文章目录
- 一、什么是左值、右值
- 二、什么是左值引用、右值引用
- 2.1 左值引用
- 2.2 右值引用
- 2.3 对左右值引用本质的讨论
- 三、右值引用和std::move使用场景
- 3.1 右值引用优化性能,避免深拷贝
- 浅拷贝重复释放
- 深拷贝构造函数
- 移动构造函数
- 3.2 移动语义(move)
- 3.3 完美转发 forward
- 3.4 emplace_back 减少内存拷贝和移动
- 四、小结
一、什么是左值、右值
1)左值可以取地址、位于等号左边;
2)而右值没法取地址,位于等号右边。
例如
int a = 6;
1)a可以通过 & 取地址,位于等号左边,所以a是左值。
2)6位于等号右边,6没法通过 & 取地址,所以6是个右值。
又例如
struct A {A(int a = 0) {a_ = a;}int a_;
};
A a = A();
1)同样的,a可以通过 & 取地址,位于等号左边,所以a是左值。
2)A()是个临时值,没法通过 & 取地址,位于等号右边,所以A()是个右值。
可见左右值的概念很清晰,有地址的变量就是左值,没有地址的字面值、临时值就是右值。
二、什么是左值引用、右值引用
引用本质是别名,可以通过引用修改变量的值,传参时传引用可以避免拷贝。
2.1 左值引用
左值引用:能指向左值,不能指向右值的就是左值引用:
int a = 5;
int &ref_a = a; // 左值引用指向左值,编译通过
int &ref_a = 5; // 左值引用指向了右值,会编译失败
引用是变量的别名,实际指向同一块内存地址。由于右值没有地址,没法被修改,所以左值引用无法指向右值。
但是,const左值引用是可以指向右值的:
const int &ref_a = 5; // 编译通过
const左值引用不会修改指向值,因此可以指向右值,这也是为什么要使用 const & 作为函数参数的原因之一,如 · std::vector 的 push_back :·
void push_back (const value_type& val);
如果没有 const , vec.push_back(5) 这样的代码就无法编译通过。
2.2 右值引用
再看下右值引用,右值引用的标志是 && ,顾名思义,右值引用专门为右值而生,可以指向右值,不能指向左值:
int &&ref_a_right = 5; // ok
int a = 5;
int &&ref_a_left = a; // 编译不过,右值引用不可以指向左值
ref_a_right = 6; // 右值引用的用途:可以修改右值
2.3 对左右值引用本质的讨论
1、右值引用有办法指向左值吗?
有办法,使用 std::move :
int a = 5; // a是个左值
int &ref_a_left = a; // 左值引用指向左值
int &&ref_a_right = std::move(a); // 通过std::move将左值转化为右值,可以被右值引用指向
cout << a; // 打印结果:5
std::move 是一个非常有迷惑性的函数:
1)不理解左右值概念的人们往往以为它能把一个变量里的内容移动到另一个变量;
2)但事实上std::move移动不了什么,唯一的功能是把左值强制转化为右值,让右值引用可以指向左值。其实现等同于一个类型转换: static_cast<T&&>(lvalue) 。 所以,单纯的std::move(xxx)不会有性能提升。
同样的,右值引用能指向右值,本质上也是把右值提升为一个左值,并定义一个右值引用通过std::move指向该左值:
int &&ref_a = 5;
ref_a = 6;
等同于以下代码:
int temp = 5;
int &&ref_a = std::move(temp);
ref_a = 6;
// 此时temp等于6,ref_a 是temp的引用
2、左值引用、右值引用本身是左值还是右值?
被声明出来的左、右值引用都是左值。 因为被声明出的左右值引用是有地址的,也位于等号左边。仔细看下边代码
// 形参是个右值引用
void change(int&& right_value) {right_value = 8;
}
int main() {int a = 5; // a是个左值int &ref_a_left = a; // ref_a_left是个左值引用int &&ref_a_right = std::move(a); // ref_a_right是个右值引用change(a); // 编译不过,a是左值,change参数要求右值change(ref_a_left); // 编译不过,左值引用ref_a_left本身也是个左值change(ref_a_right); // 编译不过,右值引用ref_a_right本身也是个左值change(std::move(a)); // 编译通过change(std::move(ref_a_right)); // 编译通过change(std::move(ref_a_left)); // 编译通过change(5); // 当然可以直接接右值,编译通过cout << &a << ' ';cout << &ref_a_left << ' ';cout << &ref_a_right;// 打印这三个左值的地址,都是一样的
}
看完后你可能有个问题,std::move会返回一个右值引用 int && ,它是左值还是右值呢? 从表达式 int&&ref = std::move(a) 来看,右值引用 ref 指向的必须是右值,所以move返回的 int && 是个右值。所以右值引用既可能是左值,又可能是右值吗? 确实如此:右值引用既可以是左值也可以是右值,如果有名称则为左值,否则是右值。
或者说:作为函数返回值的 && 是右值,直接声明出来的&&是左值。 这同样也符合前面章节对左值,右值的判定方式:其实引用和普通变量是一样的,int &&ref = std::move(a)和 int a = 5 没有什么区别,等号左边就是左值,右边就是右值。
3、结论
1)从性能上讲,左右值引用没有区别,传参使用左右值引用都可以避免拷贝。
2)右值引用可以直接指向右值,也可以通过std::move指向左值;而左值引用只能指向左值(const左值引用也能指向右值)。
3)作为函数形参时,右值引用更灵活。虽然const左值引用也可以做到左右值都接受,但它无法修改,有一定局限性。
void f(const int& n) {n += 1; // 编译失败,const左值引用不能修改指向变量
}
void f2(int && n) {n += 1; // ok
}
int main() {f(5);f2(5);
}
三、右值引用和std::move使用场景
std::move 只是类型转换工具,不会对性能有好处;
3.1 右值引用优化性能,避免深拷贝
浅拷贝重复释放
#include <iostream>
using namespace std;
class A
{
public:A() :m_ptr(new int(0)) {cout << "constructor A" << endl;}~A(){cout << "destructor A, m_ptr:" << m_ptr << endl;delete m_ptr;m_ptr = nullptr;}
private:int* m_ptr;
};// 为了避免返回值优化,此函数故意这样写
A Get(bool flag)
{A a;A b;cout << "ready return" << endl;if (flag)return a;elsereturn b;
}
int main()
{{A a = Get(false); }cout << "main finish" << endl;return 0;
}
constructor A // Get函数的a 构造
constructor A // Get函数的b 构造
ready return
destructor A, m_ptr:0x25c2880 // main函数的a析构
destructor A, m_ptr:0x25c2830 // Get函数的b析构
destructor A, m_ptr:0x25c2880 // Get函数的a析构,重复释放
main finish
深拷贝构造函数
在上面的代码中,默认构造函数是浅拷贝,main函数的 a 和Get函数的 b 会指向同一个指针 m_ptr,在析构的时候会导致重复删除该指针。正确的做法是提供深拷贝的拷贝构造函数,比如下面的代码:
#include <iostream>
using namespace std;
class A
{
public:A() :m_ptr(new int(0)) {cout << "constructor A" << endl;}A(const A& a) :m_ptr(new int(*a.m_ptr)) {cout << "copy constructor A" << endl;}~A(){cout << "destructor A, m_ptr:" << m_ptr << endl;delete m_ptr;m_ptr = nullptr;}
private:int* m_ptr;
};
// 为了避免返回值优化,此函数故意这样写
A Get(bool flag)
{A a;A b;cout << "ready return" << endl;if (flag)return a;elsereturn b;
}
int main()
{{A a = Get(false); // 正确运行}cout << "main finish" << endl;return 0;
}
constructor A
constructor A
ready return
copy constructor A
destructor A, m_ptr:0x2662880
destructor A, m_ptr:0x2662830
destructor A, m_ptr:0x26628d0
main finish
移动构造函数
深拷贝可以保证拷贝构造时的安全性,但有时这种拷贝构造却是不必要的,比如上面代码中的拷贝构造就是不必要的。上面代码中的 Get 函数会返回临时变量,然后通过这个临时变量拷贝构造了一个新的对象 b,临时变量在拷贝构造完成之后就销毁了,如果堆内存很大,那么,这个拷贝构造的代价会很大,带来了额外的性能损耗。
有没有办法避免临时对象的拷贝构造呢?答案是肯定的。看下面的代码:
#include <iostream>
using namespace std;
class A
{
public:A() :m_ptr(new int(0)) {cout << "constructor A" << endl;}// 深拷贝A(const A& a) :m_ptr(new int(*a.m_ptr)) {cout << "copy constructor A" << endl;}
// 移动构造函数,可以浅拷贝A(A&& a) :m_ptr(a.m_ptr) {a.m_ptr = nullptr; // 为防止a析构时delete data,提前置空其m_ptrcout << "move constructor A" << endl;}~A(){cout << "destructor A, m_ptr:" << m_ptr << endl;if(m_ptr)delete m_ptr;}
private:int* m_ptr;
};
// 为了避免返回值优化,此函数故意这样写
A Get(bool flag)
{A a;A b;cout << "ready return" << endl;if (flag)return a;elsereturn b;
}
int main()
{{A a = Get(false); // 正确运行}cout << "main finish" << endl;return 0;
}
constructor A // Get函数的a 构造
constructor A // Get函数的b 构造
ready return
move constructor A // main函数的a 构造
destructor A, m_ptr:0 // main函数的a 析构
destructor A, m_ptr:0x2682830
destructor A, m_ptr:0x2682880
main finish
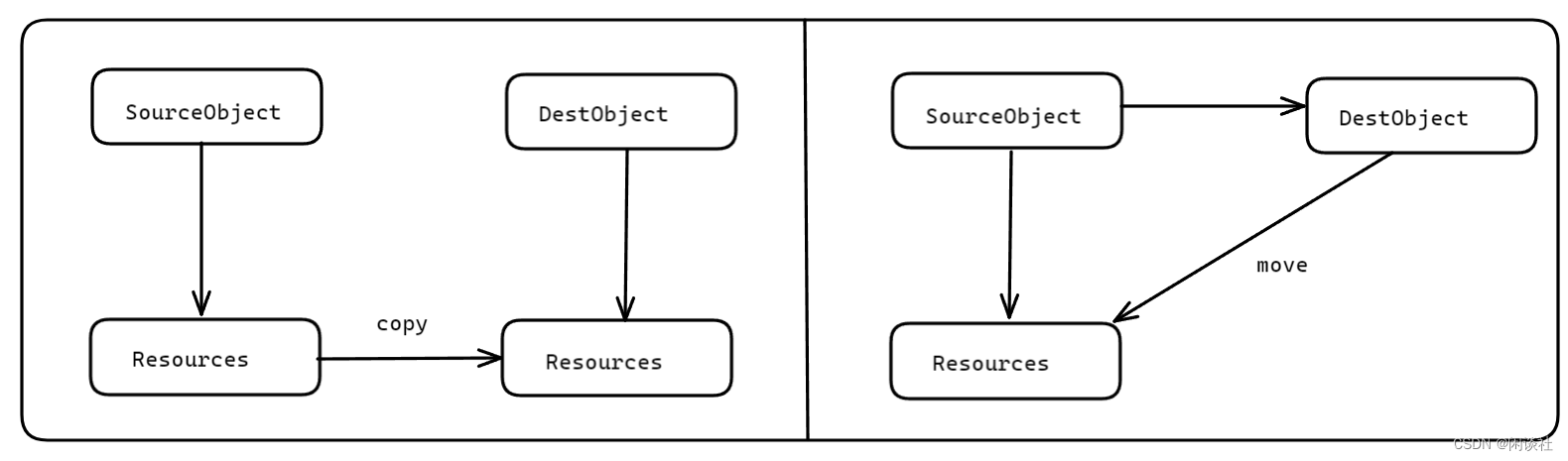
上面的代码中没有了拷贝构造,取而代之的是移动构造( Move Construct)。从移动构造函数的实现中可以看到,它的参数是一个右值引用类型的参数 A&&,这里没有深拷贝,只有浅拷贝,这样就避免了对临时对象的深拷贝,提高了性能。
这里的 A&& 用来根据参数是左值还是右值来建立分支,如果是临时值,则会选择移动构造函数。移动构造函数只是将临时对象的资源做了浅拷贝,不需要对其进行深拷贝,从而避免了额外的拷贝,提高性能。这也就是所谓的移动语义( move 语义),右值引用的一个重要目的是用来支持移动语义的。
移动语义可以将资源(堆、系统对象等)通过浅拷贝方式从一个对象转移到另一个对象,这样能够减少不必要的临时对象的创建、拷贝以及销毁,可以大幅度提高 C++ 应用程序的性能,消除临时对象的维护(创建和销毁)对性能的影响。
3.2 移动语义(move)
move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转义,没有内存拷贝。要move语义起作用,核心在于需要对应类型的构造函数支持。
#include <iostream>
#include <vector>
#include <cstdio>
#include <cstdlib>
#include <string.h>
using namespace std;
class MyString {
private:char* m_data;size_t m_len;void copy_data(const char *s) {m_data = new char[m_len+1];memcpy(m_data, s, m_len);m_data[m_len] = '\0';}
public:MyString() {m_data = NULL;m_len = 0;}MyString(const char* p) {m_len = strlen (p);copy_data(p);}MyString(const MyString& str) {m_len = str.m_len;copy_data(str.m_data);std::cout << "Copy Constructor is called! source: " << str.m_data <<std::endl;}MyString& operator=(const MyString& str) {if (this != &str) {m_len = str.m_len;copy_data(str.m_data);}std::cout << "Copy Assignment is called! source: " << str.m_data <<std::endl;return *this;}// 用c++11的右值引用来定义这两个函数MyString(MyString&& str) {std::cout << "Move Constructor is called! source: " << str.m_data <<std::endl;m_len = str.m_len;m_data = str.m_data; //避免了不必要的拷贝str.m_len = 0;str.m_data = NULL;}MyString& operator=(MyString&& str) {std::cout << "Move Assignment is called! source: " << str.m_data <<std::endl;if (this != &str) {m_len = str.m_len;m_data = str.m_data; //避免了不必要的拷贝str.m_len = 0;str.m_data = NULL;}return *this;}virtual ~MyString() {if (m_data) free(m_data);}
};
int main()
{cout << "=================="<<endl;MyString a;cout << "=================="<<endl;a = MyString("Hello"); // Move Assignmentcout << "=================="<<endl;MyString b = a; // Copy Constructorcout << "=================="<<endl;MyString c = std::move(a); // Move Constructor is called! move将左值转为右值cout << "=================="<<endl;std::vector<MyString> vec;vec.push_back(MyString("World")); // Move Constructor is called!cout << "=================="<<endl;return 0;
}
==================
==================
Move Assignment is called! source: Hello
==================
Copy Constructor is called! source: Hello
==================
Move Constructor is called! source: Hello
==================
Move Constructor is called! source: World
==================
有了右值引用和转移语义,我们在设计和实现类时,对于需要动态申请大量资源的类,应该设计右值引用的拷贝构造函数和赋值函数,以提高应用程序的效率
3.3 完美转发 forward
forward 完美转发实现了参数在传递过程中保持其值属性的功能,即若是左值,则传递之后仍然是左值,若是右值,则传递之后仍然是右值。
现存在一个函数
Template<class T>
void func(T &&val);
根据前面所描述的,这种引用类型既可以对左值引用,亦可以对右值引用。
但要注意,引用以后,这个val值它本质上是一个左值!比如
int &&a = 10;
int &&b = a; //错误
注意这里,a是一个右值引用,但其本身a也有内存名字,所以a本身是一个左值,再用右值引用引用a这是不对的。
因此我们有了std::forward()完美转发,这种T &&val中的val是左值,但如果我们用std::forward (val),就会按照参数原来的类型转发
int &&a = 10;
int &&b = std::forward<int>(a);
范例:
#include <iostream>
using namespace std;template <class T>
void Print(T &v)
{cout << "L" << v << endl;
}template <class T>
void Print(T &&v)
{cout << "R" << v << endl;
}template <class T>
void func(T &&v)
{Print(v);Print(std::move(v)); // move返回的是右值引用Print(std::forward<T>(v)); // 按参数原来的类型转发,比如fun(1),此时v原来是右值
}int main()
{cout << "-- func(1)" << endl;func(1); // 1是右值,但是T &&v = 1, v本身是左值cout << "\n-- func(x)" << endl;int x = 10;int y = 20;func(x); // x本身是左值cout << "\n-- func(std::forward<int>(y))" << endl;func(std::forward<int>(y)); //T为int,以右值方式转发ycout << "\n-- func(std::forward<int&>(y))" << endl;func(std::forward<int&>(y)); // T为int&,以左值方式转发ycout << "\n-- func(std::forward<int&&>(y))" << endl;func(std::forward<int&&>(y));return 0;
}
-- func(1)
L1
R1
R1-- func(x)
L10
R10
L10-- func(std::forward<int>(y))
L20
R20
R20-- func(std::forward<int&>(y))
L20
R20
L20-- func(std::forward<int&&>(y))
L20
R20
R20
func(1) :由于1是右值,所以未定的引用类型T&&v被一个右值初始化后变成了一个右值引用。在func()函数体内部,调用PrintT(v) 时,v又变成了一个左值(T &&v = 1, v本身是左值)。因此,示例测试结果第一个PrintT被调用,打印出"L1"。
调用PrintT(std::forward(v))时,由于std::forward会按参数原来的类型转发,因此,它还是一个右值(这里已经发生了类型推导,即参数v本身是1,右值),所以这里会调用void PrintT(T&&v)函数打印 “R1”。调用PrintT(std::move(v))是将v变成一个右值(v本身也是右值),因此,它将输出”R1"。
func(x):由于x是左值,未定的引用类型T&&v被一个左值初始化后变成了一个左值引用。因此,在调用PrintT(std::forward(v))时它会被转发到void PrintT(T&t)。
#include "stdio.h"
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
class A
{
public:A() : m_ptr(NULL), m_nSize(0) {}A(int *ptr, int nSize){m_nSize = nSize;m_ptr = new int[nSize];printf("A(int *ptr, int nSize) m_ptr:%p\n", m_ptr);if (m_ptr){memcpy(m_ptr, ptr, sizeof(sizeof(int) * nSize));}}A(const A &other) // 拷贝构造函数实现深拷贝{m_nSize = other.m_nSize;if (other.m_ptr){printf("A(const A &other) m_ptr:%p\n", m_ptr);if(m_ptr)delete[] m_ptr;printf("delete[] m_ptr\n");m_ptr = new int[m_nSize];memcpy(m_ptr, other.m_ptr, sizeof(sizeof(int) * m_nSize));}else{if(m_ptr)delete[] m_ptr;m_ptr = NULL;}cout << "A(const int &i)" << endl;}// 右值引用移动构造函数A(A &&other){m_ptr = NULL;m_nSize = other.m_nSize;if (other.m_ptr){m_ptr = move(other.m_ptr); // 移动语义other.m_ptr = NULL;}}~A(){if (m_ptr){delete[] m_ptr;m_ptr = NULL;}}void deleteptr(){if (m_ptr){delete[] m_ptr;m_ptr = NULL;}}int *m_ptr = NULL; // 增加初始化int m_nSize = 0;
};
int main()
{int arr[] = {1, 2, 3};A a(arr, sizeof(arr) / sizeof(arr[0]));cout << "m_ptr in a Addr: 0x" << a.m_ptr << endl;cout<< "================" <<endl;A b(a);cout << "m_ptr in b Addr: 0x" << b.m_ptr << endl;b.deleteptr();cout<< "================" <<endl;A c(std::forward<A>(a)); // T为A,以右值方式完美转换acout << "m_ptr in c Addr: 0x" << c.m_ptr << endl;c.deleteptr();cout<< "================" <<endl;vector<int> vect{1, 2, 3, 4, 5};cout << "before move vect size: " << vect.size() << endl;vector<int> vect1 = move(vect);cout << "after move vect size: " << vect.size() << endl;cout << "new vect1 size: " << vect1.size() << endl;return 0;
}
A(int *ptr, int nSize) m_ptr:0000000000EA1C00
m_ptr in a Addr: 0x0xea1c00
================
A(const A &other) m_ptr:0000000000000000
delete[] m_ptr
A(const int &i)
m_ptr in b Addr: 0x0xea1c20
================
m_ptr in c Addr: 0x0xea1c00
================
before move vect size: 5
after move vect size: 0
new vect1 size: 5
3.4 emplace_back 减少内存拷贝和移动
emplace_back是就地构造,不用构造后再次复制到容器中。因此效率更高。
考虑这样的语句:
vector<string> testVec;
testVec.push_back(string(16, 'a'));
上述语句将一个string对象添加到testVec中。底层实现:
1)首先,string(16, ‘a’)会创建一个string类型的临时对象,这涉及到一次string构造过程。
2)其次,vector内会创建一个新的string对象,这是第二次构造。
3)最后在push_back结束时,最开始的临时对象会被析构。加在一起,这两行代码会涉及到两次string构造和一次析构。
c++11可以用emplace_back代替push_back,emplace_back可以直接在vector中构建一个对象,而非创建一个临时对象,再放进vector,再销毁。emplace_back可以省略一次构建和一次析构,从而达到优化的目的。
四、小结
C++11 在性能上做了很大的改进,最大程度减少了内存移动和复制,通过右值引用、 forward、emplace 和一些无序容器,可以大幅度改进程序性能。
- 右值引用仅仅是通过改变资源的所有者(剪切方式,而不是拷贝方式)来避免内存的拷贝,能大幅度提高性能。
- forward 能根据参数的实际类型转发给正确的函数(参数用 &&的方式)。
- emplace 系列函数通过直接构造对象的方式避免了内存的拷贝和移动。
本专栏知识点是通过<零声教育>的系统学习,进行梳理总结写下文章,对c/c++linux课程感兴趣的读者,可以点击链接,详细查看详细的服务器课程