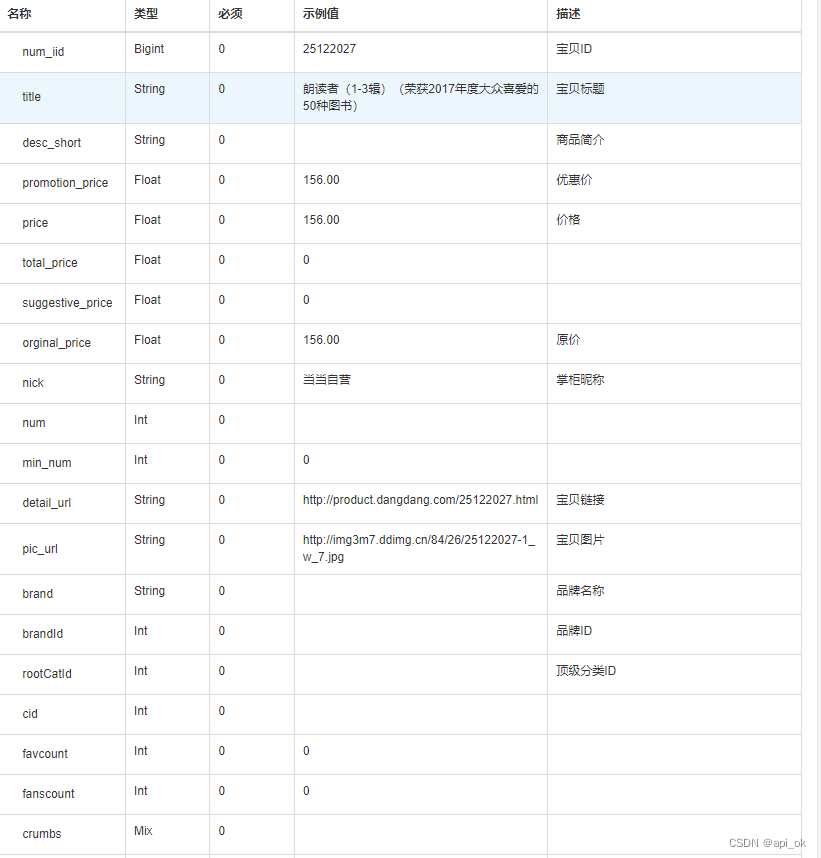
案例1-TOP N个数据的值
输入数据:
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27处理代码:
def main(args: Array[String]): Unit = {//创建SparkContext对象val conf:SparkConf = new SparkConf()conf.setAppName("test1").setMaster("local")val sc: SparkContext = new SparkContext(conf)var index: Int = 0//通过加载本地文件系统的数据创建RDD对象val rdd: RDD[String] = sc.textFile("data/file1.txt")rdd.filter(line=>line.split(",").length == 4).map(line=>line.split(",")(2)).map(word=>(word.toInt,1)).sortByKey(false).map(kv=>kv._1).take(5).foreach(key=>{index += 1println(index + s"\t$key")})//关闭SparkContext对象sc.stop()}代码解析:
-
sc.textFile("data/file1.txt"):通过加载本地文件来创建RDD对象 -
rdd.filter(line=>line.split(",").length == 4):确保数据的完整性 -
map(line=>line.split(",")(2)):通过逗号将一行字符串分隔开来组成一个Array数组并取出数组中第3个严肃 -
map(word=>(word.toInt,1)):因为我们的sortByKey方法是针对键值对进行操作的,所以必须把我们上面取出来的值转为(值,x)形式的键值对。
-
sortByKey(false):设置参数为false表示降序排列。
-
map(kv=>kv._1).take(5):取出top五。
案例2-文件排序
要求:输入三个文件(每行一个数字),要求输出一个文件,文件内文本格式为(序号 数值)。
def main(args: Array[String]): Unit = {val conf:SparkConf = new SparkConf()conf.setAppName("test2").setMaster("local")val sc: SparkContext = new SparkContext(conf)//通过加载本地文件系统的数据创建RDD对象val rdd: RDD[String] = sc.textFile("data/sort",3)var index = 0val rdd2 = rdd.map(num => (num.toInt,1)).partitionBy(new HashPartitioner(1)).sortByKey().map(t=>{index += 1println(index+"\t"+t._1)(index,t._1)})//只要调用 行动操作语句 才会触发真正的从头到尾的计算
// rdd2.foreach(println)//关闭SparkContext对象sc.stop()}我们会发现,如果我们不调用 foreach 这个行动操作而是直接在转换操作中进行输出的话,这样是输出不来结果的,所以我们必须要调用行动操作。
而且,我们必须对分区进行归并,因为在分布式环境下,只有把多个分区合并成一个分区,才能使得结果整体有序。(这里尽管我们是本地测试,数据源是一个目录下的文件,但是我们也要考虑到假如是在分布式环境下的情况)
运行结果:
案例3-二次排序
要求:对格式为(数值 数值)类型的数据进行排序,假如第一个数值相同,则比较第二个数值。
import com.study.spark.core.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}class SecondarySortKey(val first:Int,val second:Int) extends Ordered[SecondarySortKey] with Serializable {override def compare(other: SecondarySortKey): Int = {if (this.first - other.first != 0) {this.first - other.first}else{this.second-other.second}}
}
object SecondarySortKey{def main(args: Array[String]): Unit = {val conf:SparkConf = new SparkConf()conf.setAppName("test3").setMaster("local")val sc: SparkContext = new SparkContext(conf)val rdd: RDD[String] = sc.textFile("data/sort/test03.txt")val rdd2: RDD[(SecondarySortKey, String)] = rdd.map(line => (new SecondarySortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt), line))rdd2.sortByKey(false).map(t=>t._2).foreach(println)sc.stop()}
}这里我们使用了自定义的类并继承了Ordered 和 Serializable 这两个特质,为了实现自定义的排序规则。 其中,Ordered 特质的混入需要重写它的 compare 方法来实现我们的自定义比较规则,而 Serializable 的混入作用是使得我们的对象可以序列化,以便在网络中可以传输。
运行结果:
8 3
5 6
5 3
4 9
4 7
3 2
1 6