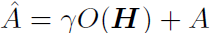两台服务器的主机名
hostname
ssh ecs-qar1-0001
ssh ecs-qar1-0002
配置jdk
vim /etc/profile
旧有的
export JAVA_HOME=/usr/java/openjdk-8u41
export JAVA_HOME=/bigdata/server/jdk
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
export MAVEN_HOME=/work/apache-maven-3.5.4
export PATH= M A V E N H O M E / b i n : MAVEN_HOME/bin: MAVENHOME/bin:PATH
rm -f /usr/bin/java
ln -s /bigdata/server/jdk/bin/java /usr/bin/java
查看系统
lsb_release -a
cat /etc/redhat-release
查看java版本
whereis java
which java (java执行路径)
echo $JAVA_HOME
如果配置没生效需要重启系统
reboot 重启系统
echo $PATH
# 配置hadoop
## 配置
ecs-qar1-0001
ecs-qar1-0002## 配置hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/bigdata/server/jdk
export HADOOP_HOME=/bigdata/server/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
配置core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://ecs-qar1-0002:8020</value><description>hdfs默认地址与端口</description></property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
配置hdfs-site.xml
<configuration><property><name>dfs.namenode.name.dir</name><value>/data/nn</value><description>namenode上存储hdfs名字空间元数据</description></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value><description>datanode上数据块的物理存储位置</description></property><property><name>dfs.datanode.data.dir.perm</name><value>755</value><!--dn所使用的本地文件夹的路径权限,默认755--></property><property><name>dfs.replication</name><value>2</value><!--数据需要备份的数量,不能大于集群的机器数量,默认为3--></property><property><name>dfs.namenode.hosts</name><value>ecs-qar1-0001,ecs-qar1-0002</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property>
</configuration>
vim /etc/profile
export JAVA_HOME=/bigdata/server/jdk
export HADOOP_HOME=/bigdata/server/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile# 配置hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中各添加javahome
export JAVA_HOME=/bigdata/server/jdk
配置mapred-site.xml
<configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value><description>Execution framework set to Hadoop YARN.</description>
</property>
<property><name>mapreduce.jobhistory.address</name><value>ecs-qar1-0002:10020</value>
</property>
<property><name>mapreduce.jobhistory.webapp.address</name><value>ecs-qar1-0002:19888</value>
</property>
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MAPREDUCE home设置为HADOOP_HOME</description>
</property>
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MAPREDUCE HOME 设置为HADOOP_HOME</description>
</property>
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>mAPREDUCE HOME 设置为HADOOP_HOME</description>
</property>
</configuration>
配置yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>ecs-qar1-0002</value><description>ResourceManager host.</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>中间数据存储</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>日志存储</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>shuffle服务</description></property><property><name>yarn.log.server.url</name><value>http://ecs-qar1-0002:19888/jobhistory/logs</value><description>历史服务器</description></property><property><name>yarn.log.server.web-service.url</name><value>http://ecs-qar1-0002:8188/ws/v1/applicationhistory</value></property><property><name>yarn.log.aggregation.enable</name><value>true</value><description>开启日志聚合</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>程序日志</description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value><description>公平调度器</description></property>
</configuration>
scp -r hadoop-3.3.4 ecs-qar1-0002:`pwd`/
ln -s hadoop
chown -R hadoop:hadoop hadoop*
chown -R hadoop:hadoop /data# 设置hadoop用户的ssh免密登录
ssh-keygen -t rsa
ssh-copy-id ecs-qar1-0001
ssh-copy-id ecs-qar1-0002su - hadoop
hadoop namenode -formatstart-all.sh
安装docker
安装
https://docs.docker.com/engine/install/centos/#installation-methods
开机启动
systemctl enable docker.service
systemctl is-enabled docker.service
安装docker compose
curl -SL https://github.com/docker/compose/releases/download/v2.17.2/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose