朋友们,AIGC性能优化大赛已经结束了,看新闻很多队员已经完成了答辩和领奖环节,我根据内幕人了解到,比赛的最终代码及结果是不会分享出来的,因为办比赛的目的就是吸引最优秀的代码然后给公司节省自己开发的成本,相当于外包出去了,应该是不会公开的。抱着技术共享及开放的精神,我今天把以自己复赛排名top10的经验分享出来,希望可以给参赛的朋友提供一些有帮助的信息(个人账号:我是你的狼哥)。

首先,我把比赛的草稿版本分享出来:文本生成:AIGC推理性能优化比赛_复赛及初赛第10名经验分享 - 飞桨AI Studio
这个版本省略了很多内容,因为最原始的版本里面存在大量的临时文件、测试文件和个人代码,这个版本相当于阉割了一部分,但是我会先把具体内容给大家介绍下,这样理解起来也容易。
1、方法探索
优化模型推理,官方已经给了一些基础建议,其实最开始大家就可以按照官方去做,就有提升,这中间我也踩了很多坑,同样分享出来。
(1)调节超参数,可行
调节超参数,是最快,最便捷的一个方法,但是要注意方式方法,如果你无厘头瞎jb调,会出现一会高一会低,你要想办法去接近极限,这个可以参考用到网格搜索,下面是项目中一个简单案例,在new/new.ipynb项目中
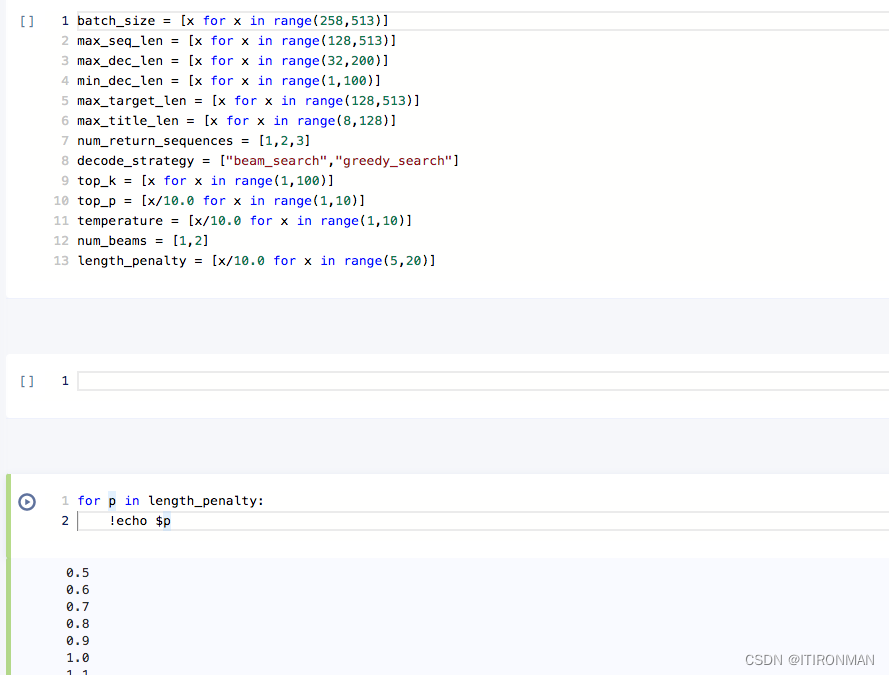
上面的代码可以自行完善,我有一个predict.py 文件,你可以挨个for循环,然后记录下最佳参数的推理速度,固化参数即可,原来我记得官方base的成绩,不调优大概是460s,如果仅通过这一项大概能优化到200s以上,但是你想再优化,那就非常难了,需要别的办法。
(2)直接调用静态库,可行
调节超参数,是挺简单的,但是他有瓶颈,你再优化可就难了,这个时候,你需要去翻paddlepaddle的源码,他推理里面就带有一些优化方法,比如
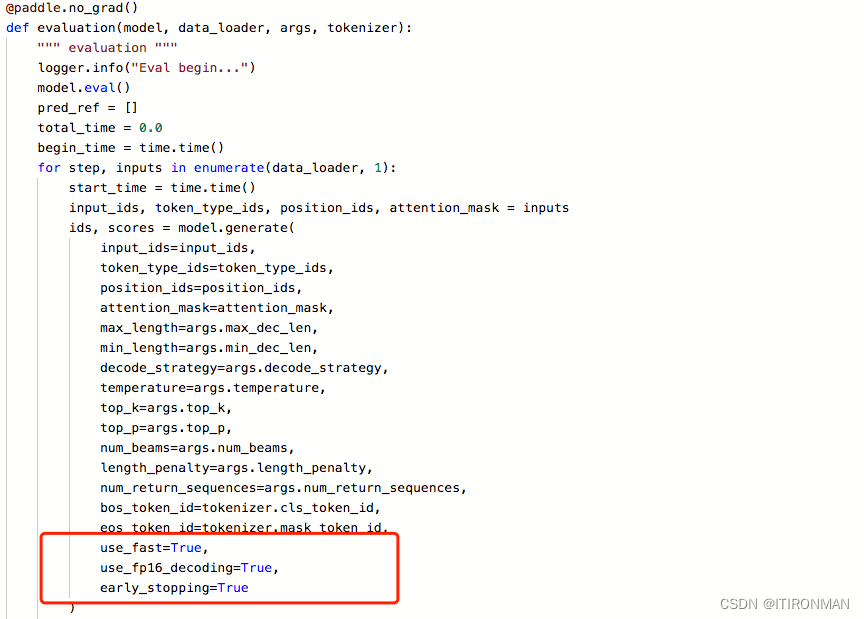
官方的run_infer.py里面,如果你在model.generate最后面三行加上这个东西,你就会发现,速度突然飞起来了,大概是能优化100s左右,好快啊!
不久,你又发现一个很奇葩的问题,你加了这个use_fast=True以后,虽然快了,但是每次第一次推理的时候,都需要重新下载、编译这个模块的静态库文件,贼慢,起码40-50s,太耗时了,不过,你翻官方文件,你会发现他只有第一次推理的时候很慢,后面就直接调用编译好的那个库文件了,会非常快!那怎么办呢?好办,我们直接把编译好的库文件找到直接调用不得了,结果证明非常可行,速度提高30-50s。
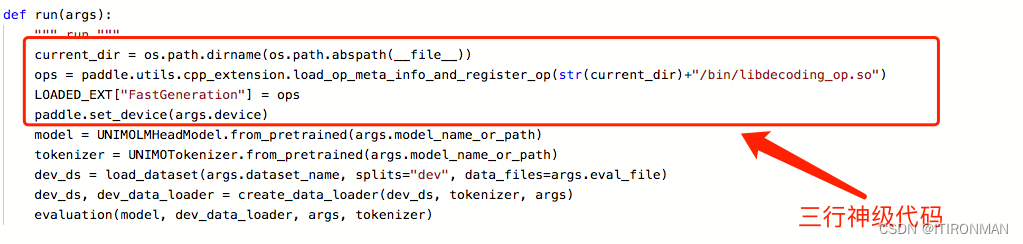
有人问了,我如何找这个so库文件,其实也很简单,你第一次推理让他原来的方式推理,推理完成后,它会自动生成这个libdecoding_op.so,直接用find全局搜就找到了,其实这是一个cpp编写的推理算子,可见cpp在这方面效率远高于python,这里还埋了一个点,后面讲。
(3)动态图转静态图推理,不可行
我估计,90%的人第一次尝试都会想着把编码阶段的动态图推理转为静态图推理,我也这么干了,并且忙活了半天,发现一个真相,速度更慢了~,没办法,试了好几次还是不行,这条路放弃了。

下面是转换代码
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.import argparse
import os
from pprint import pprintimport paddlefrom paddlenlp.ops import FasterUNIMOText
from paddlenlp.transformers import UNIMOLMHeadModel, UNIMOTokenizer
from paddlenlp.utils.log import loggerdef parse_args():parser = argparse.ArgumentParser()parser.add_argument("--model_name_or_path",default="/home/aistudio/ad_generator/model_final",type=str,help="The model name to specify the Pegasus to use. ",)parser.add_argument("--export_output_dir", default="./inference_model", type=str, help="Path to save inference model of Pegasus. ")parser.add_argument("--topk", default=80, type=int, help="The number of candidate to procedure top_k sampling. ")parser.add_argument("--topp", default=0.8, type=float, help="The probability threshold to procedure top_p sampling. ")parser.add_argument("--max_out_len", default=128, type=int, help="Maximum output length. ")parser.add_argument("--min_out_len", default=6, type=int, help="Minimum output length. ")parser.add_argument("--num_return_sequence", default=1, type=int, help="The number of returned sequence. ")parser.add_argument("--temperature", default=0.8, type=float, help="The temperature to set. ")parser.add_argument("--num_return_sequences", default=2, type=int, help="The number of returned sequences. ")parser.add_argument("--use_fp16_decoding", action="store_true", help="Whether to use fp16 decoding to predict. ")parser.add_argument("--decoding_strategy",default="beam_search",choices=["beam_search"],type=str,help="The main strategy to decode. ",)parser.add_argument("--num_beams", default=2, type=int, help="The number of candidate to procedure beam search. ")parser.add_argument("--diversity_rate", default=0.0, type=float, help="The diversity rate to procedure beam search. ")parser.add_argument("--length_penalty",default=1.2,type=float,help="The exponential penalty to the sequence length in the beam_search strategy. ",)args = parser.parse_args()return argsdef do_predict(args):place = "gpu:0"place = paddle.set_device(place)model_name_or_path = args.model_name_or_pathmodel = UNIMOLMHeadModel.from_pretrained(model_name_or_path)tokenizer = UNIMOTokenizer.from_pretrained(model_name_or_path)unimo_text = FasterUNIMOText(model=model, use_fp16_decoding=args.use_fp16_decoding, trans_out=True)# Set evaluate modeunimo_text.eval()# Convert dygraph model to static graph modelunimo_text = paddle.jit.to_static(unimo_text,input_spec=[# input_idspaddle.static.InputSpec(shape=[None, None], dtype="int64"),# token_type_idspaddle.static.InputSpec(shape=[None, None], dtype="int64"),# attention_maskpaddle.static.InputSpec(shape=[None, 1, None, None], dtype="float32"),# seq_lenpaddle.static.InputSpec(shape=[None], dtype="int64"),args.max_out_len,args.min_out_len,args.topk,args.topp,args.num_beams, # num_beams. Used for beam_search.args.decoding_strategy,tokenizer.cls_token_id, # cls/bostokenizer.mask_token_id, # mask/eostokenizer.pad_token_id, # padargs.diversity_rate, # diversity rate. Used for beam search.args.temperature,args.num_return_sequences,],)# Save converted static graph modelpaddle.jit.save(unimo_text, os.path.join(args.export_output_dir, "unimo_text"))logger.info("UNIMOText has been saved to {}.".format(args.export_output_dir))if __name__ == "__main__":args = parse_args()pprint(args)do_predict(args)(4)系统参数优化,可行
还是那句话,看paddlepaddle源码,你会有很多惊喜,源码里面有系统调优的方法,主要是对显卡调优的,于是,你可以加上下面这段神代码。

于是,你又可以提高1-3s,又是个小里程碑进步。
(5)推理代码全部改写cpp,可行但不会
在(2)的时候我埋了个点,我说后面讲,其实就是你可以把整个推理的代码也就是model.generate,全部改写为cpp,这个肯定会有大幅度提高,但是呢,我不会!我不会写cpp啊,这个只能留着自己私下尝试了,并且我问了内幕人,这个肯定可行的,私下自己试试吧,这个跟模型没关系了,是个工程的活,展开讲也没啥意思,就是个翻译过程,自己搞吧!
(6)tensorRT优化,未知
其实还有个tensorRT优化的办法,这个我试了个demo,代码里面可能有些demo尝试,效果不明显,就没往下尝试,这个效果未知,自己试试吧。
2、整体总结
上面是我整个项目的尝试,具体细节信息各位赛友自己跑一跑我的代码才知道,里面有很多错误尝试,包括我甚至还尝试了内存共享技术、多线程技术、多进程技术和异步处理等等,都不是很理想,可能你们尝试后会有提高,这里面提升最大的还得是超参优化和so库调用。