为了对特征进行变换,常规的前馈神经网络独立地在每个像素位置进行相同的操作。它使用两个1x1卷积层,一个用来扩展特征通道(通常4倍),第二个用来将特征通道减少到原来的输入维度。在隐藏层中加入非线性。
GDFN做了两个基本的改进:
- 门机制
- 深度可分离卷积
架构如下图:
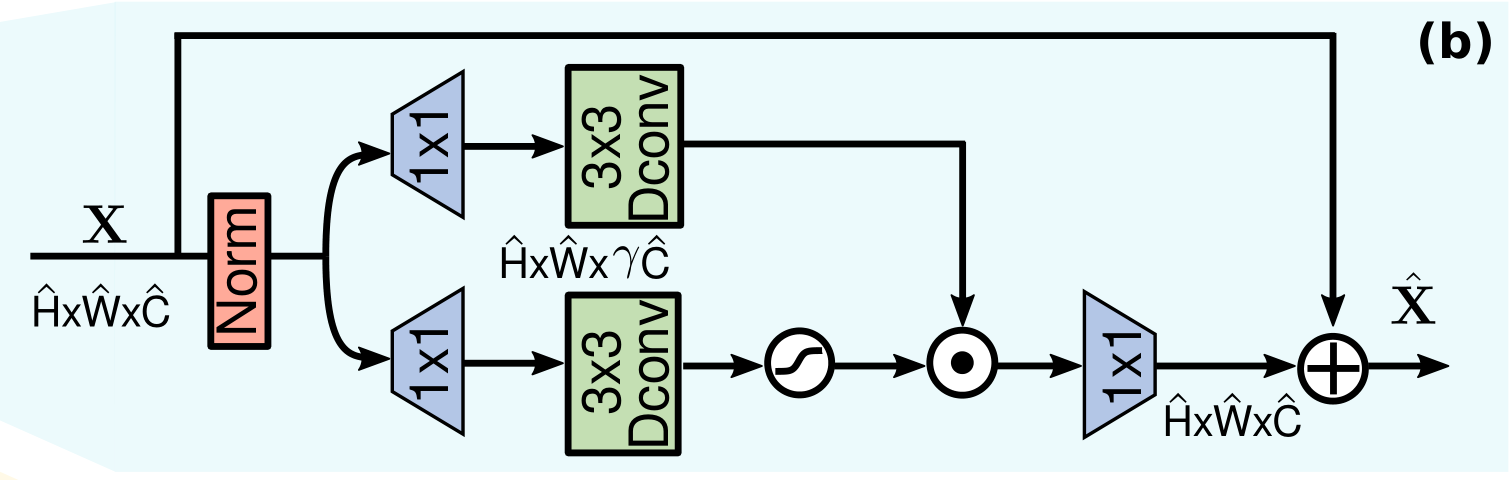
门机制通过经过线性变换的两个平行通道的逐元素点积实现,其中一个通道用GELU激活,可以参考Gaussian Error Linear Units (GELUs)

深度可分离卷积用来编码空间上邻域像素的信息,有助于学习局部图像结构。
Given an input tensor X ∈ R H ^ × W ^ × C ^ \mathbf{X} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} X∈RH^×W^×C^, GDFN is formulated as:
X ^ = W p 0 Gating ( X ) + X Gating ( X ) = ϕ ( W d 1 W p 1 ( LN ( X ) ) ) ⊙ W d 2 W p 2 ( LN ( X ) ) \begin{aligned} \hat{\mathbf{X}} & =W_p^0 \text { Gating }(\mathbf{X})+\mathbf{X} \\ \operatorname{Gating}(\mathbf{X}) & =\phi\left(W_d^1 W_p^1(\operatorname{LN}(\mathbf{X}))\right) \odot W_d^2 W_p^2(\operatorname{LN}(\mathbf{X})) \end{aligned} X^Gating(X)=Wp0 Gating (X)+X=ϕ(Wd1Wp1(LN(X)))⊙Wd2Wp2(LN(X))where ⊙ \odot ⊙ denotes element-wise multiplication, ϕ \phi ϕ represents the GELU non-linearity, and LN is the layer normalization
实现代码
## Gated-Dconv Feed-Forward Network (GDFN)
class FeedForward(nn.Module):def __init__(self, dim, ffn_expansion_factor, bias):super(FeedForward, self).__init__()hidden_features = int(dim*ffn_expansion_factor)self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2,\kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)def forward(self, x):x = self.project_in(x)x1, x2 = self.dwconv(x).chunk(2, dim=1)x = F.gelu(x1) * x2x = self.project_out(x)return x
上面这段代码实现的是(b)图从 Norm模块后面开始到残差连接之前的线性过程。

在封装成Transformer Block的时候用了层标准化以及残差连接,如图(b)所示