模型来源:
算法工程师训练得到的onnx模型
c++对模型的转换:
拿到onnx模型后,通过tensorRT将onnx模型转换为对应的engine模型,注意:训练用的tensorRT版本和c++调用的tensorRT版本必须一致。
如何转换:
- 算法工程师直接转换为.engine文件进行交付。
- 自己转换,进入tensorRT安装目录\bin目录下,将onnx模型拷贝到bin目录,地址栏中输入cmd回车弹出控制台窗口,然后输入转换命令,如:
trtexec --onnx=model.onnx --saveEngine=model.engine --workspace=1024 --optShapes=input:1x13x512x640 --fp16
然后回车,等待转换完成,完成后如图所示:
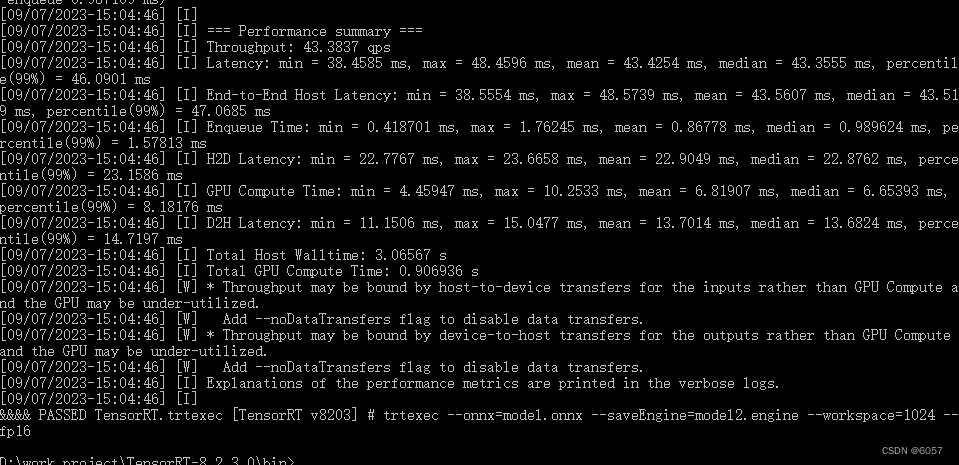
并且在bin目录下生成.engine模型文件。
c++对.engine模型文件的调用和推理
首先将tensorRT对模型的加载及推理进行封装,命名为CTensorRT.cpp,老样子贴代码:
//CTensorRT.cpp
class Logger : public nvinfer1::ILogger {void log(Severity severity, const char* msg) noexcept override {if (severity <= Severity::kWARNING)std::cout << msg << std::endl;}
};Logger logger;
class CtensorRT
{
public:CtensorRT() {}~CtensorRT() {}private:std::shared_ptr<nvinfer1::IExecutionContext> _context;std::shared_ptr<nvinfer1::ICudaEngine> _engine;nvinfer1::Dims _inputDims;nvinfer1::Dims _outputDims;
public:void cudaCheck(cudaError_t ret, std::ostream& err = std::cerr){if (ret != cudaSuccess){err << "Cuda failure: " << cudaGetErrorString(ret) << std::endl;abort();}}bool loadOnnxModel(const std::string& filepath){auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(logger));if (!builder){return false;}const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));if (!network){return false;}auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());if (!config){return false;}auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, logger));if (!parser){return false;}parser->parseFromFile(filepath.c_str(), static_cast<int32_t>(nvinfer1::ILogger::Severity::kWARNING));std::unique_ptr<IHostMemory> plan{ builder->buildSerializedNetwork(*network, *config) };if (!plan){return false;}std::unique_ptr<IRuntime> runtime{ createInferRuntime(logger) };if (!runtime){return false;}_engine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan->data(), plan->size()));if (!_engine){return false;}_context = std::shared_ptr<nvinfer1::IExecutionContext>(_engine->createExecutionContext());if (!_context){return false;}int nbBindings = _engine->getNbBindings();assert(nbBindings == 2); // 输入和输出,一共是2个for (int i = 0; i < nbBindings; i++){if (_engine->bindingIsInput(i))_inputDims = _engine->getBindingDimensions(i); // (1,3,752,752)else_outputDims = _engine->getBindingDimensions(i);}return true;}bool loadEngineModel(const std::string& filepath){std::ifstream file(filepath, std::ios::binary);if (!file.good()){return false;}std::vector<char> data;try{file.seekg(0, file.end);const auto size = file.tellg();file.seekg(0, file.beg);data.resize(size);file.read(data.data(), size);}catch (const std::exception& e){file.close();return false;}file.close();auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(logger));_engine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(data.data(), data.size()));if (!_engine){return false;}_context = std::shared_ptr<nvinfer1::IExecutionContext>(_engine->createExecutionContext());if (!_context){return false;}int nbBindings = _engine->getNbBindings();assert(nbBindings == 2); // 输入和输出,一共是2个// 为输入和输出创建空间for (int i = 0; i < nbBindings; i++){if (_engine->bindingIsInput(i))_inputDims = _engine->getBindingDimensions(i); //得到输入结构else_outputDims = _engine->getBindingDimensions(i);//得到输出结构}return true;}void ONNX2TensorRT(const char* ONNX_file, std::string save_ngine){// 1.创建构建器的实例nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);// 2.创建网络定义uint32_t flag = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);nvinfer1::INetworkDefinition* network = builder->createNetworkV2(flag);// 3.创建一个 ONNX 解析器来填充网络nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, logger);// 4.读取模型文件并处理任何错误parser->parseFromFile(ONNX_file, static_cast<int32_t>(nvinfer1::ILogger::Severity::kWARNING));for (int32_t i = 0; i < parser->getNbErrors(); ++i){std::cout << parser->getError(i)->desc() << std::endl;}// 5.创建一个构建配置,指定 TensorRT 应该如何优化模型nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();// 7.指定配置后,构建引擎nvinfer1::IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);// 8.保存TensorRT模型std::ofstream p(save_ngine, std::ios::binary);p.write(reinterpret_cast<const char*>(serializedModel->data()), serializedModel->size());// 9.序列化引擎包含权重的必要副本,因此不再需要解析器、网络定义、构建器配置和构建器,可以安全地删除delete parser;delete network;delete config;delete builder;// 10.将引擎保存到磁盘,并且可以删除它被序列化到的缓冲区delete serializedModel;}uint32_t getElementSize(nvinfer1::DataType t) noexcept{switch (t){case nvinfer1::DataType::kINT32: return 4;case nvinfer1::DataType::kFLOAT: return 4;case nvinfer1::DataType::kHALF: return 2;case nvinfer1::DataType::kBOOL:case nvinfer1::DataType::kINT8: return 1;}return 0;}int64_t volume(const nvinfer1::Dims& d){return std::accumulate(d.d, d.d + d.nbDims, 1, std::multiplies<int64_t>());}bool infer(unsigned char* input, int real_input_size, cv::Mat& out_mat){tensor_custom::BufferManager buffer(_engine);cudaStream_t stream;cudaStreamCreate(&stream); // 创建异步cuda流int binds = _engine->getNbBindings();for (int i = 0; i < binds; i++){if (_engine->bindingIsInput(i)){size_t input_size;float* host_buf = static_cast<float*>(buffer.getHostBufferData(i, input_size));memcpy(host_buf, input, real_input_size);break;}}// 将输入传递到GPUbuffer.copyInputToDeviceAsync(stream);// 异步执行bool status = _context->enqueueV2(buffer.getDeviceBindngs().data(), stream, nullptr);if (!status)return false;buffer.copyOutputToHostAsync(stream);for (int i = 0; i < binds; i++){if (!_engine->bindingIsInput(i)){size_t output_size;float* tmp_out = static_cast<float*>(buffer.getHostBufferData(i, output_size));//do your something herebreak;}}cudaStreamSynchronize(stream);cudaStreamDestroy(stream);return true;}
};
调用方式
int main()
{vector<int> dims = { 1,13,512,640 };vector<float> vall;for (int i=0;i<13;i++){string file = "D:\\xxx\\" + to_string(i) + ".png";cv::Mat mt = imread(file, IMREAD_GRAYSCALE);cv::resize(mt, mt, cv::Size(640,512));mt.convertTo(mt, CV_32F, 1.0 / 255);cv::Mat shape_xr = mt.reshape(1, mt.total() * mt.channels());std::vector<float> vec_xr = mt.isContinuous() ? shape_xr : shape_xr.clone();vall.insert(vall.end(), vec_xr.begin(), vec_xr.end());}cv::Mat mt_4d(4, &dims[0], CV_32F, vall.data());string engine_model_file = "model.engine";CtensorRT cTensor;if (cTensor.loadEngineModel(engine_model_file)){cv::Mat out_mat;if (!cTensor.infer(mt_4d.data, vall.size() * 4, out_mat))std::cout << "infer error!" << endl;elsecv::imshow("out", out_mat);}elsestd::cout << "load model file failed!" << endl;cv::waitKey(0);return 0;
}