作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
ETL
- **作者前言**
- ETL的介绍
- 安装
- 使用
- 总结
ETL的介绍
ETL:任务调度系统。主要是位为了方便管理、运行相关的数据脚本。通过图形化界面,更好的观察数据走向与脚本执行的步骤。进行数仓管理和数据分析,ETL是必不可少的工具之一。
安装
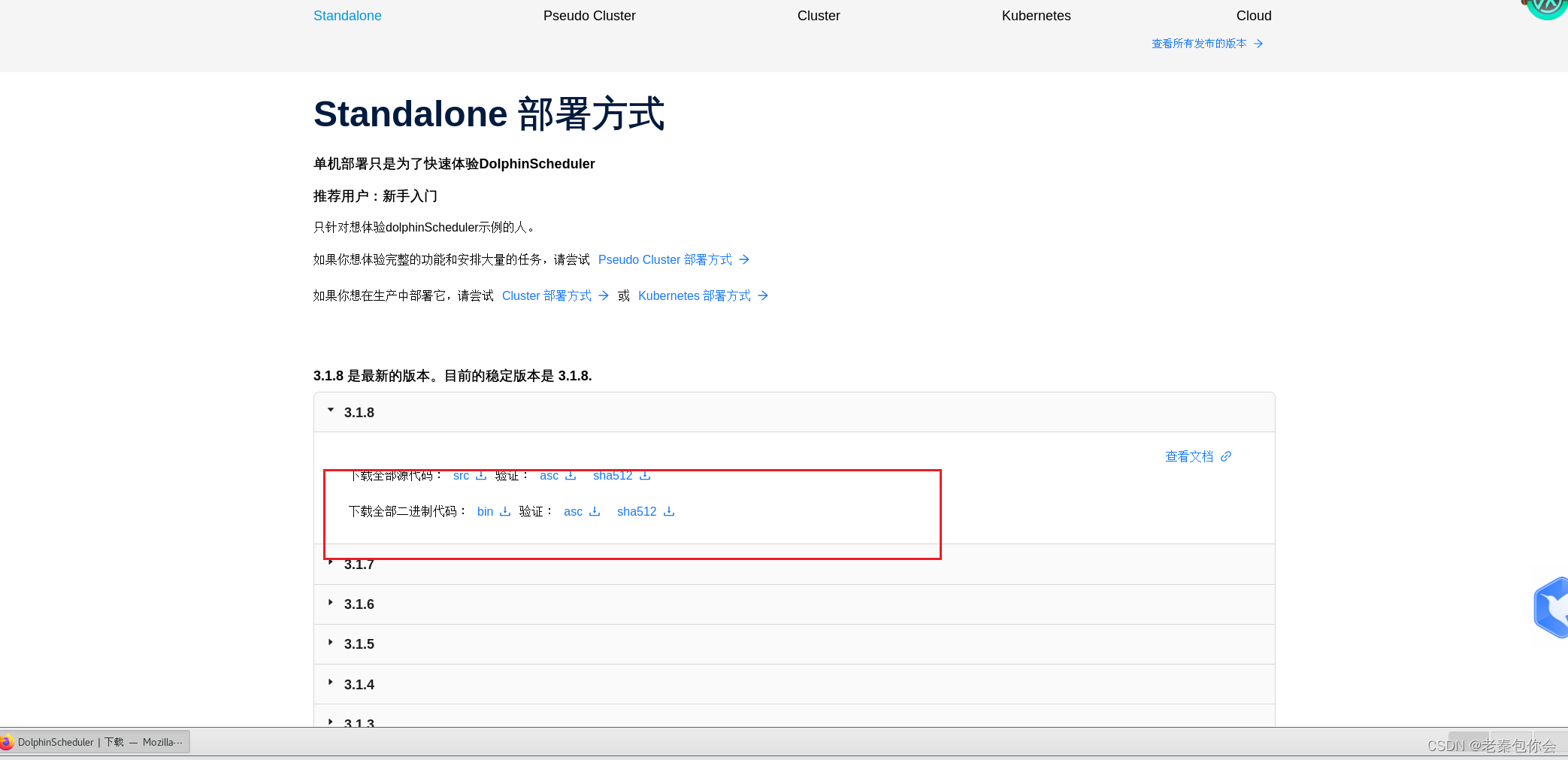
1、进入到官网ETF
2、进入到下载页面,

这里我选择单机部署
3. 环境准备。在终端输入 java -version ,保证版本在1.8以上, java -verbose 查看JDK路径


编辑打开 vim /etc/profile ,在最后面添加
# java
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_333
export JER_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
JAVA_HOME的路径一定要是 java -verbose 里对应的jdk路径
保存后重置环境配置
source /etc/profile
配置ETL环境
# 解压并运行 Standalone Server
tar -xvzf apache-dolphinscheduler-3.1.2-bin.tar.gz
在apache-dolphinscheduler-3.1.2-bin中,打开conf/env/dolphinscheduler_env.sh
在最下面进行修改
# export HADOOP_HOME=/opt/soft/hadoop
# export HADOOP_CONF_DIR=/opt/soft/hadoop/etc/hadoop
# export SPARK_HOME1=/opt/soft/spark1
# export SPARK_HOME2=/opt/soft/spark2
# export PYTHON_HOME=/opt/soft/python
export PYTHON_HOME=/home/tisugou/anaconda3/bin/python3.9
# export JAVA_HOME=${JAVA_HOME:-/opt/soft/java}
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_333
# export HIVE_HOME=/opt/soft/hive
# export FLINK_HOME=/opt/soft/flink
# export DATAX_HOME=/opt/soft/datax
# export
PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_H
OME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH
export PATH=$PYTHON_HOME:$JAVA_HOME/bin:$PATH
因为只用到了Python和Java,所以可以将其他的路径全部注释掉
- 解压并启动 DolphinScheduler
tar -xvzf apache-dolphinscheduler-3.1.2-bin.tar.gz
cd apache-dolphinscheduler-3.1.2-bin
sh ./bin/dolphinscheduler-daemon.sh start standalone-server
# 启停服务
# 启动 Standalone Server 服务
sh ./bin/dolphinscheduler-daemon.sh start standalone-server
# 停止 Standalone Server 服务
sh ./bin/dolphinscheduler-daemon.sh stop standalone-server

我的是解压到这个文件里面我们要找到对应的文件进行运行

使用
登录


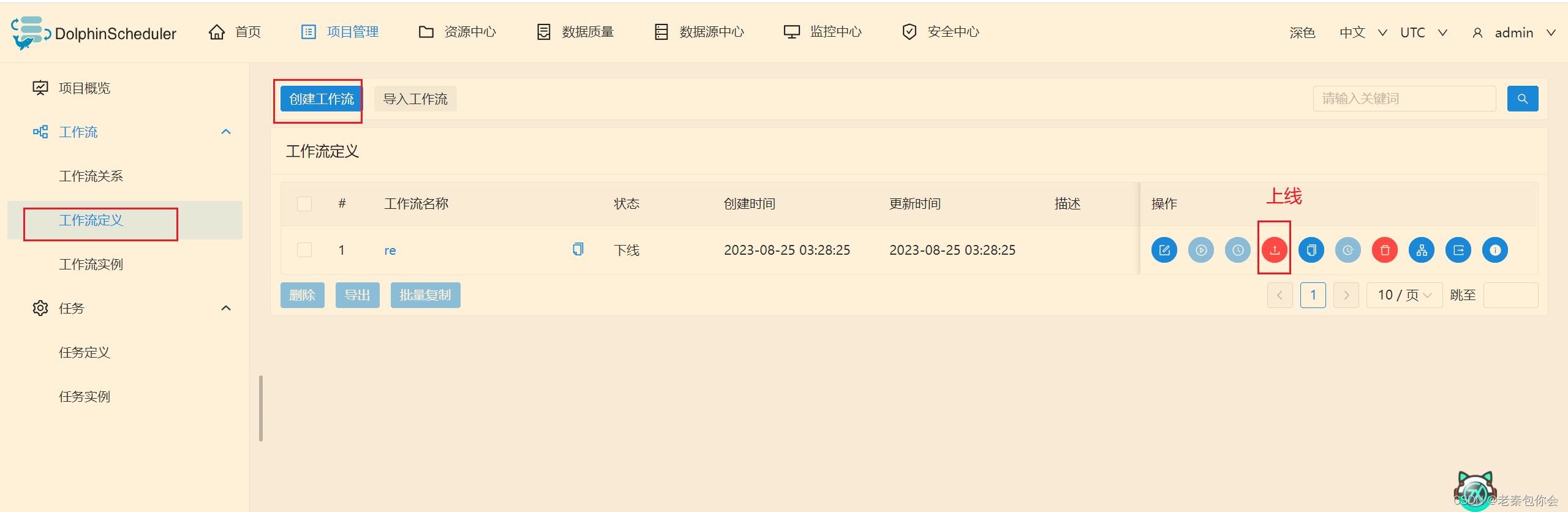
如果我们直接创建好这个,不做处理就会默认是同时运行的
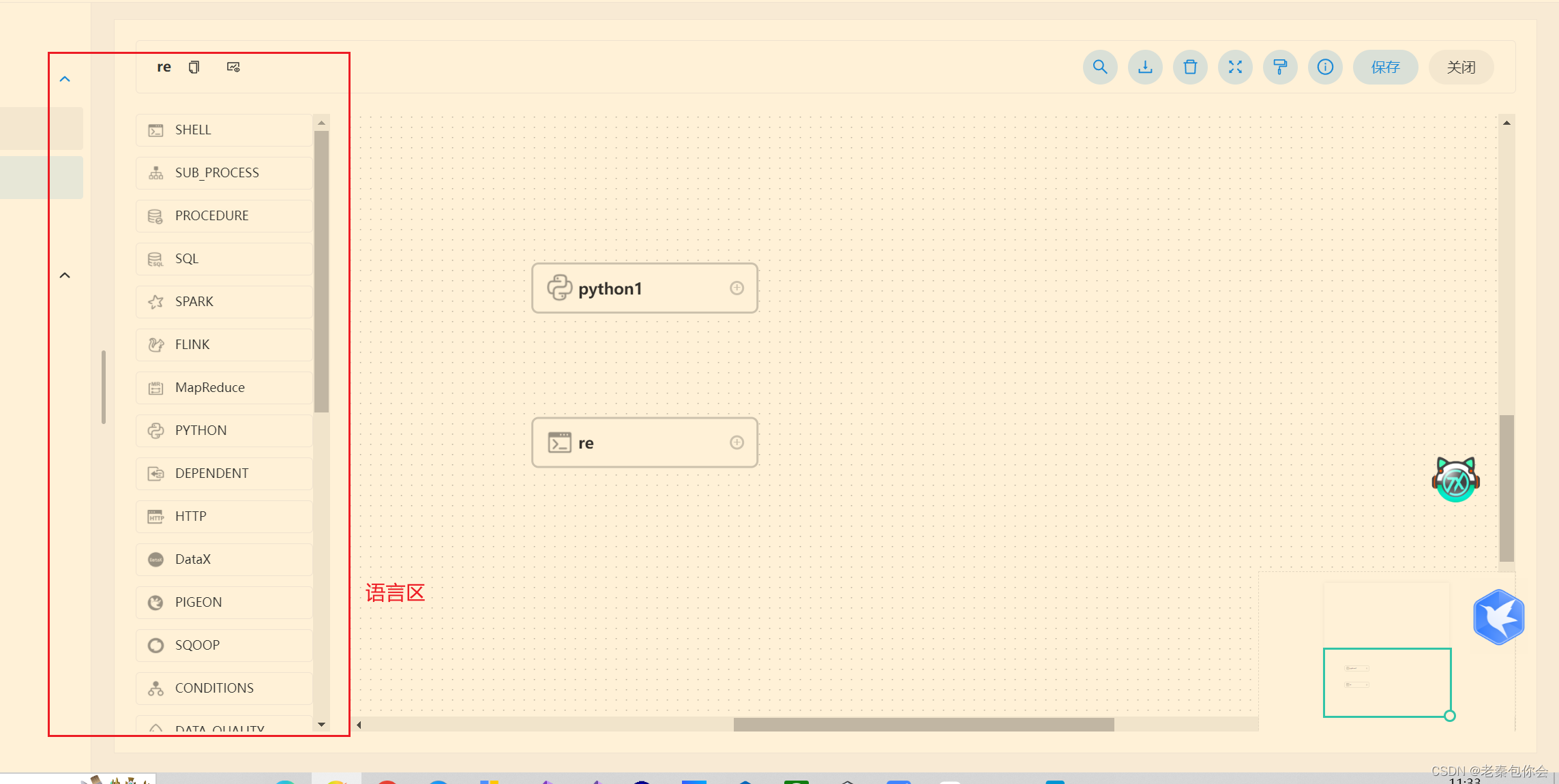
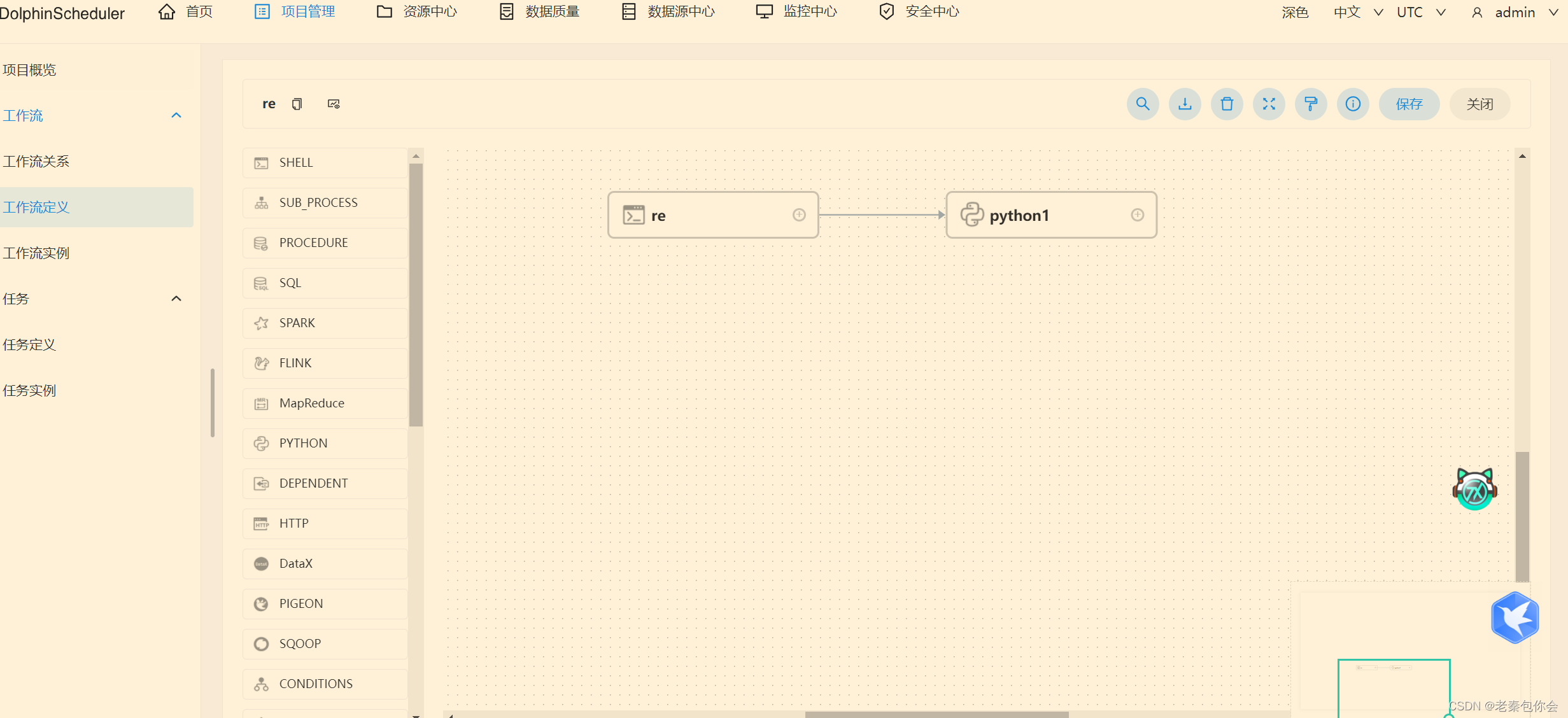
如果我们做出下面操作就会先运行第一个再运行第二个,如果第一个运行失败就会停留在第一步,就是要第一步运行成功才能运行第二步
总结
ETL的简单介绍完了,有不懂的小可爱可以私聊我