1、背景
TieredMergePolicy 作为 Elasticserach 默认的策略,和 LogMergePolicy 合并相邻的段不同,其合并大小相近的段。
作为 ES 使用的段策略,它的核心思想是将索引段分成多个层次(tier),每个层次的段大小会有一个预设的上限。
当某一层的段数量超过阈值或者某个段的大小达到阈值时,就会触发合并操作,将多个小段合并成一个较大的段。
通俗理解分层
为更好地辅助大家理解“分层”,这里给个通俗类比描述如下:
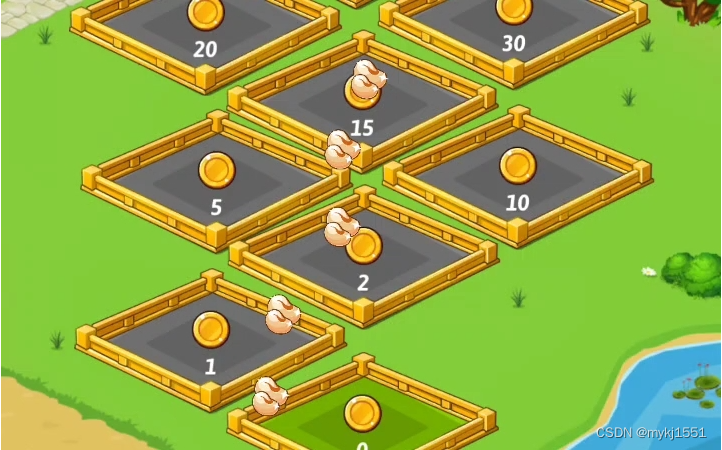
我们可以将书比作文档,桌面上的堆积的书表示一个索引中的段,不同大小的书堆代表不同大小的段。当桌子上的书太多时,为了节省空间和使工作台更整洁,我们可能会决定合并一些小堆书,组成一个大堆。但大堆书因为合并的代价大,所以不会频繁地进行整理或合并。当我们确实需要更多空间时,例如想在桌子上放一个大物件,这时我们可能会考虑整理大堆书。
小堆策略: 任何少于5本的书堆,你会把它们合并成一个堆。这是为了快速整理小堆书籍。
中等堆策略: 当你的书桌上有3个这样的5本书的堆时,你会把它们合并成一个15本书的堆。
大堆策略: 任何超过20本的书的堆,你只会在非常必要的情况下(比如桌子上没地方了)才会去整理它们。
这样的比喻可以更生动地描述TieredMergePolicy的工作原理。
| 桌比喻 | TieredMergePolicy | 说明 |
|---|---|---|
| 小堆书(<5本) | 小的索引段 | 这些小段经常被合并,就像我们经常整理桌上的小堆书来为更大的物件腾地方。 |
| 中等堆书(~15本) | 中等大小的索引段 | 较小的段可能会被合并成这种中等大小的段,它们之间的合并频率较小堆要低一些。 |
| 大堆书(>20本) | 大的索引段 | 这些大段不经常被合并,就像我们不常重新整理大堆书。只有在空间不足时才会考虑整理它们。 |
| 合并几个小堆书 | 合并小段 | 为了节省空间和保持工作台整洁,我们会优先合并小堆书。 |
| 将几个中等堆书合并成大堆 | 将几个中等大小的段合并 | 当有过多的中等大小的段时,它们可能会被合并为一个大段,以减少段的数量和提高性能。 |
| 只在必要时整理大堆书 | 只在必要时合并大段 | 大段的合并是代价高昂的,所以不经常发生。只有在空间紧张或需要优化性能时,我们才考虑整理大堆书。 |
TieredMergePolicy 的特点包括:
多层次合并: 将段分成多个不同层次,每个层次的大小不同。
渐进合并: 段会逐渐从一个层次合并到另一个层次(因为大小有变化),以控制合并操作的频率和开销。
根据大小进行合并: 较小的段会被合并成较大的段,减少了段数目,提升查询性能。(这个咱们不看编码也能懂)
平衡考虑: TieredMergePolicy 在段的合并中会考虑多种因素,包括段的大小、段的数量等,以达到合并的平衡性。
TiredMergePolicy 控制着 Lucene 的索引在增删改查过程中自然发生的merge以及forcemerge的OneMerge(单个原始合并)生成策略。
接下来,我们详细分析一下 Lucene 8.11.2 版本中的 org.apache.lucene.index.TieredMergePolicy 实现并思考有哪些调优思路。
💡 注:1.这里的分层只是逻辑概念,并不是真的做范围划分,目的就是为了求出索引的允许最大段数,从后文就能看出来了。
2.本文中没有特别说明的话,索引指Lucene的索引,即 Elasticsearch中的分片。
2、重要属性
2.1 DEFAULT_NO_CFS_RATIO 介绍
这个用于判断生成新段的时候,是否使用复合文件, 复合文件(Compound File)是将多个索引文件合并为一个单一的文件组合,以减少文件数量和提高性能。
在 Lucene 中,复合文件主要由两个部分组成:
.cfs: 它包含多种索引文件(比如nvd,fdt,dvm等)的内容。
.cfe: 它则主要记录了每种索引文件在cfs中的offset和length信息,方便快速定位到具体的内容。
DEFAULT_NO_CFS_RATIO 默认为0.1, 如果合并段的大小小于或者等于 DEFAULT_NO_CFS_RATIO * 所有段的总大小,那么就使用复合文件,否则就不使用。
具体实现见:org.apache.lucene.index.MergePolicy#useCompoundFile
2.2 MERGE_TYPE 介绍
其分三种 TYPE, 但是实际上只有 2 种 TYPE:
private enum MERGE_TYPE {NATURAL, FORCE_MERGE, FORCE_MERGE_DELETES}NATURAL
是正常索引维护过程(文档增删改查)中,根据合并策略自动触发的 merge。
FORCE_MERGE_DELETES
只对那些包含了删除文档(占10%,由变量forceMergeDeletesPctAllowed控制 )的段进行合并。
当 ES 调用forcemerge 指定only_expunge_deletes, 则会进行这种类型的merge。
FORCE_MERGE
实际上在 lucene 中没有地方使用到这个枚举值,ES 源码中也没有。
后文会对不同的类型做详细分析。
2.3 其他属性介绍
maxMergeAtOnce
在NATURAL情况下,同时合并的最大段数,默认10
maxMergedSegmentBytes
在NATURAL情况下,最大允许生产的合并后段的大小,默认5G
maxMergeAtOnceExplicit
在forcemerge和forcemergeDeletes情况下,同时合并的最大段数,默认无限。
floorSegmentBytes
段大小小于这个floorSegmentBytes大小,则都认定他们的SegmentSize都是这个大小, 默认2M
segsPerTier
这个越少会带来更多的合并
设置每层需要包含segsPerTier个段才被允许合并, 默认为10
deletesPctAllowed
表示允许索引中的删除文档占总文档数的最大百分比。较低的值会使索引更加节省空间,但可能会增加 CPU 和 I/O 活动。默认值是 33。
接下来,我们从具体的find流程去分析:
org.apache.lucene.index.TieredMergePolicy#findMerges
对应的是正常索引维护过程中,自动触发的merge。
org.apache.lucene.index.TieredMergePolicy#findForcedMerges
对应的是forcemerge
org.apache.lucene.index.TieredMergePolicy#findForcedDeletesMerges
对应的是带了only_expunge_deletes的foremerge
3、正常场景下的 Meger 流程
这个流程实际上是在org.apache.lucene.index.TieredMergePolicy#findMerges 中实现的。
他主要分为以下几个步骤:
初始化
获取正在合并的段列表
通过调用 getSortedBySegmentSize 方法,根据段的大小从大到小对 infos 中的段进行排序,得到排序后的列表 sortedInfos。
统计合并信息和过滤
遍历 sortedInfos 中的段:
如果段正在合并,则将其大小累加到 mergingBytes 中,并从列表中移除,同时更新 totalMaxDoc(累计存活的文档数)。
否则,统计删除文档数和总最大文档数,并更新 minSegmentBytes为当前段大小的最小值。
累计总索引字节数 totIndexBytes (用于后续分层)。
计算删除文档比例
计算所有段的删除文档的比例,超出这比例的段或者索引一定会被合并。
计算索引允许的删除文档数
根据索引内的删除文档比例和设置的 deletesPctAllowed(默认为 33%)计算出允许的删除文档数 allowedDelCount。
移除过大的段,(避免合出的段太大,但是如果删除文档数超出阈值了,就一定要合并这个段
移除的前提是段的大小大于maxMergedSegmentBytes(默认5G)的一半大小,其次需要满足如下两个条件之一:
段的删除文档数小于阈值。
索引的删除文档数小于阈值。
不断分层,计算index中允许的segment数
索引允许的段数为每层的总和,最终和segsPerTier比较去最大值。
看起来floorSegmentBytes和segsPerTier都影响着allowedSegCount ,那么他们到底是什么样的关系呢?
allowedSegCount 最小为segsPerTier
当计算出的allowedSegCount 大于segsPerTier, floorSegmentBytes就发挥作用了,结合后面的doFindMerges的逻辑
floorSegmentBytes 太小,会导致allowedSegCount 很大,这会导致存在大量的小段
floorSegmentBytes 太大,会导致合并的段越大,段越少,但是有maxMergedSegmentBytes控制。
调用doFindMerges
总的来说,就是为了得到可以合并的段列表、每次合并的最大段数、索引允许的段数、允许删除的文档数、是否有超出大的合并(合并的字节总数大于maxMergedSegmentBytes),而这些作为参数进而调用doFindMerges函数。
关键流程图如下图 1所示:

其中“分层”的核心代码如下:
@Overridepublic MergeSpecification findMerges(...) throws IOException {// ... // 计算mergeFactor, 这个描述了执行一次merge,最多能包含多少个段// 从我们提到的两个变量中求一个最小值,默认都是10final int mergeFactor = (int) Math.min(maxMergeAtOnce, segsPerTier);// 注意这里的分层只是逻辑概念,并没有真的对各个段的大小做范围分层,只是为了求出allowedSegCount // 计算index中允许的segment数// Compute max allowed segments in the index// levelSize 每一层中允许最小段的大小, TieredMergePolicy合并相似的段,从最小段开始找long levelSize = Math.max(minSegmentBytes, floorSegmentBytes);// 待合并的大小long bytesLeft = totIndexBytes;double allowedSegCount = 0;// 不断分层计算while (true) {// 计算当前层的允许的段数,剩下的字节除以每一层中允许最小段的大小final double segCountLevel = bytesLeft / (double) levelSize;// 如果当前允许的段数小于等于segsPerTier, 或者当前层级最小段都等于设置的最大段大小// 直接退出循环,因为这个时候不需要再向下合并的了if (segCountLevel < segsPerTier || levelSize == maxMergedSegmentBytes) {allowedSegCount += Math.ceil(segCountLevel);break;}allowedSegCount += segsPerTier;bytesLeft -= segsPerTier * levelSize;// 确保每层合并的段大小不会超过最大合并段大小levelSize = Math.min(maxMergedSegmentBytes, levelSize * mergeFactor);}// 取 allowedSegCount和segsPerTier 中的较大值,确保至少可以有segsPerTier个段, 因为可能上面的逻辑只分了一个层,而且这个层得到的段数还小于segsPerTier// 单测方法org.apache.lucene.index.TestTieredMergePolicy#testManyMaxSizeSegments 第一个findMerges 就是这种情况allowedSegCount = Math.max(allowedSegCount, segsPerTier);return doFindMerges(sortedInfos, maxMergedSegmentBytes, mergeFactor, (int) allowedSegCount, allowedDelCount, MERGE_TYPE.NATURAL,mergeContext, mergingBytes >= maxMergedSegmentBytes);}3.1 寻找最佳合并段
接下来再看 doFindMerges 的逻辑, findMerges 和findForcedDeletesMerges 都调用这个方法,我们详细解释一下各个变量的含义:
sortedEligibleInfos
满足合并条件的列表,从大到小排序
maxMergedSegmentBytes
同上文分析,允许的合并后段的最大大小
mergeFactor
一次合并中允许合并的段的最大数量。
allowedSegCount
索引允许应该有的段数
allowedDelCount
索引中允许有的删除的文档数
mergeType
如上文
mergeContext
合并上下文,包含了关于合并操作的相关信息
maxMergeIsRunning
正在merge的字节大小是否有超出maxMergedSegmentBytes
这个函数不断循环,每次选择一组最佳的合并段,构建合并规格,记录已选中的段,直到不能找到更多合并或不满足特定条件为止。这个过程中,函数将合并候选段进行组合,计算合并分数,并根据一定条件选择最佳合并。以下是关键的三个循环:
while true 外层循环
这个循环的目的是在每次迭代中,从剩余的段中选择一个最佳的合并组合。它遍历了 sortedEligible 列表,移除已合并和已选中的段
如果没有剩余的可合并段,直接返回 spec,意味着不再有合并操作
如果是自然合并(MERGE_TYPE.NATURAL)且剩余段少于等于允许的段数和删除文档数,也直接返回 spec
接下来,进入第一层for循环,这个循环会遍历起始段,从每个起始段开始,尝试逐步添加后续段,构建出合并候选组合的最佳组合
当第一次for循环结束,判断是否将第一层循环得到的最佳合并候选添加到MergeSpecification:
如果是FORCE_MERGE_DELETES, 则新增到spec中,它允许大合并进行并行
如果spec中没有大合并,则新增到spec中
如果这次不是大合并,则新增到spec中
第一层for 循环
这个循环用于确定合并的起始段,以及构建最佳的合并候选。起始段从 sortedEligible 列表的每个位置开始。
进入第二层for循环,对于每个合并候选,会计算合并分数,然后比较该分数与之前找到的最佳分数。如果当前合并候选的分数更低,且满足一定条件,会更新 best、bestScore 等变量
第二层for循环
这个循环位于第一层循环中,用于构建合并候选组合,从第一层for循环给的起始段开始,逐步添加后续段,直到达到合并大小限制(maxMergedSegmentBytes)或(mergeFactor)的数量
如果添加下一个段会导致合并候选超过合并大小限制,会标记 hitTooLarge为 true,然后继续尝试下一个段
循环结束后,构建出一个合并候选组合
其关键流程如下图2所示:
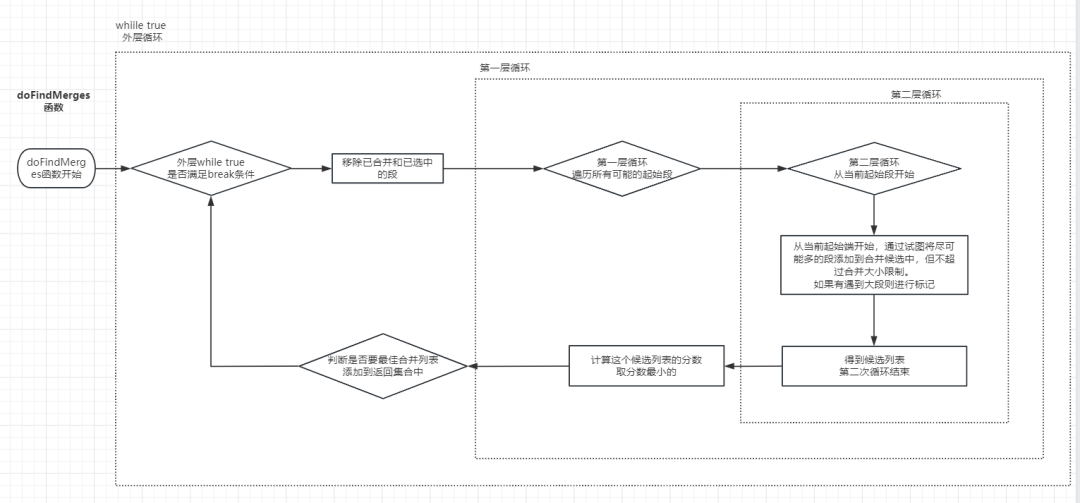
核心代码分析见:org.apache.lucene.index.TieredMergePolicy#doFindMerges
3.2 合并段算分逻辑
doFindMerges 中有一个很重要的合并段算分逻辑,这是为了找到最优的 OneMerge 以尽量减少后续的重复合并。
protected MergeScore score(...) throws IOException {final double skew;if (hitTooLarge) {final int mergeFactor = (int) Math.min(maxMergeAtOnce, segsPerTier);skew = 1.0/mergeFactor;} else {skew = ((double) floorSize(segmentsSizes.get(candidate.get(0)).sizeInBytes)) / totAfterMergeBytesFloored;}double mergeScore = skew;mergeScore *= Math.pow(totAfterMergeBytes, 0.05);final double nonDelRatio = ((double) totAfterMergeBytes)/totBeforeMergeBytes;mergeScore *= Math.pow(nonDelRatio, 2);final double finalMergeScore = mergeScore;总的计算公式为:
skew :粗略地测量合并的“倾斜”,即合并的“平衡”程度(段的大小是否大致相同),其范围可以是1.0/numSegsBeingMerged(好)到 1.0(差)。严重不平衡的合并(倾斜接近 1.0)是不好的;这意味着随着时间的推移会有 O(N^2) 合并成本。
当没有大段 false == hitTooLarge
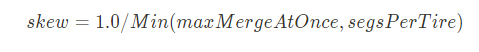
-
maxMergeAtOnce, segsPerTire都已经在上文介绍过,默认情况下,都是10, 计算之后,默认0.1已经足够小了。
这种情况下,skew的大小并不重要,随着时间推移,他不会造成 O(N^2) 的合并成本,因为他不会存在后续的合并,因为他已经超出maxMergedSegmentBytes啦。
当有大段 true == hitTooLarge
skew = Max(floorSegmentBytes, 候选列表第一个segment的Size) / totAfterMergeBytesFloored
详细说明一下,为什么不平衡的合并,会随着时间的推移,有 O(N^2) 合并的成本。
首先明确一点,我们merge之后,尽量要保证不要再merge, 因为再次merge就会导致重新进行读写。
举一个简单例子,假设有这样一组段大小【4,3,2,1】,maxMergedSegmentBytes为6, mergeFactor =2. 现在有两种方案【4,3】【2,1】 以及【3,2】【4,1】
肯定是方案一好,因为4,3合并之后就是7,后续不会再参加合并,但是第二种3,2合并之后是5,这个5依旧会再次参加合并
nonDelRatio:强烈支持回收删除的合并,因为这能快速节省空间, 其值越小,越表示这个候选列表中,包含的可删除的文档越多。
totAfterMergeBytes:指合并之后的大小,温和地支持较小的合并而不是较大的合并。我们不想让这个指数太大,所以设置成0.05,否则我们最终可能会对小段进行糟糕的合并。
4、ForceMerge - only_expunge_deletes源码逻辑
这个实现实际上在:org.apache.lucene.index.TieredMergePolicy#findForcedDeletesMerges,当执行forcemerge并带上only_expunge_deletes选项时,就会调用这个函数。
关键流程为:
先执行检查确定是否有需要执行的合并操作。
它检查每个段,计算出被标记为删除的文档占总文档数的百分比。
如果某个段的删除文档百分比超过了允许的强制合并删除百分比,并且该段没有在合并中,那么就说明有需要执行的合并操作。
否则,就直接返回null表示没有需要合并的段。
从大到小遍历索引段的每个段,计算其删除文档占总文档数的百分比。如果该段正在合并中或者其删除文档百分比小于等于允许的强制合并删除百分比,那么就将该段从列表中移除。
换句话只需要超出删除文档超出forceMergeDeletesPctAllowed比例(默认10%)的段。
调用和findMerges复用了同一个方法doFindMerges,区别在于传递的参数:
mergeFactor 使用的是maxMergeAtOnceExplicit, 默认是无限制
allowedSegCount 使用的是Integer.MAX_VALUE
allowedDelCount 为0
关键流程图3为:

注意到, findForcedDeletesMerges 传递了maxMergedSegmentBytes,也就是说它会遵守maxMergedSegmentBytes的大小限制,即大于这个大小的段,不会被合并,哪怕这个段的删除文档数超出限制了,也不会合并,因为在doFindMerges中,不会再去判断删除文档的限制了,只会判断maxMergedSegmentBytes。
5、ForceMerge 源码逻辑
这个流程实际上在:org.apache.lucene.index.TieredMergePolicy#findForcedMerges,当forceMerge没有带上only_expunge_deletes选项时,就会调用这个。
为啥他不复用doFindMerges,而findForcedDeleteesMerges复用?有以下几个原因:
因为forcemerges可以指定maxSegmentCount,而doFindMerges是不可以指定的。
findForcedMerges函数选候选节点的时候,不需要算分,因为findForcedMerges不会在意的重复merge。
因为forcemerge目标是合并成maxSegmentCount 个,和findForcedDeleteesMerges是不一样的。
其关键流程如下:
获取索引的段列表,移除正在合并的段。
计算maxMergeBytes, maxSegmentCount=1,则无限,否则计算理想大小。
遍历索引的段的列表,移除满足以下条件之一的段。
当maxSegmentCount 等于MAX_VALUE 并且 这个段没有删除的文档。
当maxSegmentCount 不等于MAX_VALUE并且这个段小于上一步计算的maxMergeBytes。
当已经有正在合并的forceMerge,并且并行进行的merge段个数超过maxMergeAtOnceExplicit 则直接退出,否则继续。
判断是否是特殊情况:直接将待合并段列表形成一个OneMerge。
如果不是合成一个段,就从小到大去遍历选出候选merge。
选出的候选不能大于maxMergeBytes。
选出的候选总数不能大于maxSegmentCount。
其关键流程图如下:

注意到, 当maxSegmentCount = 1 的时候, 段的最大字节数为无限, 如果不是1的时候,并不能保证会生成的段≤maxSegmentCount,这是一个尽力而为的操作。
6、总结
经过对以上的各个流程的分析,我们反思一下在索引正常的增删改查以及调用forcemerge时需要注意的细节和可能调优的思路。
6.1 mergePolicy 层面
Elasticsearch默认使用 TieredMergePolicy, 我们看下有哪些选项(org.elasticsearch.index.MergePolicyConfig):
| Elasticsearch配置(都是索引级别动态) | ES 默认值 | 对应Lucene配置(变量) | Lucene 默认值 | 最佳实践&说明 |
|---|---|---|---|---|
| index.compound_format | 0.1 | DEFAULT_NO_CFS_RATIO | 0.1 | |
| index.merge.policy.expunge_deletes_allowed | 10 | forceMergeDeletesPctAllowed | 10 | force_merge情况下,当携带only_expunge_deletes=true的forcemerge调用,文档删除的比例大于这个的并且小于max_merged_segment的段会参与合并 |
| index.merge.policy.floor_segment | 2M | floorSegmentBytes | 2M | 自然合并中,期望的最小段的大小。 1.floorSegmentBytes 太小,会导致分片允许存在的段很多,这可能会导致存在大量的小段没有合并; 2.floorSegmentBytes 太大,会导致分片允许存的段少,这会有效降低段的个数,但是则也会导致合并越频繁,不过大小方面有index.merge.policy.max_merged_segment控制。 如果发现集群中很多小段没有合并,可以尝试提高这个参数 |
| index.merge.policy.max_merge_at_once | 10 | maxMergeAtOnce | 10 | 自然合并中,一个Lucene索引一次merge最多包含多少段 |
| index.merge.policy.max_merge_at_once_explicit | 30 | maxMergeAtOnceExplicit | 无限 Integer.MAX_VALUE; | forc_merge情况下,一个Lucene索引一次merge最多包含多少段。 |
| index.merge.policy.max_merged_segment | 5G | maxMergedSegmentBytes | 5G | 自然合并中, 一个段最大的大小,这个是一个预估值,并不一定保证合并之后的大小就小于max_merged_segment, 大于这个大小的段后续不会参与合并,除非删除的文档超出deletes_pct_allowed阈值。 值越小,会更有很多分段,但是能减少merge次数。 |
| index.merge.policy.segments_per_tier | 10 | segsPerTier | 10 | 自然合并中,一个分片允许的最少分片数,少了会带来更多的合并,但是多了,可能会导致一个分片最多有segments_per_tier-1个小段。 如果发现集群中很多小段没有合并,可以尝试减少这个参数;相反,增加大可以减少merge次数,会有更多分段。 |
| index.merge.policy.deletes_pct_allowed | 33 | deletesPctAllowed | 33 | 自然合并中, 如果一个段或者一个Lucene索引的删除的文档比例大于这个值,则一定会合,无视其他限制。如果设置得太小,会导致频繁合并。 |
6.2 force merge 层面
有2个地方可以使用:
直接调用API : https://www.elastic.co/guide/en/elasticsearch/reference/7.10/indices-forcemerge.html
用在索引生命周期管理上:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/ilm-forcemerge.html
关键参数为:
max_num_segments
必须指定, 当maxSegmentCount不为1的时候,并不能一定保证最终的段个数≤maxSegmentCount。
only_expunge_deletes
默认false, 如果为true,则只对那些包含了删除文档大于(10%,由index.merge.policy.expunge_deletes_allowed 控制 )并且小于max_merged_segment大小的段进行合并。
如果指定了only_expunge_deletes, 那么最终合并的段不一定是max_num_segments个,是尽力而为的操作。
注:
(1)forcemerge的线程池大小为:max(1, (# of allocated processors) / 8), 其队列是无限的,需要注意不能一次性提交太多索引的frocemerge。
(2)官方推荐对只读索引进行force merge ,如果我force merge之后又有新的写入,会怎么样?
随着时间的推移(走的是NATURAL类型的merge)
那么后续最多会存在segments_per_tier-1个小段无法合并。
因为超出了max_merged_segment 的段后续不会再参与合并, 只有当删除的文档数超出index.merge.policy.deletes_pct_allowed 才会被合并,会造成磁盘回收缓慢,甚至浪费(最多每个段浪费大概三分之一的max_merged_segment大小)。
(3)本文基于 Elasticsearch 7.10.2,Lucene 8.11.2 源码进行剖析!
作者简介
He Chengbo,互联网安全独角兽公司资深工程师,死磕 Elasticsearch 星球资深活跃技术专家。
在此,感谢铭毅老师提供这个宝贵的平台发表文章,也感谢您给予的指导和鼓励!
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
干货 | Elasticsearch Reindex性能提升10倍+实战

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

chatGPT也搞不定的问题,欢迎抛给我们!