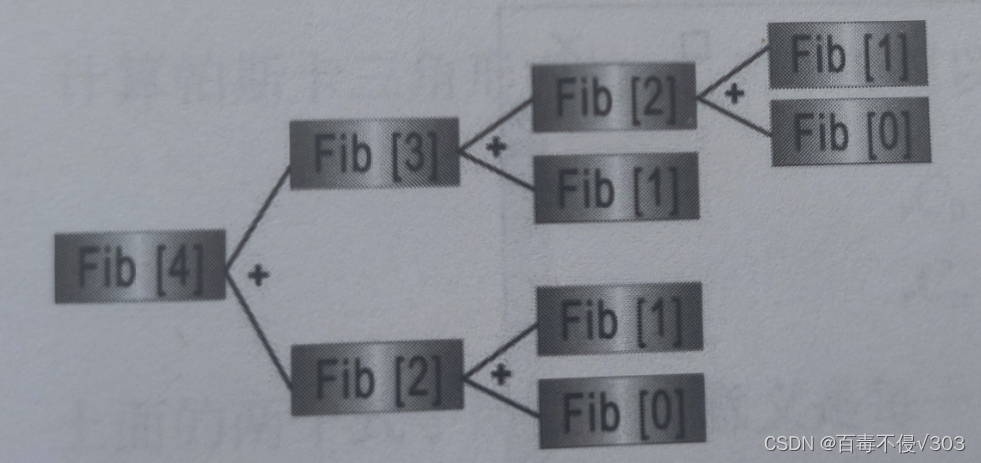
在本文中,我们尝试通过进行一些文本挖掘来发现数据科学相关概念。我们将从一篇关于数据科学的文本开始,从中提取关键字,然后尝试可视化结果。
作为文本,将使用维基百科的数据科学页面:
url = 'https://en.wikipedia.org/wiki/Data_science'
步骤1 获取数据
import requeststext = requests.get(url).content.decode('utf-8')
print(text[:1000])'''
<!DOCTYPE html>
<html class="client-nojs" lang="en" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>Data science - Wikipedia</title>
<script>document.documentElement.className="client-js";RLCONF={"wgBreakFrames":!1,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"dmy","wgMonthNames":["","January","February","March","April","May","June","July","August","September","October","November","December"],"wgRequestId":"1a104647-90de-485a-b88a-1406e889a5d1","wgCSPNonce":!1,"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":!1,"wgNamespaceNumber":0,"wgPageName":"Data_science","wgTitle":"Data science","wgCurRevisionId":1038046078,"wgRevisionId":1038046078,"wgArticleId":35458904,"wgIsArticle":!0,"wgIsRedirect":!1,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["CS1 maint: others","Articles with short description","Short description matches Wikidata","Use dmy dates from December 2012","Information science","Computer occupations"
'''
步骤2 转换数据
下一步是将数据转换为适合处理的形式。在我们的例子中,我们已经从页面下载了HTML源代码,我们需要将其转换为纯文本。
有很多方法可以做到这一点。我们将使用来自 Python 的最简单的内置 HTMLParser 对象。我们需要对 HTMLParser 类进行子类化,并定义将收集 HTML 标签内所有文本的代码, 除了"script",“style” 标签。
from html.parser import HTMLParserclass MyHTMLParser(HTMLParser):script = Falseres = ""def handle_starttag(self, tag, attrs):if tag.lower() in ["script","style"]:self.script = Truedef handle_endtag(self, tag):if tag.lower() in ["script","style"]:self.script = Falsedef handle_data(self, data):if str.strip(data)=="" or self.script:returnself.res += ' '+data.replace('[ edit ]','')parser = MyHTMLParser()
parser.feed(text)
text = parser.res
print(text[:1000])'''Data science - Wikipedia Data science From Wikipedia, the free encyclopedia Jump to navigation Jump to search Interdisciplinary field of study focused on deriving knowledge and insights from data Not to be confused with information science . The existence of Comet NEOWISE (here depicted as a series of red dots) was discovered by analyzing astronomical survey data acquired by a space telescope , the Wide-field Infrared Survey Explorer . Part of a series on Machine learning and data mining Problems Classification Clustering Regression Anomaly detection AutoML Association rules Reinforcement learning Structured prediction Feature engineering Feature learning Online learning Semi-supervised learning Unsupervised learning Learning to rank Grammar induction Supervised learning ( classification • regression ) Decision trees Ensembles Bagging Boosting Random forest k -NN Linear regression Naive Bayes Artificial neural networks Logistic regression Perceptron Relevance vector machine
'''
步骤3 得到结果
最重要的一步是将我们的数据转化为某种形式,我们可以从中得出结果。在我们的例子中,我们想从文本中提取关键字,看看哪些关键字更有意义。
我们将使用名为RAKE的Python库进行关键字提取。首先,让我们安装这个库,以防它不存在:
import sys
!{sys.executable} -m pip install nlp_rake'''
Requirement already satisfied: nlp_rake in c:\winapp\miniconda3\lib\site-packages (0.0.2)
Requirement already satisfied: numpy>=1.14.4 in c:\winapp\miniconda3\lib\site-packages (from nlp_rake) (1.19.5)
Requirement already satisfied: pyrsistent>=0.14.2 in c:\winapp\miniconda3\lib\site-packages (from nlp_rake) (0.17.3)
Requirement already satisfied: regex>=2018.6.6 in c:\winapp\miniconda3\lib\site-packages (from nlp_rake) (2021.8.3)
Requirement already satisfied: langdetect>=1.0.8 in c:\winapp\miniconda3\lib\site-packages (from nlp_rake) (1.0.9)
Requirement already satisfied: six in c:\winapp\miniconda3\lib\site-packages (from langdetect>=1.0.8->nlp_rake) (1.16.0)
C:\winapp\Miniconda3\lib\site-packages\secretstorage\dhcrypto.py:16: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes insteadfrom cryptography.utils import int_from_bytes
C:\winapp\Miniconda3\lib\site-packages\secretstorage\util.py:25: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes insteadfrom cryptography.utils import int_from_bytes
WARNING: Ignoring invalid distribution -umpy (c:\winapp\miniconda3\lib\site-packages)
WARNING: Ignoring invalid distribution -umpy (c:\winapp\miniconda3\lib\site-packages)
WARNING: Ignoring invalid distribution -umpy (c:\winapp\miniconda3\lib\site-packages)
WARNING: Ignoring invalid distribution -umpy (c:\winapp\miniconda3\lib\site-packages)
WARNING: Ignoring invalid distribution -umpy (c:\winapp\miniconda3\lib\site-packages)
'''
主要功能可从 Rake 对象获得,我们可以使用一些参数对其进行自定义。在我们的例子中,我们将关键字的最小长度设置为 5 个字符,将文档中关键字的最小频率设置为 3,将关键字中的最大单词数设置为 2。随意使用其他值并观察结果。
import nlp_rake
extractor = nlp_rake.Rake(max_words=2,min_freq=3,min_chars=5)
res = extractor.apply(text)
res'''
[('machine learning', 4.0),('big data', 4.0),('data scientist', 4.0),('21st century', 4.0),('data science', 3.909090909090909),('computer science', 3.909090909090909),('information science', 3.797979797979798),('data analysis', 3.666666666666667),('application domains', 3.6),('science', 1.9090909090909092),('field', 1.25),('statistics', 1.2272727272727273),('classification', 1.2),('techniques', 1.1666666666666667),('datasets', 1.0),('education', 1.0),('archived', 1.0),('original', 1.0),('chikio', 1.0),('forbes', 1.0)]
'''
我们获得了一个列表术语以及相关的重要性程度。如您所见,最相关的学科(例如机器学习和大数据)出现在列表中排名靠前的位置。
步骤4 可视化结果
人们可以以视觉形式最好地解释数据。因此,可视化数据以得出一些见解通常是有意义的。我们可以在 Python 中使用 matplotlib 库来绘制关键字及其相关性的简单分布:
import matplotlib.pyplot as pltdef plot(pair_list):k,v = zip(*pair_list)plt.bar(range(len(k)),v)plt.xticks(range(len(k)),k,rotation='vertical')plt.show()plot(res)

然而,还有更好的方法来可视化单词频率 - 使用词云。我们需要安装另一个库来从关键字列表中绘制词云。
!{sys.executable} -m pip install wordcloud
WordCloud对象负责接收原始文本或预先计算的单词列表及其频率,以及返回和图像,然后可以使用matplotlib显示:
from wordcloud import WordCloud
import matplotlib.pyplot as pltwc = WordCloud(background_color='white',width=800,height=600)
plt.figure(figsize=(15,7))
plt.imshow(wc.generate_from_frequencies({ k:v for k,v in res }))

我们也可以将原始文本传递给 WordCloud - 让我们看看我们是否能够得到类似的结果:
plt.figure(figsize=(15,7))
plt.imshow(wc.generate(text))

wc.generate(text).to_file('images/ds_wordcloud.png')'''
<wordcloud.wordcloud.WordCloud at 0x224b99d76a0>
'''
您可以看到词云现在看起来更令人印象深刻,但它也包含很多噪音(例如,不相关的单词,例如检索到)。此外,我们得到的由两个词组成的关键字更少,例如数据科学家或计算机科学。这是因为RAKE算法在从文本中选择好的关键字方面做得更好。这个例子说明了数据预处理和清理的重要性,因为最后的清晰图片将使我们能够做出更好的决策。
在这个练习中,我们经历了一个简单的过程,以关键字和词云的形式从维基百科文本中提取一些含义。这个例子非常简单,但它很好地展示了数据科学家在处理数据时将采取的所有典型步骤,从数据采集到可视化。