Redis进阶
- 1. Redis为什么这么快?
- 2. 缓存穿透
- 2.1 概念
- 2.2 解决方案
- 3. 缓存击穿
- 3.1 概念
- 3.2 解决方案
- 4. 缓存雪崩
- 4.1 概念
- 4.2 解决方案
- 5. redis集群
- 5.1 主从同步
- 5.2 哨兵模式(集群模式)
- 1. 哨兵主要有两个重要作用
- 2. 哨兵模式应用
- 3. sentinel.conf配置项
- 5.3 切片模式(集群模式)
- 5.4 集群部署
- 6. redis的持久化
- 6.1 RDB
- 6.2 AOF
- 6.3 AOF重写
- 6.4 如何选择RDB和AOF
- 6.5 Redis的两种持久化方式的缺点
- 7. Redis的常用应用场景
- 7.1 缓存
- 7.2 排行榜
- 7.3 计数器应用
- 7.4 共享Session
- 7.5 分布式锁
- 7.6 社交网络
- 7.7 消息队列
- 7.8 位操作
- 8. Redis + MySQL

与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
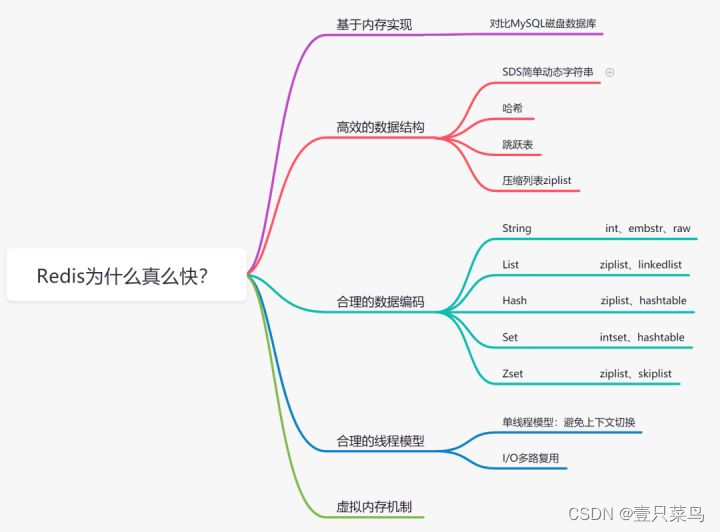
1. Redis为什么这么快?
-
基于内存存储实现
我们都知道内存读写是比在磁盘快很多的,Redis基于内存存储实现的数据库,相对于数据存在磁盘的MySQL数据库,省去磁盘I/O的消耗。 -
高效的数据结构
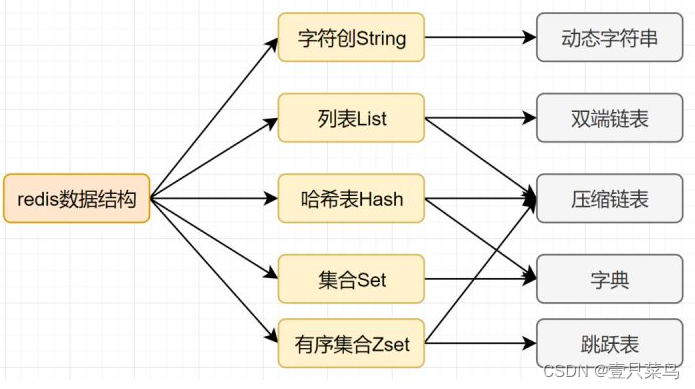
我们知道,Mysql索引为了提高效率,选择了B+树的数据结构。其实合理的数据结构,就是可以让你的应用/程序更快。看下Redis的数据结构&内部编码图
-
合理的数据编码
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。什么时候,使用什么样数据结构,使用什么样编码,是redis设计者总结优化的结果。String:如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。
List:如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码
Hash:哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。
Set:如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。
Zset:当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码 -
合理的线程模型
I/O 多路复用多路I/O复用技术可以让单个线程高效的处理多个连接请求,而Redis使用用epoll作为I/O多路复用技术的实现。并且,Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
什么是I/O多路复用?
I/O :网络 I/O
多路 :多个网络连接
复用:复用同一个线程。
IO多路复用其实就是一种同步IO模型,它实现了一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;而没有文件句柄就绪时,就会阻塞应用程序,交出cpu。单线程模型
- Redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正因为是单线程,如果某个命令执行过长(如hgetall命令),会造成阻塞。Redis是面向快速执行场景的数据库。所以要慎用如smembers和lrange、hgetall等命令。
- Redis 6.0 引入了多线程提速,它的执行命令操作内存的仍然是个单线程。
-
虚拟内存机制
Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。Redis的虚拟内存机制是啥呢?
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
2. 缓存穿透
2.1 概念
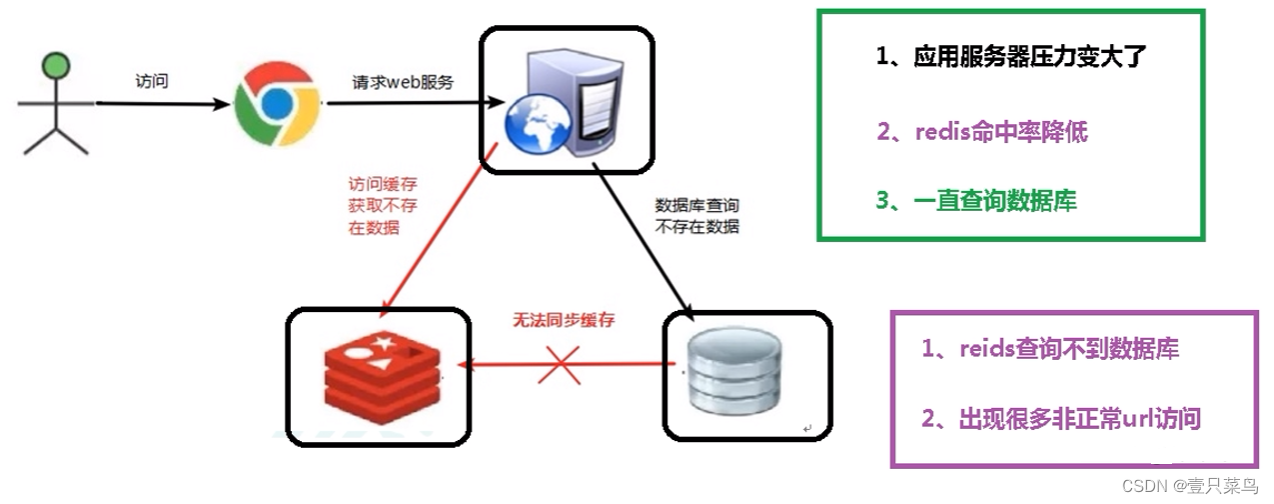
key 对应的数据在redis中并不存在,每次针对此 key的请求从缓存获取不到,请求转发到数据库,访问量大了可能压垮数据库。比如用一个不存在的用户 id 获取用户信息,redis缓存和数据库中都没有,若黑客利用此漏洞进行攻击可能压垮数据库(黑客访问肯定不存在的数据,造成服务器压力大)
缓存穿透现象:
- 应用服务器压力变大
- redis命中率变低,从而会不断查询数据库
2.2 解决方案
一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义
- 对空值缓存: 如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,这样可以缓解数据库的访问压力,然后设置空结果的过期时间会很短,最长不超过五分钟。(只能作为简单的应急方案)
- 设置可访问的名单(白名单): 使用 bitmaps 类型定义一个可以访问的名单,名单 id 作为 bitmaps 的偏移量,每次访问和 bitmap 里面的 id 进行比较,如果访问 id 不在 bitmaps 里面,进行拦截,不允许访问。
- 布隆过滤器: 将所有可能存在的数据哈希到一个足够大的 bitmaps 中,一个一定不存在的数据会被这个bitmaps 拦截掉,从而避免了对底层存储系统的查询压力
- 进行实时监控: 当发现 Redis 的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
3. 缓存击穿
3.1 概念
key 对应的数据存在,但在 redis 缓存中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大量并发的请求可能会瞬间把后端 DB 压垮(redis某个热门数据过期,大量的合理数据请求到达数据库)
缓存击穿现象:
- 数据库的访问压力瞬间激增
- redis正常运行
- redis没有出现大量的过期现象(过期后无法访问,若未命中,则需要访问数据库)
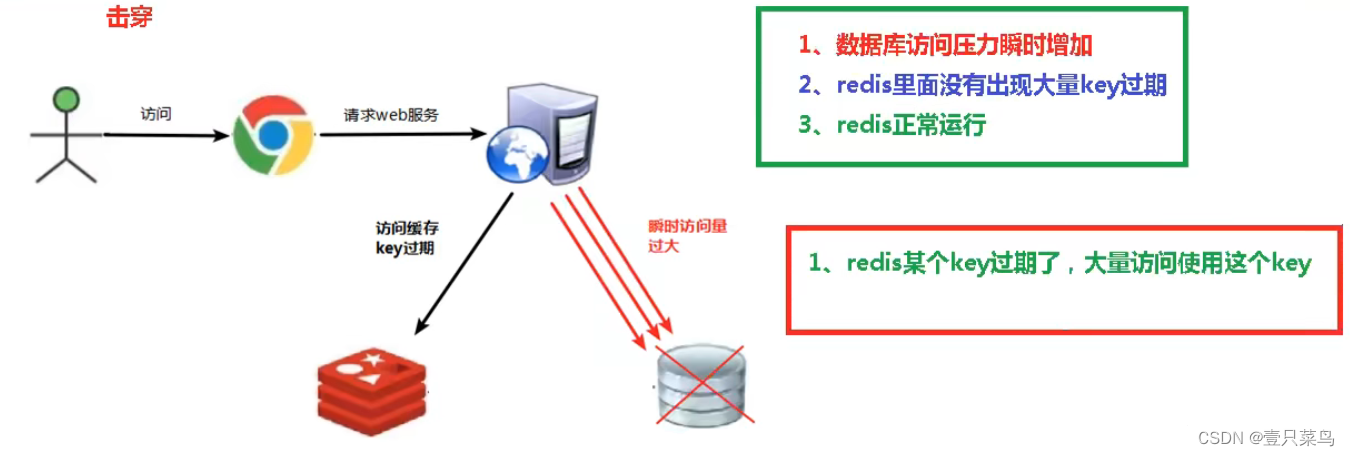
产生原因: redis中的某个热门的key过期了,而此时客户端对这个key的访问量激增,redis无法命中,这些访问就会转发到数据库,造成数据库瞬间压力过大
3.2 解决方案
key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
- 预先设置热门数据: 在 redis 高峰访问之前,把一些热门数据提前存入到redis 缓存里面,加大这些热门数据 key 的时长
- 实时调整: 现场监控哪些数据热门,实时调整 key 的过期时长
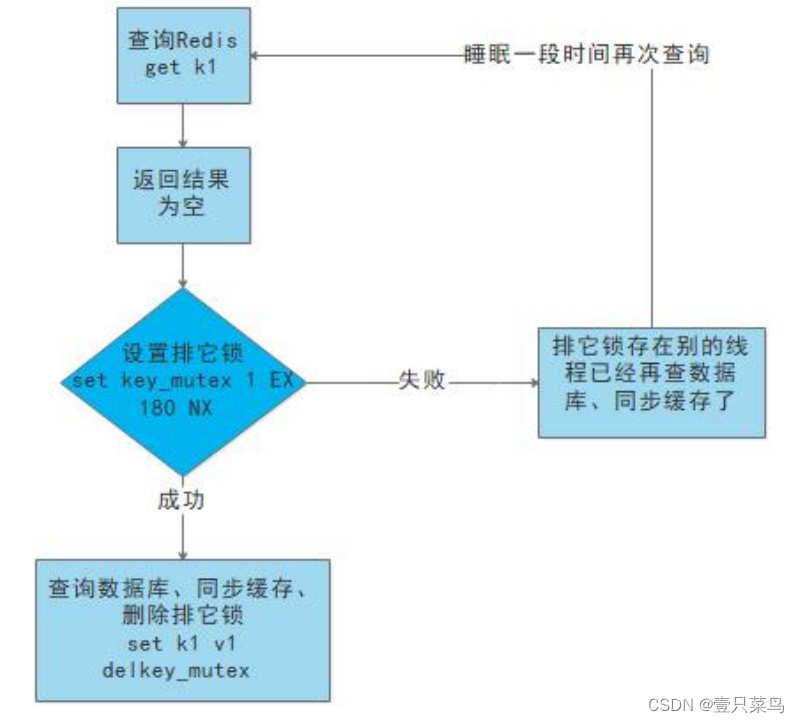
- 使用锁:
- (1) 就是在缓存失效的时候(判断拿出来的值为空),不是立即去 load DB;
- (2) 先使用缓存工具的某些带成功操作返回值的操作(比如 Redis 的 SETNX)去 set 一个 mutex key;
- (3) 当操作返回成功时,再进行 load db 的操作,并回设缓存,最后删除 mutex key;
- (4) 当操作返回失败时,证明有线程在 load db,当前线程睡眠一段时间再重试整个 get 缓存的方法
4. 缓存雪崩
4.1 概念
key 对应的数据存在,但在 redis 中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大量并发的请求可能会瞬间把后端 DB 压垮
缓存雪崩针对很多 key 失效导致redis无法命中,数据库压力激增;缓存击穿则是某一个热门 key 失效导致redis无法命中,数据库压力激增
缓存雪崩现象: 数据库压力变大,服务器崩溃
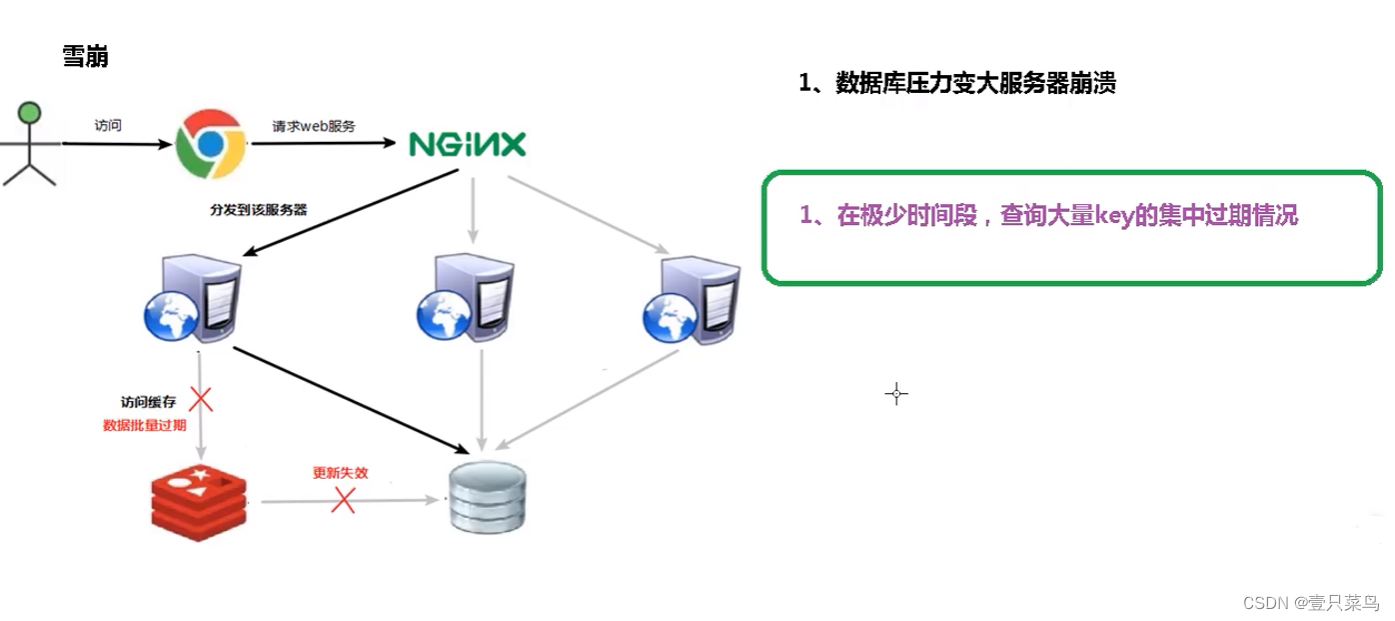
雪崩出现原因: 极小时间段内,redis中大量的key过期,导致命中率极低,数据库压力激增
4.2 解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
- 构建多级缓存架构:
nginx 缓存 + redis 缓存 +其他缓存(ehcache 等),程序设计较为复杂 - 使用锁或队列: 用加锁或者队列的方式来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。效率低,不适用高并发情况
- 设置过期标志更新缓存: 记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际 key 的缓存
- 将缓存失效时间分散开: 比如我们可以在原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件
5. redis集群
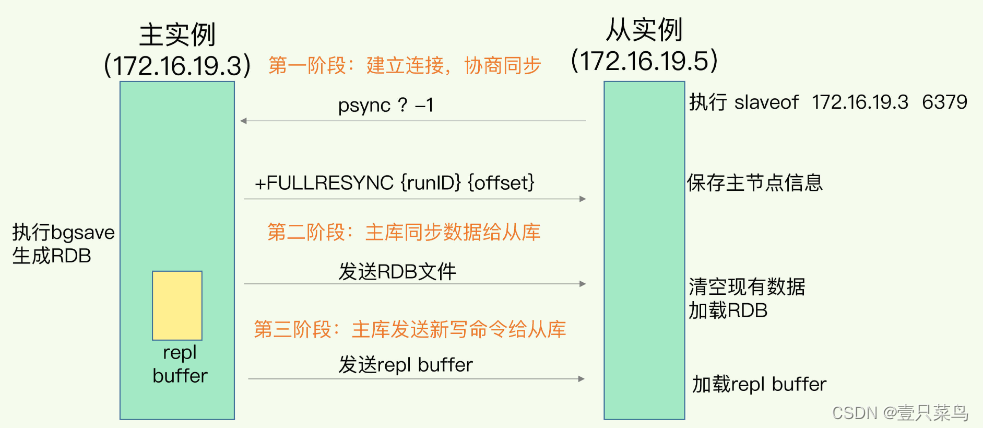
5.1 主从同步
如果涉及到多个从结点,那么就需要主->从->从,这种集群结构。
- 主从同步会在主建一个replication buffer。主从间全量的同步命令指令都是通过这个buffer走。
- replication buffer是每个从结点都会有一个,独享。
- 下面的repl-backlog-buffer是只有一个,用于增量同步。
- 当主从断开后,此时主会将后续的命令写到这个repl-backlog-buffer。repl-backlog-buffer是一个循环队列,分别有主的写指针,从的读指针。当从再次连接上来时会带上master实例id+当前relica-back-buffer的读指针,主会判断当前数据是否被覆盖(可以用从读指针>主写指针 或 主写和从读指针相等但不是指向空)。
- 主从同步的relica buffer如果超过out-buffer-size这个值,redis主会将这个从的连接断掉,然后后面从再启来也会再次内存飙升再次断开。
5.2 哨兵模式(集群模式)
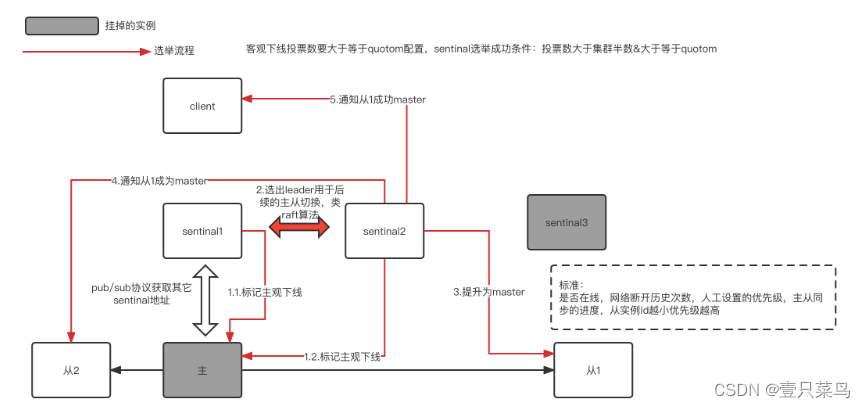
1. 哨兵主要有两个重要作用
- 第一:哨兵节点会以每秒一次的频率对每个 Redis 节点发送PING命令,并通过 Redis 节点的回复来判断其运行状态。
- 第二:当哨兵监测到主服务器发生故障时,会自动在从节点中选择一台将机器,并其提升为主服务器,然后使用 PubSub 发布订阅模式,通知其他的从节点,修改配置文件,跟随新的主服务器。
在实际生产情况中,Redis Sentinel 是集群的高可用的保障,为避免 Sentinel 发生意外,它一般是由 3~5 个节点组成,这样就算挂了个别节点,该集群仍然可以正常运转。其结构图如下所示:
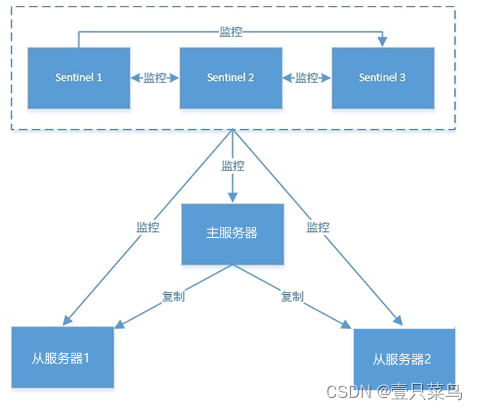
上图所示,多个哨兵之间也存在互相监控,这就形成了多哨兵模式,现在对该模式的工作过程进行讲解,介绍如下:
Sentinel 负责监控主从节点的“健康”状态。当主节点挂掉时,自动选择一个最优的从节点切换为主节点。客户端来连接 Redis 集群时,会首先连接 Sentinel,通过 Sentinel 来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 Sentinel 要地址,Sentinel 会将最新的主节点地址告诉客户端。因此应用程序无需重启即可自动完成主从节点切换。
2. 哨兵模式应用
Redis Sentinel 哨兵模式适合于在 Linux 系统中使用,以 Ubuntu 实现为例。
-
安装sentinel
Sentinel 需要作为插件单独安装,安装方式如下:sudo apt install redis-sentinel -
搭建主从模式
接下来,在本地环境使用主从模式搭建一个拥有三台服务器的 Redis 集群,命令如下所示:
启动6379的redis服务器作为master主机:sudo /etc/init.d/redis-server start启动6380的redis服务器,设置为6379的slave:
redis-server --port 6380 $ redis-cli -p 6380 127.0.0.1:6380> slaveof 127.0.0.1 6379 OK启动6381的redis服务器,设置为6379的salve
redis-server --port 6381 $ redis-cli -p 6381 127.0.0.1:6381> slaveof 127.0.0.1 6379 -
配置sentinel哨兵
首先新建 sentinel.conf 文件,并对其进行配置,如下所示:port 26379 Sentinel monitor biancheng 127.0.0.1 6379 1配置文件说明如下:
port 26379 #sentinel监听端口,默认是26379,可以更改 sentinel monitor <master-name> <ip> <redis-port> <quorum>第二个配置项表示:让 sentinel 去监控一个地址为 ip:port 的主服务器,这里的 master-name 可以自定义; 是一个数字,表示当有多少个 sentinel 认为主服务器宕机时,它才算真正的宕机掉,通常数量为半数或半数以上才会认为主机已经宕机, 需要根据 sentinel 的数量设置。
-
启动sentienl哨兵
方式一:redis-sentinel sentinel.conf方式二:
redis-server sentinel.conf --sentinel -
停止主服务器服务
下面模拟主服务意外宕机的情况,首先直接将主服务器的 Redis 服务终止,然后查看从服务器是否被提升为了主服务器。执行以下命令:#终止master的redis服务 sudo /etc/init.d/redis-server stop执行完上述命令,您会发现 6381 称为了新的 master,而其余节点变成了它的从机,执行命令验证:
127.0.0.1:6381> set webname www.biancheng.net OK哨兵的配置文件 sentinel.conf 也发生了变化:
#port 26379 #sentinel myid 4c626b6ff25dca5e757afdae2bd26a881a61a2b2 # Generated by CONFIG REWRITE dir "/home/biancheng" maxclients 4064 sentinel myid 4c626b6ff25dca5e757afdae2bd26a881a61a2b2 sentinel monitor biancheng 127.0.0.1 6379 1 sentinel config-epoch biancheng 2 sentinel leader-epoch biancheng 2 sentinel known-slave biancheng 127.0.0.1 6379 sentinel known-slave biancheng 127.0.0.1 6380 sentinel known-slave biancheng 127.0.0.1 6381 port 26379 sentinel current-epoch 2如果您想开启多个哨兵,只需配置要多个 sentinel.conf 文件即可,一个配置文件开启一个。
3. sentinel.conf配置项
下面对 Sentinel 配置文件的其他配置项做简单说明:
| 配置项 | 参数类型 | 说明 |
|---|---|---|
| dir | 文件目录 | 哨兵进程服务的文件存放目录,默认为 /tmp。 |
| port | 端口号 | 启动哨兵的进程端口号,默认为 26379。 |
| sentinel down-after-milliseconds | <服务名称><毫秒数(整数)> | 在指定的毫秒数内,若主节点没有应答哨兵的 PING 命令,此时哨兵认为服务器主观下线,默认时间为 30 秒。 |
| sentinel parallel-syncs | <服务名称><服务器数(整数)> | 指定可以有多少个 Redis 服务同步新的主机,一般而言,这个数字越小同步时间越长,而越大,则对网络资源要求就越高。 |
| sentinel failover-timeout | <服务名称><毫秒数(整数)> | 指定故障转移允许的毫秒数,若超过这个时间,就认为故障转移执行失败,默认为 3 分钟。 |
| sentinel notification-script | <服务名称><脚本路径> | 脚本通知,配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。 |
| sentinel auth-pass | <服务器名称><密码> | 若主服务器设置了密码,则哨兵必须也配置密码,否则哨兵无法对主从服务器进行监控。该密码与主服务器密码相同。 |
5.3 切片模式(集群模式)
切片模式是将原本的数据水平切片分配到多个实例上,3.0之前有基于proxy代理的,如twemProxy。基于代理proxy问题就是性能,还有twemProxy本身不支持在线扩容。
redis的cluster集群基本原理是redis服务端完成切片的关系,然后推送给客户端。客户端后续存取key时在客户端本地计算这个关系。
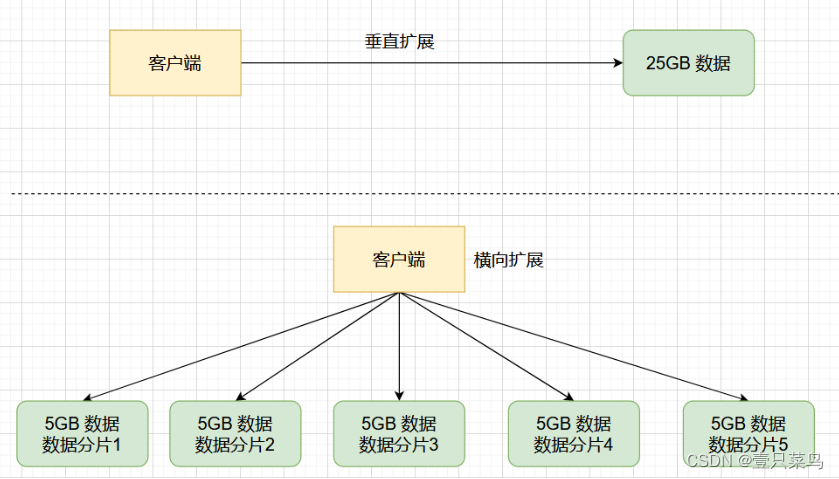
数据扩展模式
如果Redis要缓存的总数据量不是很大,比如5GB数据,一般使用 主从模型 + 哨兵集群保证高可用 就可以满足。但如果Redis要缓存的总数据量比较大,或者未来可能会增大,比如20GB、50GB数据,那一个主库就无法满足了,这时一般有两种模式来扩展:纵向扩展和横向扩展。
-
纵向扩展(垂直扩展)
纵向扩展就是升级单个Redis实例的配置,增加服务器内存容量、磁盘容量、使用更高配置的CPU。比如之前使用的 4C 8GB 50GB ,升级到 8C 32GB 100GB,数据量再增多,就继续加配置。纵向扩展的好处是实施起来简单,但也存在潜在问题:
如果使用了 RDB 数据持久化,随着数据量增加,一方面需要的内存也会增加;另一方面在RDB持久化时,主线程会 fork 子进程,而 fork 操作的耗时和 Redis 的数据量是正相关的,数据量越大,fork 操作造成的主线程阻塞的时间就越长,就会导致Redis有时响应变慢。当然,如果不需要RDB持久化就不存在这个问题。
另一个问题是纵向扩展会受到硬件和成本的限制,把内存从 32GB 扩展到 64GB 还算容易,但是,要想扩充到 1TB,就会面临硬件容量和成本上的限制了。 -
横向扩展
横向扩展就是增加 Redis 实例的个数,将数据分散到各个实例上,比如要缓存15GB的数据,使用3台8GB的服务器就可以,一个实例只缓存5GB的数据即可。这就是Redis的 切片集群,也叫分片集群,就是启动多个 Redis 实例组成一个集群,然后按照一定的规则,把收到的数据分到各个实例中去。这种方案只用增加 Redis 的实例个数就行了,不用担心单个实例的硬件和成本限制。
虽然组建切片集群比较麻烦,但是它可以保存大量数据,由于单个实例保存的数据量较小,RDB 持久化时对主线程的阻塞影响也比较小。而且随着用户或业务规模的扩展,保存大量数据的情况通常是无法避免的,那切片集群就是一个非常好的解决方案。
5.4 集群部署
规划6个实例部署到三台服务器上,6个实例的端口依次为 7001 ~ 7006,部署架构如下:
| 服务器 | Redis 实例 |
|---|---|
| 172.17.0.2 | 7001、7002 |
| 172.17.0.3 | 7003、7004 |
| 172.17.0.4 | 7005、7006 |
1、创建数据目录
首先在第一台服务器上操作,先创建几个目录:
# mkdir -p /var/redis/log
# mkdir -p /var/redis/7001
# mkdir -p /var/redis/7002
2、配置文件
将Redis配置文件拷贝两份到 /etc/redis 下,分别为 7001.conf、7002.conf:
# cp /usr/local/src/redis-6.2.5/redis.conf /etc/redis/7001.conf
# cp /usr/local/src/redis-6.2.5/redis.conf /etc/redis/7002.conf
修改配置文件中的如下配置,7001 与文件端口一致即可:
| 配置 | 值 | 说明 |
|---|---|---|
| bind | 172.17.0.2 | 绑定本机IP |
| port | 7001 | 端口 |
| cluster-enabled | yes | 开启集群模式 |
| cluster-config-file | /etc/redis/node-7002.conf | 集群配置文件 |
| cluster-node-timeout | 15000 | 节点存活超时时长 |
| daemonize | yes | 守护进程 |
| pidfile | /var/run/redis_7001.pid | PID文件 |
| dir | /var/redis/7001 | 数据目录 |
| logfile | /var/redis/log/7001.log | 日志文件 |
| appendonly | yes | 开启AOF持久化 |
注意不要在文件中配置 replicaof
3、启动脚本
将Redis启动脚本复制两份到 /etc/init.d/下:
# cp /usr/local/src/redis-6.2.5/utils/redis_init_script /etc/init.d/redis_7001
# cp /usr/local/src/redis-6.2.5/utils/redis_init_script /etc/init.d/redis_7002
然后修改脚本中的端口号:
并在脚本开头添加如下两行注释做开机启动:
# chkconfig: 2345 90 10
# description: Redis is a persistent key-value database
设置开机启动:
# chkconfig redis_7001 on
# chkconfig redis_7002 on
4、启动Redis实例
分别安装上面的方式在三台服务器上加好配置文件和启动脚本,然后分别启动各个实例。
# cd /etc/init.d# ./redis_7001 start
# ./redis_7002 start
如果启动不成功可以查看日志:
cat /var/redis/log/7001.log
5、创建集群
集群管理可以使用官方提供的 redis-cli --cluster 工具,命令格式为:
redis-cli --cluster SUBCOMMAND [ARGUMENTS] [OPTIONS]
创建集群的命令格式如下,--cluster-replicas <arg> 表示每个 master 有几个 slave:
redis-cli --cluster create host1:port1 ... hostN:portN --cluster-replicas <arg>
下面将6个实例创建一个集群,它会自动帮我们分配哪些实例作为 master,哪些作为 slave,并尽量让 master 和 slave 不在同一个服务器上。通过输出结果可以看到集群创建的过程。
[root@centos-01 init.d]# redis-cli --cluster create 172.17.0.2:7001 172.17.0.2:7002 172.17.0.3:7003 172.17.0.3:7004 172.17.0.4:7005 172.17.0.4:7006 --cluster-replicas 1>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.17.0.3:7004 to 172.17.0.2:7001
Adding replica 172.17.0.4:7006 to 172.17.0.3:7003
Adding replica 172.17.0.2:7002 to 172.17.0.4:7005
M: 9b4f3c2ca93b576776e3d3ea5b0c12f5ca7bf646 172.17.0.2:7001slots:[0-5460] (5461 slots) master
S: 9b0751a4b6ea227658ed26576d9bda1f3b01fc04 172.17.0.2:7002replicates 26776d9aef1c511d77efee79a45a63eff18fb4f9
M: 4e2f6532200991c93bbf23f7d4996fbd2aff02ac 172.17.0.3:7003slots:[5461-10922] (5462 slots) master
S: 9a627cad72e4192802237c00e4e570b37241feda 172.17.0.3:7004replicates 9b4f3c2ca93b576776e3d3ea5b0c12f5ca7bf646
M: 26776d9aef1c511d77efee79a45a63eff18fb4f9 172.17.0.4:7005slots:[10923-16383] (5461 slots) master
S: fc25b50d6afe39211a47609287afd250c9e3183b 172.17.0.4:7006replicates 4e2f6532200991c93bbf23f7d4996fbd2aff02ac
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 172.17.0.2:7001)
M: 9b4f3c2ca93b576776e3d3ea5b0c12f5ca7bf646 172.17.0.2:7001slots:[0-5460] (5461 slots) master1 additional replica(s)
M: 26776d9aef1c511d77efee79a45a63eff18fb4f9 172.17.0.4:7005slots:[10923-16383] (5461 slots) master1 additional replica(s)
S: 9a627cad72e4192802237c00e4e570b37241feda 172.17.0.3:7004slots: (0 slots) slavereplicates 9b4f3c2ca93b576776e3d3ea5b0c12f5ca7bf646
S: 9b0751a4b6ea227658ed26576d9bda1f3b01fc04 172.17.0.2:7002slots: (0 slots) slavereplicates 26776d9aef1c511d77efee79a45a63eff18fb4f9
S: fc25b50d6afe39211a47609287afd250c9e3183b 172.17.0.4:7006slots: (0 slots) slavereplicates 4e2f6532200991c93bbf23f7d4996fbd2aff02ac
M: 4e2f6532200991c93bbf23f7d4996fbd2aff02ac 172.17.0.3:7003slots:[5461-10922] (5462 slots) master1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
创建完成后,可以在其它实例上用 redis-cli --cluster check 检查集群状态:
[root@centos-02 init.d]# redis-cli --cluster check 172.17.0.3:7003
172.17.0.3:7003 (4e2f6532...) -> 0 keys | 5462 slots | 1 slaves.
172.17.0.4:7005 (26776d9a...) -> 0 keys | 5461 slots | 1 slaves.
172.17.0.2:7001 (9b4f3c2c...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 172.17.0.3:7003)
M: 4e2f6532200991c93bbf23f7d4996fbd2aff02ac 172.17.0.3:7003slots:[5461-10922] (5462 slots) master1 additional replica(s)
M: 26776d9aef1c511d77efee79a45a63eff18fb4f9 172.17.0.4:7005slots:[10923-16383] (5461 slots) master1 additional replica(s)
S: fc25b50d6afe39211a47609287afd250c9e3183b 172.17.0.4:7006slots: (0 slots) slavereplicates 4e2f6532200991c93bbf23f7d4996fbd2aff02ac
S: 9a627cad72e4192802237c00e4e570b37241feda 172.17.0.3:7004slots: (0 slots) slavereplicates 9b4f3c2ca93b576776e3d3ea5b0c12f5ca7bf646
S: 9b0751a4b6ea227658ed26576d9bda1f3b01fc04 172.17.0.2:7002slots: (0 slots) slavereplicates 26776d9aef1c511d77efee79a45a63eff18fb4f9
M: 9b4f3c2ca93b576776e3d3ea5b0c12f5ca7bf646 172.17.0.2:7001slots:[0-5460] (5461 slots) master1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
6. redis的持久化
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
- RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
- AOF,则是换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库,就像memcache一样。
6.1 RDB
RDB方式,是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
- redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。
- 对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis极高的性能。
- 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
- 虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
6.2 AOF
AOF,英文是Append Only File,即只允许追加不允许改写的文件。
- 如前面介绍的,AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍,就这么简单。
- 我们通过配置redis.conf中的appendonly yes就可以打开AOF功能。如果有写操作(如SET等),redis就会被追加到AOF文件的末尾。
- 默认的AOF持久化策略是每秒钟fsync一次(fsync是指把缓存中的写指令记录到磁盘中),因为在这种情况下,redis仍然可以保持很好的处理性能,即使redis故障,也只会丢失最近1秒钟的数据。
如果在追加日志时,恰好遇到磁盘空间满、inode满或断电等情况导致日志写入不完整,也没有关系,redis提供了redis-check-aof工具,可以用来进行日志修复。
- 因为采用了追加方式,如果不做任何处理的话,AOF文件会变得越来越大,为此,redis提供了AOF文件重写(rewrite)机制,即当AOF文件的大小超过所设定的阈值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。举个例子或许更形象,假如我们调用了100次INCR指令,在AOF文件中就要存储100条指令,但这明显是很低效的,完全可以把这100条指令合并成一条SET指令,这就是重写机制的原理。在进行AOF重写时,仍然是采用先写临时文件,全部完成后再替换的流程,所以断电、磁盘满等问题都不会影响AOF文件的可用性,这点大家可以放心。
- AOF方式的另一个好处,我们通过一个“场景再现”来说明。某同学在操作redis时,不小心执行了FLUSHALL,导致redis内存中的数据全部被清空了,这是很悲剧的事情。不过这也不是世界末日,只要redis配置了AOF持久化方式,且AOF文件还没有被重写(rewrite),我们就可以用最快的速度暂停redis并编辑AOF文件,将最后一行的FLUSHALL命令删除,然后重启redis,就可以恢复redis的所有数据到FLUSHALL之前的状态了。是不是很神奇,这就是AOF持久化方式的好处之一。但是如果AOF文件已经被重写了,那就无法通过这种方法来恢复数据了。
虽然优点多多,但AOF方式也同样存在缺陷,比如在同样数据规模的情况下,AOF文件要比RDB文件的体积大。而且,AOF方式的恢复速度也要慢于RDB方式。
如果你直接执行BGREWRITEAOF命令,那么redis会生成一个全新的AOF文件,其中便包括了可以恢复现有数据的最少的命令集。
如果运气比较差,AOF文件出现了被写坏的情况,也不必过分担忧,redis并不会贸然加载这个有问题的AOF文件,而是报错退出。这时可以通过以下步骤来修复出错的文件:
1.备份被写坏的AOF文件
2.运行redis-check-aof –fix进行修复
3.用diff -u来看下两个文件的差异,确认问题点
4.重启redis,加载修复后的AOF文件
6.3 AOF重写
AOF重写的内部运行原理,我们有必要了解一下。
- 在重写即将开始之际,redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
- 与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
- 当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
- 当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。
6.4 如何选择RDB和AOF
对于我们应该选择RDB还是AOF,官方的建议是两个同时使用。这样可以提供更可靠的持久化方案。
redis的备份和还原,可以借助第三方的工具redis-dump。
6.5 Redis的两种持久化方式的缺点
- RDB需要定时持久化,风险是可能会丢两次持久之间的数据,量可能很大。
- AOF每秒fsync一次指令硬盘,如果硬盘IO慢,会阻塞父进程;风险是会丢失1秒多的数据;在Rewrite过程中,主进程把指令存到mem-buffer中,最后写盘时会阻塞主进程。
7. Redis的常用应用场景
- 缓存
- 排行榜
- 计数器应用
- 共享Session
- 分布式锁
- 社交网络
- 消息队列
- 位操作
7.1 缓存
我们一提到redis,自然而然就想到缓存,国内外中大型的网站都离不开缓存。合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力。并且,Redis相比于memcached,还提供了丰富的数据结构,并且提供RDB和AOF等持久化机制,强的一批。
7.2 排行榜
当今互联网应用,有各种各样的排行榜,如电商网站的月度销量排行榜、社交APP的礼物排行榜、小程序的投票排行榜等等。Redis提供的zset数据类型能够实现这些复杂的排行榜。
比如,用户每天上传视频,获得点赞的排行榜可以这样设计:
1.用户Jay上传一个视频,获得6个赞,可以酱紫:
zadd user:ranking:2021-03-03 Jay 32.过了一段时间,再获得一个赞,可以这样:
zincrby user:ranking:2021-03-03 Jay 13.如果某个用户John作弊,需要删除该用户:
zrem user:ranking:2021-03-03 John4.展示获取赞数最多的3个用户
zrevrangebyrank user:ranking:2021-03-03 0 2
7.3 计数器应用
各大网站、APP应用经常需要计数器的功能,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
7.4 共享Session
如果一个分布式Web服务将用户的Session信息保存在各自服务器,用户刷新一次可能就需要重新登录了,这样显然有问题。实际上,可以使用Redis将用户的Session进行集中管理,每次用户更新或者查询登录信息都直接从Redis中集中获取。
7.5 分布式锁
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
用synchronize或者reentrantlock本地锁肯定是不行的。
如果是并发量不大话,使用数据库的悲观锁、乐观锁来实现没啥问题。
但是在并发量高的场合中,利用数据库锁来控制资源的并发访问,会影响数据库的性能。
实际上,可以用Redis的setnx来实现分布式的锁。
7.6 社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交网站的必备功能,由于社交网站访问量通常比较大,而且传统的关系型数据不太适保存 这种类型的数据,Redis提供的数据结构可以相对比较容易地实现这些功能。
7.7 消息队列
消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。
7.8 位操作
用于数据量上亿的场景下,例如几亿用户系统的签到,去重登录次数统计,某用户是否在线状态等等。腾讯10亿用户,要几个毫秒内查询到某个用户是否在线,能怎么做?千万别说给每个用户建立一个key,然后挨个记(你可以算一下需要的内存会很恐怖,而且这种类似的需求很多。这里要用到位操作——使用setbit、getbit、bitcount命令。原理是:redis内构建一个足够长的数组,每个数组元素只能是0和1两个值,然后这个数组的下标index用来表示用户id(必须是数字哈),那么很显然,这个几亿长的大数组就能通过下标和元素值(0和1)来构建一个记忆系统。
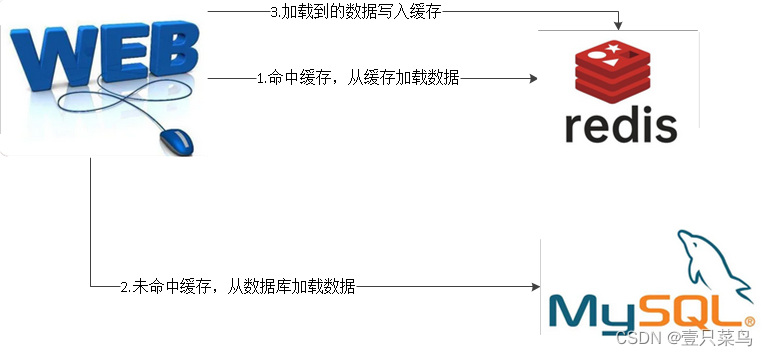
8. Redis + MySQL
为了提升mysql的性能,现在大部分应用都会采用redis+mysql的结构。
为什么要这么设计?主要是因为redis在key value值查询的速度高于mysql,所以加个缓存性能能立马提升!那为什么不全部使用redis呢?因为redis本身作为内存型数据库,容量有限,存不了太大的数据,在这个动不动上亿数据的时代肯定吃不消,而mysql是在硬盘上的,有多少可以加多少。