PyTorch 模型进阶训练技巧
- 自定义损失函数 如 cross_entropy + L2正则化
- 动态调整学习率 如每十次 *0.1
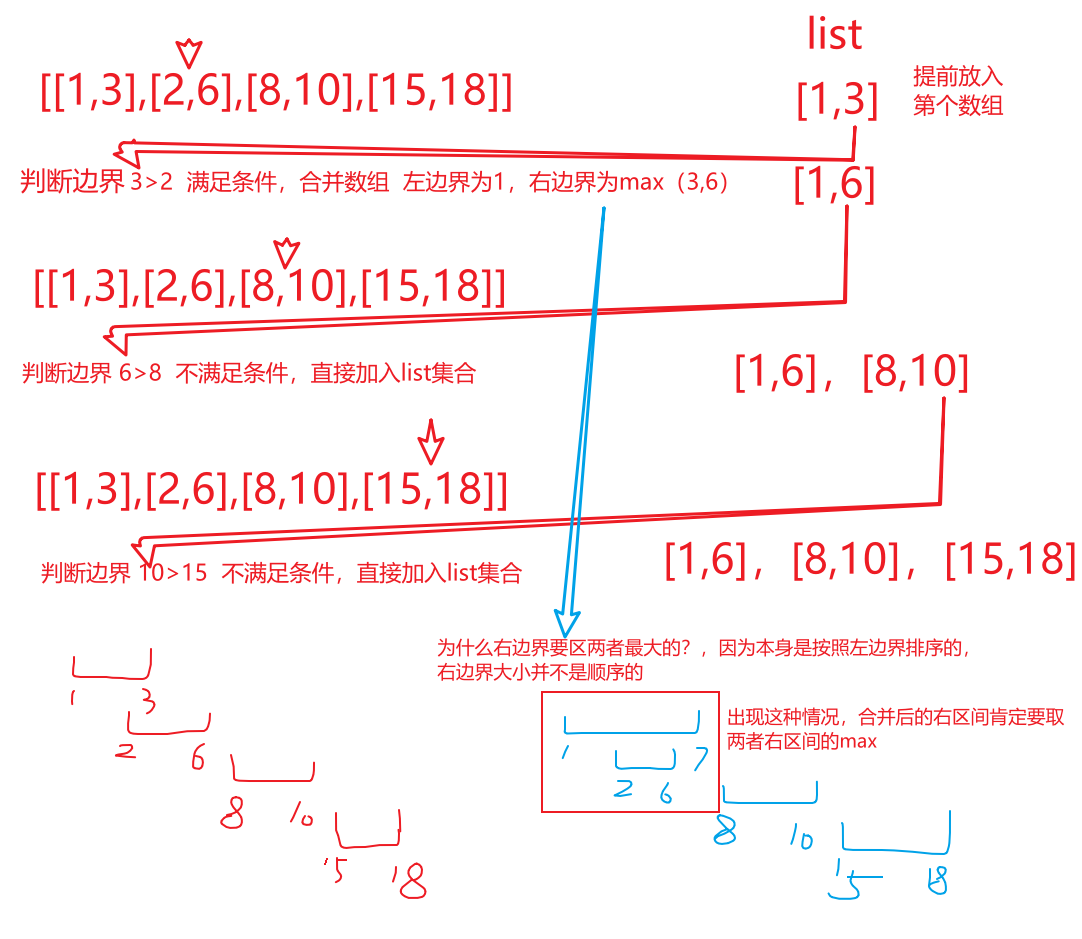
典型案例:loss上下震荡
1、自定义损失函数
-
1、PyTorch已经提供了很多常用的损失函数,但是有些非通用的损失函数并未提供,比如:DiceLoss、HuberLoss…等
-
2、模型如果出现loss震荡,在经过调整数据集或超参后,现象依然存在,非通用损失函数或自定义损失函数针对特定模型会有更好的效果
比如:DiceLoss是医学影像分割常用的损失函数,定义如下:
-
Dice系数, 是一种集合相似度度量函数,通常用于计算两个样本的相似度(值范围为 [0, 1]):
-
∣X∩Y∣表示X和Y之间的交集,∣ X ∣ 和∣ Y ∣ 分别表示X和Y的元素个数,其中,分子中的系数 2,是因为分母存在重复计算 X 和 Y 之间的共同元素的原因.
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
from torch.optim.lr_scheduler import StepLR
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import time
import numpy as np
#DiceLoss 实现 Vnet 医学影像分割模型的损失函数
class DiceLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(DiceLoss, self).__init__()def forward(self, inputs, targets, smooth=1):inputs = F.sigmoid(inputs) inputs = inputs.view(-1)targets = targets.view(-1)intersection = (inputs * targets).sum() dice_loss = 1 - (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)return dice_loss
#自定义实现多分类损失函数 处理多分类
# cross_entropy + L2正则化
class MyLoss(torch.nn.Module):def __init__(self, weight_decay=0.01):super(MyLoss, self).__init__()self.weight_decay = weight_decaydef forward(self, inputs, targets):ce_loss = F.cross_entropy(inputs, targets)l2_loss = torch.tensor(0., requires_grad=True).to(inputs.device)for name, param in self.named_parameters():if 'weight' in name:l2_loss += torch.norm(param)loss = ce_loss + self.weight_decay * l2_lossreturn loss注:
- 在自定义损失函数时,涉及到数学运算时,我们最好全程使用PyTorch提供的张量计算接口
- 利用Pytorch张量自带的求导机制
#超参数定义
# 批次的大小
batch_size = 16 #可选32、64、128
# 优化器的学习率
lr = 1e-4
#运行epoch
max_epochs = 2
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号
# 数据读取
#cifar10数据集为例给出构建Dataset类的方式
from torchvision import datasets#“data_transform”可以对图像进行一定的变换,如翻转、裁剪、归一化等操作,可自己定义
data_transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])train_cifar_dataset = datasets.CIFAR10('cifar10',train=True, download=False,transform=data_transform)
test_cifar_dataset = datasets.CIFAR10('cifar10',train=False, download=False,transform=data_transform)#构建好Dataset后,就可以使用DataLoader来按批次读入数据了
train_loader = torch.utils.data.DataLoader(train_cifar_dataset, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)test_loader = torch.utils.data.DataLoader(test_cifar_dataset, batch_size=batch_size, num_workers=4, shuffle=False)# restnet50 pretrained
Resnet50 = torchvision.models.resnet50(pretrained=True)
Resnet50.fc.out_features=10
print(Resnet50)
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)))(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))(fc): Linear(in_features=2048, out_features=10, bias=True)
)
#训练&验证# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 损失函数:自定义损失函数
criterion = MyLoss()
# 优化器
optimizer = torch.optim.Adam(Resnet50.parameters(), lr=lr)
epoch = max_epochs
Resnet50 = Resnet50.to(device)
total_step = len(train_loader)
train_all_loss = []
test_all_loss = []for i in range(epoch):Resnet50.train()train_total_loss = 0train_total_num = 0train_total_correct = 0for iter, (images,labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)outputs = Resnet50(images)loss = criterion(outputs,labels)train_total_correct += (outputs.argmax(1) == labels).sum().item()#backwordoptimizer.zero_grad()loss.backward()optimizer.step()train_total_num += labels.shape[0]train_total_loss += loss.item()print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))Resnet50.eval()test_total_loss = 0test_total_correct = 0test_total_num = 0for iter,(images,labels) in enumerate(test_loader):images = images.to(device)labels = labels.to(device)outputs = Resnet50(images)loss = criterion(outputs,labels)test_total_correct += (outputs.argmax(1) == labels).sum().item()test_total_loss += loss.item()test_total_num += labels.shape[0]print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100))train_all_loss.append(np.round(train_total_loss / train_total_num,4))test_all_loss.append(np.round(test_total_loss / test_total_num,4))Epoch [1/10], Iter [3124/3125], train_loss:0.054007
Epoch [1/10], Iter [3125/3125], train_loss:0.042914---------------------------------------------------------------------------
2、动态调整学习率
2.1 torch.optim.lr_scheduler
学习率选择的问题:
- 1、学习率设置过小,会极大降低收敛速度,增加训练时间
- 2、学习率设置太大,可能导致参数在最优解两侧来回振荡
以上问题都是学习率设置不满足模型训练的需求,解决方案:
- PyTorch中提供了scheduler
官方API提供的torch.optim.lr_scheduler动态学习率:
-
lr_scheduler.LambdaLR
-
lr_scheduler.MultiplicativeLR
-
lr_scheduler.StepLR
-
lr_scheduler.MultiStepLR
-
lr_scheduler.ExponentialLR
-
lr_scheduler.CosineAnnealingLR
-
lr_scheduler.ReduceLROnPlateau
-
lr_scheduler.CyclicLR
-
lr_scheduler.OneCycleLR
-
lr_scheduler.CosineAnnealingWarmRestarts
2.2、torch.optim.lr_scheduler.LambdaLR
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
# LambdaLR 实现
lr_lambda = f(epoch)
new_lr = lr_lambda * init_lr
思想:初始学习率乘以系数,由于每一次乘系数都是乘初始学习率,因此系数往往是epoch的函数。
#伪代码:Assuming optimizer has two groups.lambda1 = lambda epoch: 1 / (epoch+1)scheduler = LambdaLR(optimizer, lr_lambda=lambda1)for epoch in range(100):train(...)validate(...)scheduler.step()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f4P8ROuA-1692613806234)(attachment:image-2.png)]](https://img-blog.csdnimg.cn/e75fe707f9904b3c9e68afa31ef69d16.png)
MultiplicativeLR
torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)
与LambdaLR不同,该方法用前一次的学习率乘以lr_lambda,因此通常lr_lambda函数不需要与epoch有关。
new_lr = lr_lambda * old_lr![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g2URgkPf-1692613806234)(attachment:image.png)]](https://img-blog.csdnimg.cn/98d811e5b02b4b4db04892ef5c8cc50e.png)
2.2、自定义scheduler
官方给的动态学习率调整的API如果均不能满足我们的诉求,应该怎么办?
我们可以通过自定义函数adjust_learning_rate来改变param_group中lr的值
- 1、官方的API均不能满足诉求
- 2、我们根据adjust_learning_rate实现学习率调整方法
# 训练中调用学习率方法
optimizer = torch.optim.SGD(model.parameters(),lr = args.lr,momentum = 0.9)
for epoch in range(10):train(...)validate(...)adjust_learning_rate(optimizer,epoch)
#函数:分段,每隔几(10)段个epoch,第一个epoch为序号0不计,使学习率变乘以0.1的epoch次方数
def adjust_learning_rate(optim, epoch, size=10, gamma=0.1):if (epoch + 1) % size == 0:pow = (epoch + 1) // sizelr = learning_rate * np.power(gamma, pow)for param_group in optim.param_groups:param_group['lr'] = lr
代码实例
- lr_scheduler.LambdaLR
- adjust_learning_rate
#训练&验证
writer = SummaryWriter("../train_skills")
# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(Resnet50.parameters(), lr=lr)# 自定义 scheduler
scheduler_my = LambdaLR(optimizer, lr_lambda=lambda epoch: 1/(epoch+1),verbose = True)
print("初始化的学习率:", optimizer.defaults['lr'])epoch = max_epochs
Resnet50 = Resnet50.to(device)
total_step = len(train_loader)
train_all_loss = []
test_all_loss = []for i in range(epoch):Resnet50.train()train_total_loss = 0train_total_num = 0train_total_correct = 0for iter, (images,labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)outputs = Resnet50(images)loss = criterion(outputs,labels)train_total_correct += (outputs.argmax(1) == labels).sum().item()#backwordoptimizer.zero_grad()loss.backward()optimizer.step()train_total_num += labels.shape[0]train_total_loss += loss.item()print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))writer.add_scalar("lr", optim.param_groups[0]['lr'], i)print("第%d个epoch的学习率:%f" % (epoch, optimizer.param_groups[0]['lr']))scheduler_my.step() #scheduler#自定义调整lr
# adjust_learning_rate(optimizer, i)Resnet50.eval()test_total_loss = 0test_total_correct = 0test_total_num = 0for iter,(images,labels) in enumerate(test_loader):images = images.to(device)labels = labels.to(device)outputs = Resnet50(images)loss = criterion(outputs,labels)test_total_correct += (outputs.argmax(1) == labels).sum().item()test_total_loss += loss.item()test_total_num += labels.shape[0]print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100))train_all_loss.append(np.round(train_total_loss / train_total_num,4))test_all_loss.append(np.round(test_total_loss / test_total_num,4))
writer.close()
Adjusting learning rate of group 0 to 1.0000e-04.
初始化的学习率: 0.0001
Epoch [1/2], Iter [1/3125], train_loss:0.777986