前言
马上就要过年了,有许多小伙伴们本本还没拿到,还在苦苦刷题,一直及格不了,现在,我们用Python模拟做题,看看效果。
环境使用
- python 3.9
- pycharm
模块使用
- requests
- re
- selenium
- 谷歌驱动
import reimport requestsfrom selenium import webdriver模块介绍
- requests
requests简介:使用requests可以模拟浏览器的请求,比起之前用的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
- re
re又名正则表达式,是一种小型语言,其作用范围为字符串,内嵌在python中,通过调用re模块实现,其底层通过C语言编写的匹配法则进行匹配
作用目的:通过编写的匹配规则对字符串进行模糊匹配,比字符串内置方法更为强大,字符串内置方法只能进行精准匹配
- selenium
之前,我们爬虫是模拟浏览器,但始终不是用的浏览器,但今天我们要说的是另一种爬虫方式,这次不是模拟浏览器,而是用程序去控制浏览器进行一些列操作,也就是selenium。selenium是python的一个第三方库,对外提供的接口可以操控浏览器,比如说输入、点击,跳转,下拉等动作。
在使用selenium模块之前要做两件事,一是安装selenium模块,可以用终端用pip,也可以在pycharm里的setting安装;二是我们需要下载一款浏览器驱动程序,下载的驱动程序要和浏览器的版本一致。
- 谷歌驱动
1.下载网址
CNPM Binaries Mirror
2.文件安装(放置)位置
可以把这个文件理解成一个脚本入口。说它是安装,其实就是把下载的 chromedriver.exe 文件复制到相应的位置。将文件复制到两个位置:1...\python\Scripts复制一份到安装Python的文件夹中的Scripts文件夹中;2.如果用的是Pycharm,再复制一份到..\python\site-packages\selenium\webdriver\chrome文件中。这个地址可以将鼠标放在Pycharm里面安装库的地方的相应库上就能看到。
代码实现
我们打开在线驾驶员考试科目一考试的网址。代码如下:
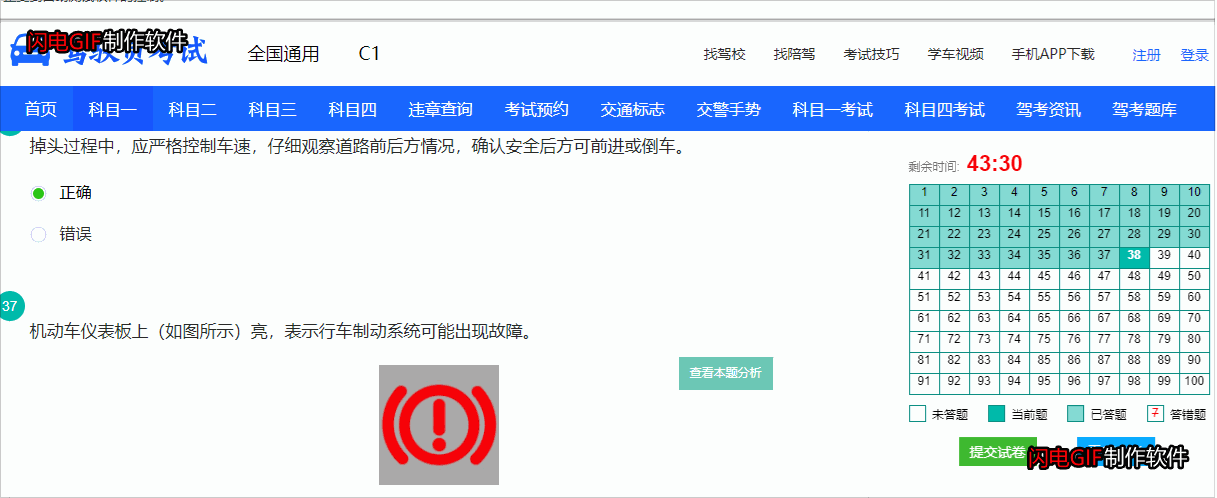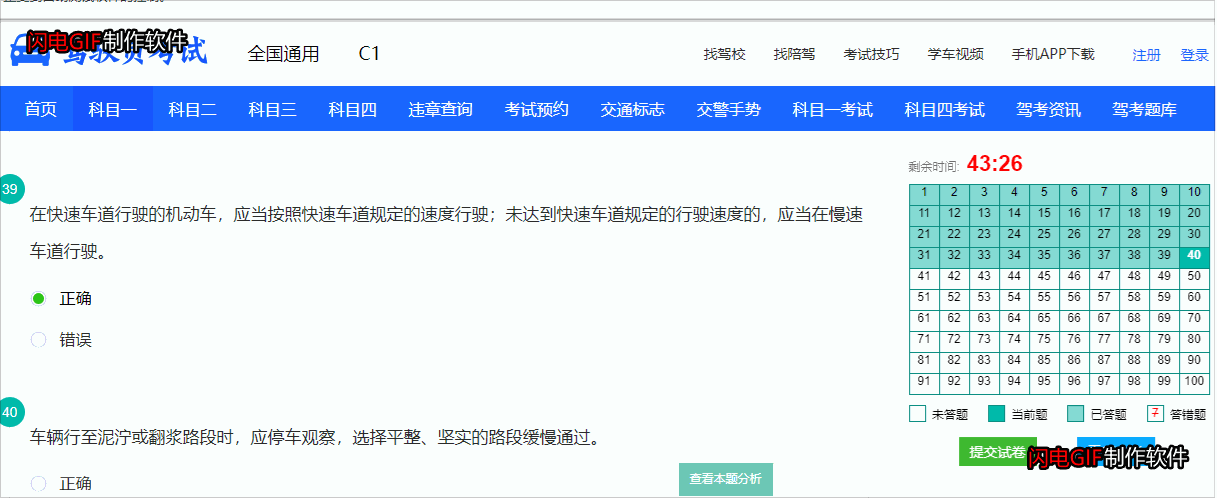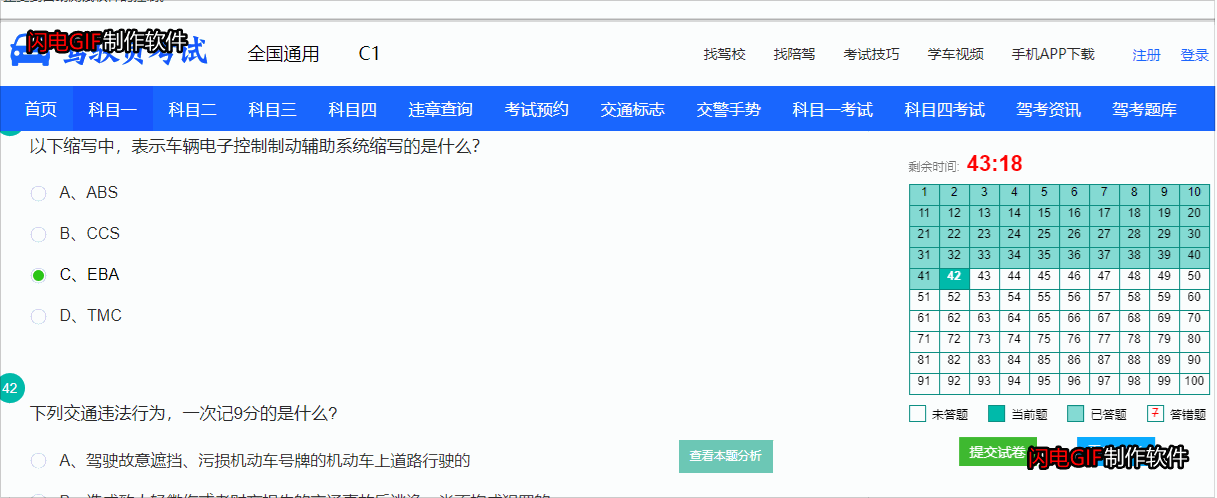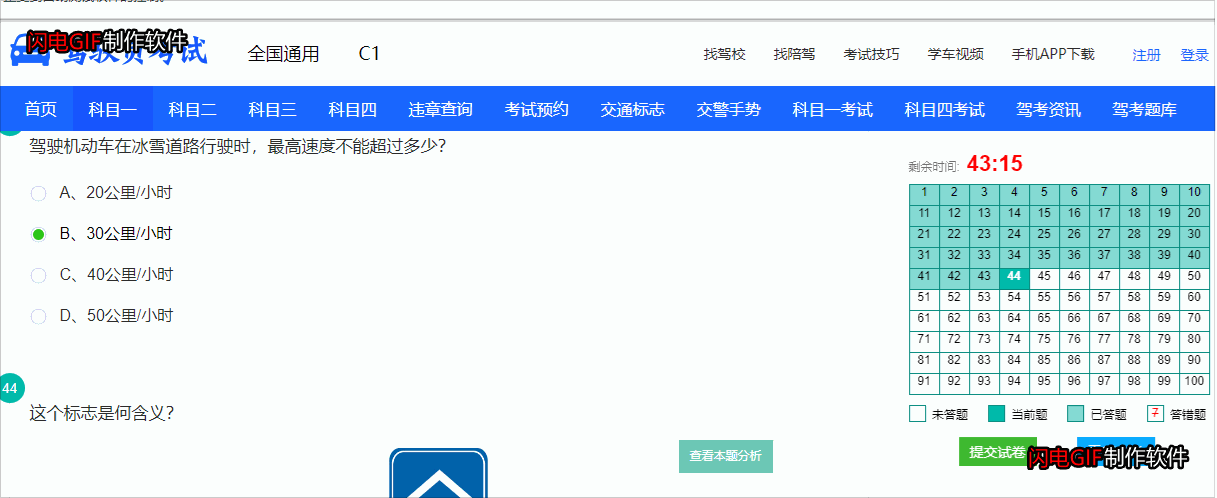
driver = webdriver.Chrome()driver.get('https://www.jsyks.com/kmy-mnks')运行效果如下:
我们发现每道题目后面都有查看本题分析,点击进去之后,我们就可以看到这题答案,通过对比 分析发现,答案网址有一定的规律,只是后缀不一样,我们称之为该题的编号或者是答案id。后来我们又发现考试页面就有我们所需要的答案id。
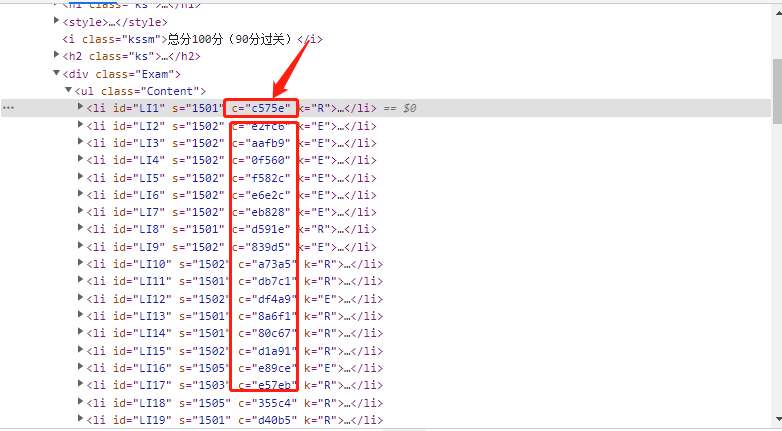
下面我们提取答案id。
# 获取答案idlis = driver.find_elements(By.CSS_SELECTOR, 'div.Exam ul.Content li')for循环遍历,获取li标签的c属性 get_attribute
for li in lis:answer_id = li.get_attribute('c')接下来,我们开始拼接答案的网址。
answer_url = f'https://tiba.jsyks.com/Post/{answer_id}.htm'我们获得网址之后,发起请求,获取数据,解析数据,获得我们想要的数据,使用正则表达式去匹配答案的内容。
html_data = requests.get(answer_url).textanswer = re.findall('<br/>答案:<u>(.*?)</u></h1><p>', html_data)[0]我们请求之后,发现答案和我们题目的选项有细微的差别,对和正确,错和错误,我们是只是什么意思,但是机器不知道什么意思,所以需要我们转换数据。
if answer == '错':answer = '错误'elif answer == '对':answer = '正确'做完这些,就需要将选项和答案进行比较,首先是选项匹配:
bs = li.find_elements(By.CSS_SELECTOR, 'b') 答案和选项比较:
for b in bs:choose = b.textif len(choose) > 2:choose = choose[0]if answer == choose:b.click()到这里我们所有的题目就做完了,接下来是交卷。
driver.find_element(By.CSS_SELECTOR, '.btnJJ').click()运行完代码,我们会发现我们获得了满分。
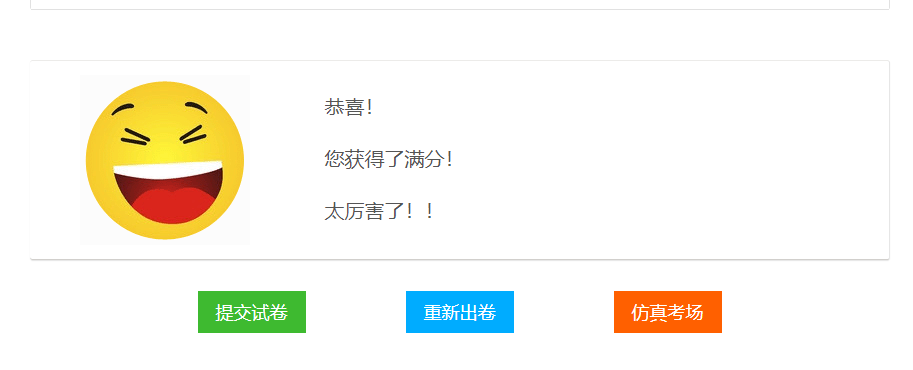
玩归玩,闹归闹,还是要好好做题。