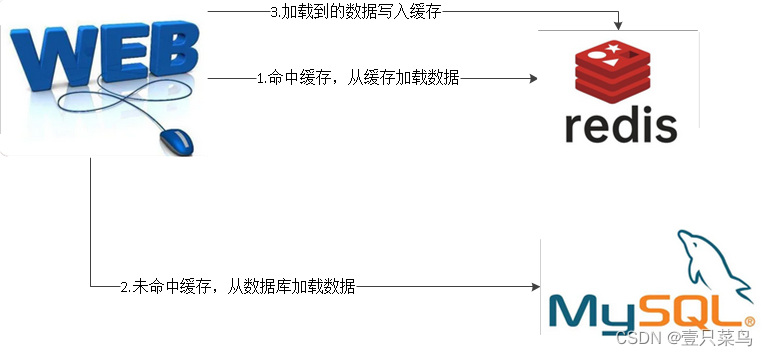
分片架构解决的问题
通过堆机器,提升读写性能,与存储性能
分片架构设计要点
分片规则
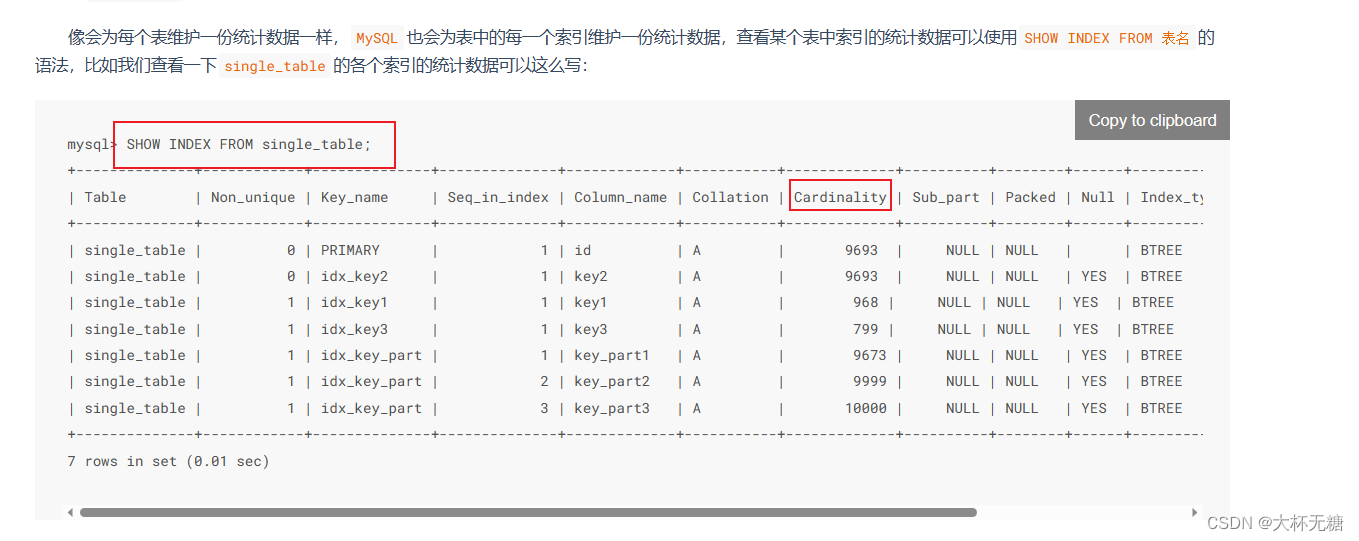
选择Cardinality大的作为分片键,尽可能保证数据分布均匀
常见分片键: 基于主键(业务型数据),基于时间(流水型数据)
常见分片策略:
| 分片策略 | 实现举例 | 数据分布 | 以后扩展 |
| 基于Hash | hash(分片键)%分片数 一致性hash算法 | 数据分布均匀 | 不易扩容,扩容需要数据迁移 |
| 范围分片 | 例如按年分,按月,按日 | 数据分表可能不均匀 | 易扩展,扩展不需要数据迁移 |
路由规则
客户端如何找到数据所在分片
- 静态路由: 配置文件。特点: 简单,不能扩展再平衡,例如:Mysql分表
- 动态路由:实现复制,支持动态扩展,再平衡
| 动态路由方式 | 基本流程 | 特点 | 举例 |
| 配置中心 | 配置中心记录分片信息,客户端先访问配置中心, 获取分片信息之后进行读写操作 | 支持大规模集群,配置中心需要独立部署,需要高可用 | MongoDB的Sharding模式 |
| 路由转发 | 所有分片都保存路由信息,客户端请求任意分片, 获取分片信息之后进行读写操作 | 架构简单,一般利用gossip协议,不支持大规模集群 | Redis Cluster (官方推荐1000,实际建议100) |
高可用
| 备份方式 | 特点 | 举例 |
| 独立备份 | 架构简单,硬件成本高,分片级别的复制 | Mysql ,Redis等 |
| 相互备份 | 架构复杂,硬件成本低,数据块级别的复制 | ElasticSearch 等 |
redis cluster 分析
特点
理论支持1000台,实际建议100台以内。 高性能,线性可扩展,无代理,异步复制。
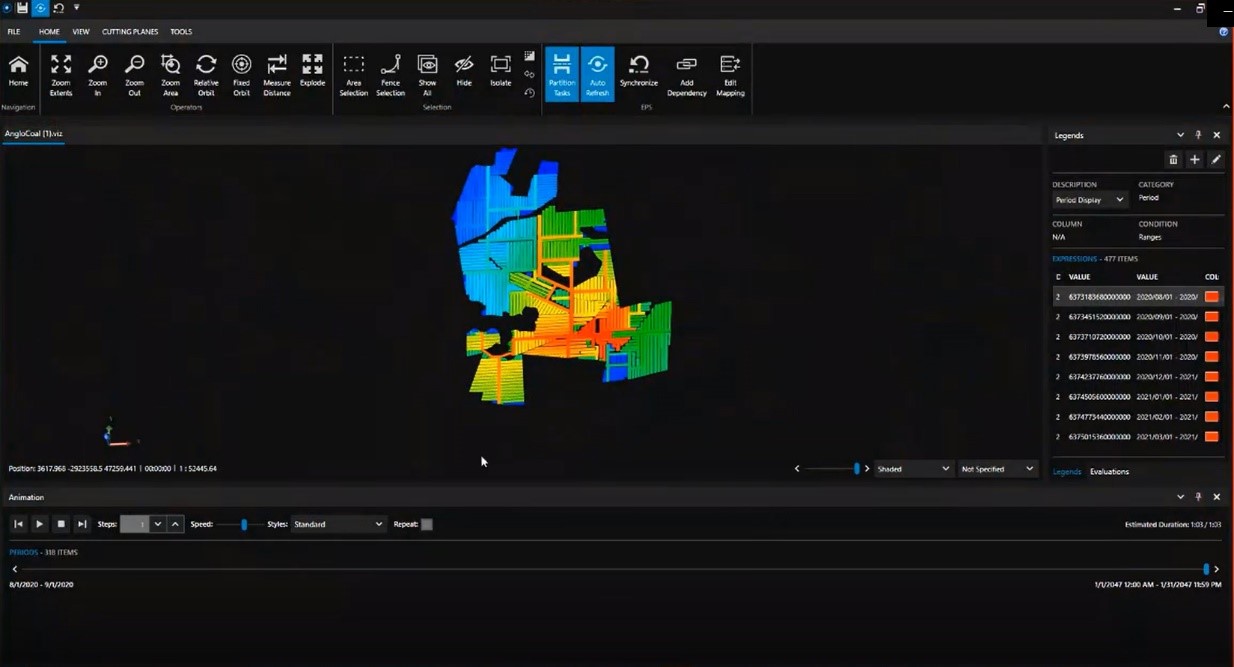
架构图- 来自阿里云溪社区

分片规则
分片键
redis的key
分片方式
类似一致性Hash, 通过CRC16算法计算出来的哈希值,对16384(2^14)取模,取模之后得到的值就是对应的槽位,然后每个Redis节点都会负责处理一部分的槽位。
扩展1 一般hash算法缺点
hash(键值)%分片数量,如果有分片挂掉,分片数量会下降,整个集群会失效。
扩展2 一致性hash算法
CRC16算法计算出来的哈希值,对2^32取模
实例也分布在圆环(0-2^32)上,我们在圆环上按照顺时针的顺序找到第一个实例
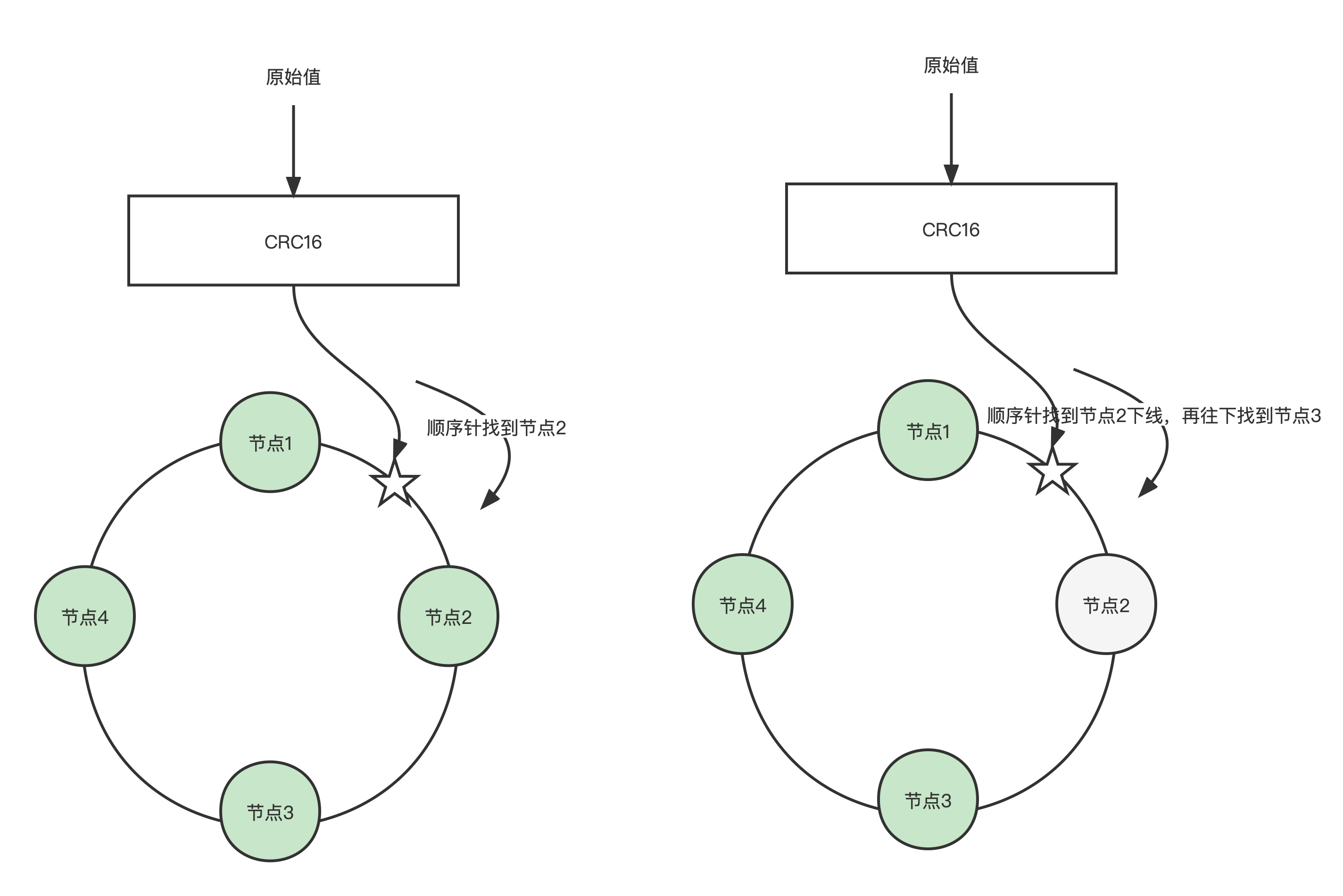
实例可能分布不均匀,采用虚拟节点机制解决

路由规则
路由转发模式,一般利用gossip协议,所有分片都保存路由信息,客户端请求任意分片
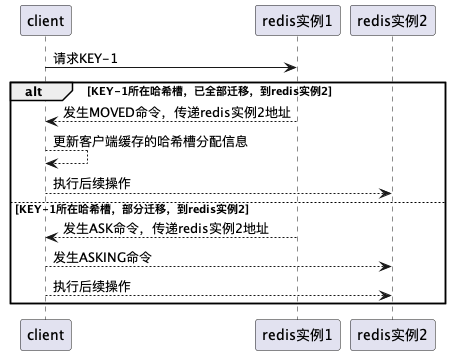
集群为了分布均匀,再平衡,或,添加,删除master实例,存在重定向的情况。
重定向
| 场景 | 命令 | 说明 |
| 全部迁移完成的情况下 | MOVED命令 | 1.MOVED把客户端所请求数据的最新实例地址返返回客户端 2.更新客户端缓存的哈希槽分配信息 |
| 哈希槽数据还在迁移中 | ASK | 1.ASK 命令把客户端所请求数据的最新实例地址返回给客户端 2.客户端需要给目标实例 发送 ASKING 命令,然后再发送操作命令 3.不更新客户端缓存的哈希槽分配信息 |
备份方式
独立备份
故障转移:
某一个节点认为A宕机了,那么此时是主观宕机
集群内超过半数的节点认为A挂了, 那么此时A就会被标记为客观宕机
从A节点的slave节点中选举出一个,将其切换成新的master对外提供服务