。(alg1:L5)为了与局部视图合并,将CNN的输出转换为点云,将其密度与局部视图点云密度进行比较。密度的计算方法是随机抽样10个点,并取它们到最近邻居的距离的平均值。(alg1:L6) CNN输出通过d_ratio上采样,以匹配局部视图的密度。对于每个新的体素,计算到8个最接近的原始体素的L1距离,并将这8个距离相加,如果原始体素被占用,则加权为1,否则加权为1。如果加权和为,则新体素被占用非负的。这具有创建分段线性分离表面的效果,类似的移动立方体和减轻上采样伪影。(alg1:L7)然后将CNN上采样输出与局部视图的点云合并,合并后的云以新的更高分辨率(40∗d_ratio)3进行体素化。对于大多数对象来说,d_ratio是2或3,这取决于对象的物理大小,从而产生803或1203的体素网格。(alg1:L8)填充上采样CNN输出与部分视图云之间的体素网格中的任何空隙。这是通过在每个z堆栈中找到第一个被占用的体素来完成的。如果到下一个被占用体素的距离小于d_ratio+1,则中间体素被填充。(alg1:L9)使用我们的CUDA实现从[25]的凸二次优化来平滑体素网格。(alg1:L10)加权体素网格通过移动的立方体运行。4)抓取完成的网格:抓取中,在重构网格上计划抓取![26],计划抓取的可达性在MoveIt![27],执行最高质量的可达抓取。
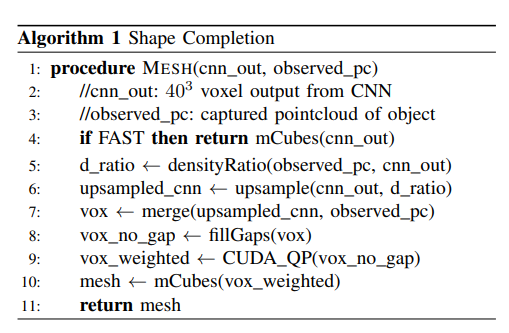
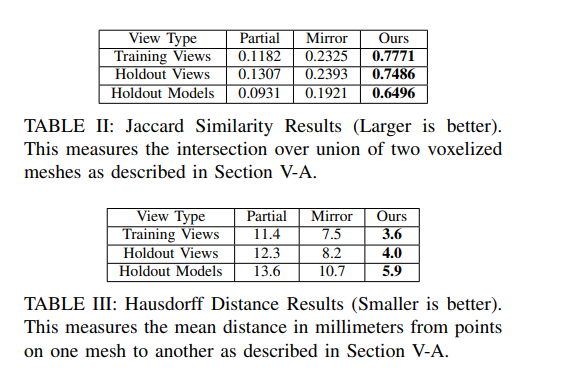
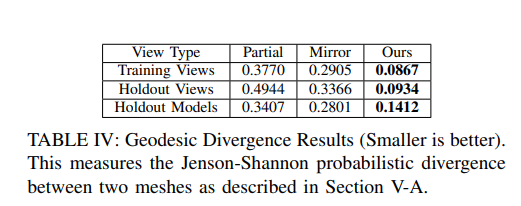
我们随机抽取50个训练视图(training views)、50个抵抗者视图(holdout views)和50个抵抗者模型视图(holdout models)建立测试数据集。从14个YCB训练对象中采样训练视图和拒绝视图。钉子锁模型从钉子锁YCB和抓取数据集对象中采样。我们使用Jaccard相似度、Hausdorff距离和测地线散度来比较完成方法的准确性。我们首先比较了几种常见的补全方法:通过移动立方体和Meshlab的拉普拉斯平滑(partial),镜像补全[1](Mirror),我们的方法(our)。我们的CNN是在YCB + Grasp Dataset中的484个对象上训练的,权值来自holdout模型的性能峰值点(图2(c)中的红线)。Jaccard相似度用于比较几种补全策略的最终结果网格(表II)。
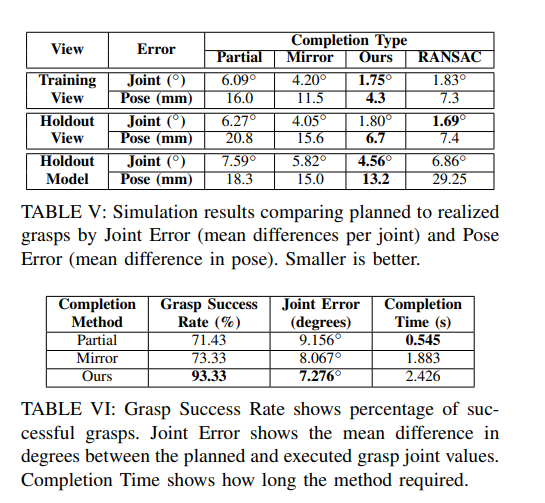
完成的网格在803点进行体素化,并与地面真相进行比较。在所有测试视图中,我们提出的方法比部分和镜像方法与地面真网格的相似度更高。利用Meshlab的[28]实现在两个方向上计算Hausdorff距离。表三给出了每种完井方法的对称Hausdorff距离的平均值。CNN完成率明显比部分和镜像完成率更接近地面真相。用测地线散度[29]来比较完形。每个网格计算一个概率密度函数。每个完成的概率密度函数与地面真实网格使用简森-香农散度进行比较。表四显示了每种完井方法的散度均值。在这里,我们的方法优于所有其他完成方法。在所有指标中,我们的方法比其他常规完井方法获得更精确的完井结果。B.与数据库驱动方法的比较我们在YCB数据集的Training Views上使用相同的度量评估了基于ransac的方法[5]。这对应于一个高度约束的环境,它只包含非常少的提前已知的对象。将484个对象加载到RANSAC框架中是不可能的,因此直接比较我们的方法涉及到我们训练的大量对象是不可能的。事实上,基于ransac的方法无法扩展到大型对象数据库,这是我们工作的动机之一。然而,我们将我们的方法与一个仅使用14个对象的非常小的RANSAC进行了比较,我们的方法甚至在其数据库中的对象上的表现与RANSAC方法相当,同时具有训练更多对象和泛化到新对象的额外能力:Jaccard (our: 0.771, RANSAC: 0.8566), Hausdorff (our: 3.6, RANSAC:3.1),测地线(我们的:0.0867,RANSAC: 0.1245)。当我们的方法遇到一个以前没有见过的对象(Holdout Models)时,我们的方法显著优于RANSAC方法:Jaccard(我们的:0.6496,RANSAC: 0.4063), Hausdorff(我们的:5.9,RANSAC: 20.4),测地线(我们的:0.1412,RANSAC: 0.4305)。基于RANSAC的方法在Holdout模型上的性能也比在测地线和Hausdorff度量上的镜像或部分完井方法差。C.基于仿真的抓取比较为了评估我们的框架实现抓取规划的能力,系统在仿真中使用相同的方法进行了测试
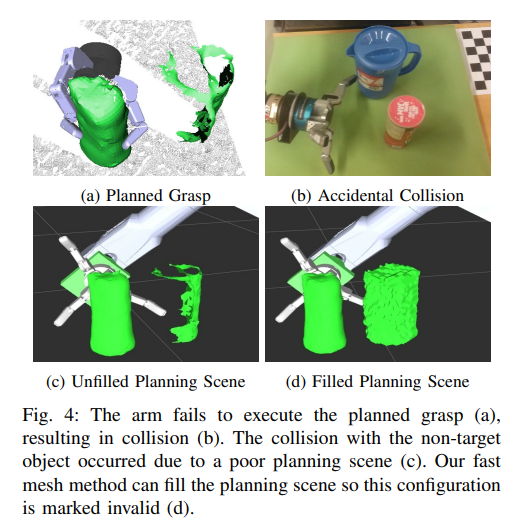
从Sec V-A完成。抓住!被用来计划超过24000个抓取对象的所有完成。为了模拟真实世界的抓握执行,完成从抓取!ground真值对象被插入到它的位置。然后将手沿抓取的接近方向向后放置于离地面真实对象20cm的位置。设定手指的展开角度,沿计划抓取的接近方向移动手掌,直至达到接触或达到抓取姿态。在这一点上,手指闭合到计划的关节值,并继续,直到接触发生或关节极限达到。整个YCB和抓取数据集的仿真结果可视化可在http://shapecompletiongrasping.cs.columbia.edu获得。表V显示了计划和实现的关节状态之间的差异,以及计划和实现的抓取之间末端执行器基部的姿态差异。使用我们的方法使末端执行器在关节空间和手掌的笛卡尔坐标位置上都更接近它的预定位置。该系统以端到端方式使用Barrett Hand和StaubliTX60 Arm,通过上述完成方法对15个YCB对象执行计划抓取。对于每个对象,我们在每个完成方法中运行一次arm。表VI的结果显示,我们的方法在抓取成功率方面比一般形状补全方法提高了20%,并且执行抓取的关节误差更低,更接近计划抓取。场景中通常包含一些不需要操作的对象,为了避免出现这种情况,需要完成这些对象。在本例中,我们的CNN输出可以直接运行不经过后处理的移动立方体快速创建网格。图4强调了对非目标物体进行推理的好处。我们的系统能够快速填充场景的被遮挡区域,并有选择地花费更多的时间在特定对象上生成详细的补全。15次拥挤场景的平均场景完成时间分别为场景分割(0.119s)、目标对象完成(2.136s)和非目标对象完成(0.142s)。本工作利用CNN对单视角观察到的物体进行完成和网格化,然后对完成的物体进行规划抓取。补全系统非常快,补全可以在几毫秒内完成,而适用于抓取计划的后处理补全则在几秒钟内完成。该数据集和代码是开源的,可供其他研究人员使用。它还证明,就各种度量(包括那些特定于掌握计划的度量)而言,我们的完成比更天真的方法更好。此外,与其他方法相比,使用我们的方法完成完井作业时计划的抓手更接近预期的手部结构。