文章目录
- 本节课大纲
- Hyper-simplified linguistics
- Term spotting + handling negation, uncertainty
- ML to expand terms
- pre-NN ML to identify entities and relations
- Latent Dirichlet Allocation (LDA)
- Statistical Models of Language: Zipf's law
- vector space embeddings based on co-occurrence
- language models
- 循环神经网络RNN
- LSTM
- ELMo
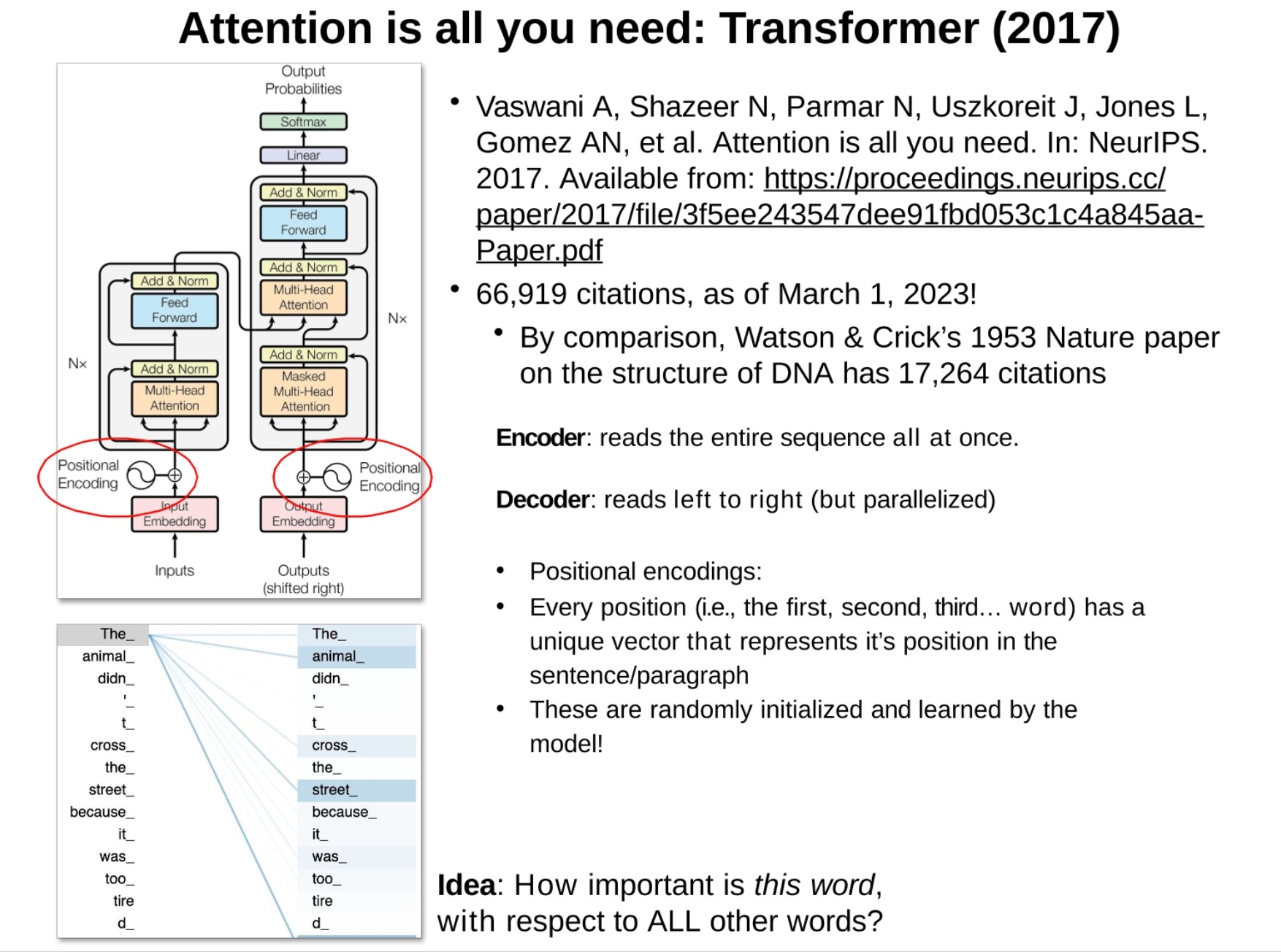
- Transformer
来自Manolis Kellis教授(MIT计算生物学主任)的课《人工智能与机器学习》
本文是NLP的铺垫,很多基础的知识,讲的主要是传统的一些方法,对于深入现代的RNN、LSTM、BERT、Transformer、GPT等等模型可以说是必备的。
主要讲了文本的语法和语义关系、不确定性(医学文本)、LDA主题模型、N-gram models、词嵌入是啥(embedding)。解决了我以前只学模型的一些困惑。
最后粗略的过了一下大语言模型(LLMs)并给出了几个好的视频链接(台大李宏毅),等我学完后会再写一篇关于LLM的博客
本节课大纲

课程大纲:
数据在临床文本中的价值
过于简化的语言学
术语识别 + 处理否定和不确定性
使用机器学习扩展术语
预神经网络机器学习用于识别实体和关系
语言模型
基于共现建立的向量空间嵌入
增加上下文以帮助消除歧义
从嵌入单词到短语,句子等
解释:
- 数据在临床文本中的价值:这部分会探讨如何从临床医疗文本中获取有价值的信息,这对于诊断和治疗都很重要。
- 过于简化的语言学:这部分会介绍一些语言学基础,尽管这是非常简化的版本,但它将帮助理解后续内容。
- 术语识别 + 处理否定和不确定性:这部分将学习如何从文本中找出关键术语,同时还会学习处理否定和不确定性的策略,这对于理解医学文本很关键。
- 使用机器学习扩展术语:在这部分,我们将使用机器学习方法来扩展识别到的术语,增强其信息的完整性和准确性。
- 预神经网络机器学习用于识别实体和关系:在神经网络模型出现之前的机器学习方法用于识别文本中的实体和它们之间的关系。
- 语言模型:这部分将介绍语言模型的基础知识,语言模型是理解和生成文本的重要工具。
- 基于共现建立的向量空间嵌入:这部分会介绍如何利用词语的共现信息建立词向量,这是一种表达文本信息的方式。
- 增加上下文以帮助消除歧义:通过加入上下文信息,能帮助理解和消除歧义,提高文本理解的准确性。
- 从嵌入单词到短语,句子等:扩展了词向量的概念,从单词扩展到短语,句子,甚至更大的文本单元,使得我们可以更好的理解和表示复杂的文本信息。
Hyper-simplified linguistics
语法+句法->语义,这段部分比较复杂和抽象,了解一下就行

-
长久以来对语法和句法的兴趣: 我们对于语法和句法的研究已经有很长一段时间了。语法和句法是语言的基础结构,它们决定了我们如何构造句子和表达意思。
- 语义: 语义是语言的意义层面,研究词语和句子的实际含义。
-
基于上下文敏感的产生规则定义的语法: 语法可以被定义为一系列的产生规则,这些规则会根据上下文进行变化。
-
举个例子
-
首先,我们来理解一下什么是生成规则(production rules)。在计算机语言学中,生成规则是用来描述语言的语法结构的。它们的形式通常是“X → Y”,表示X可以被替换成Y。例如,我们可以有一个生成规则“句子 → 主语 + 谓语”,表示一个句子可以由一个主语和一个谓语组成。
然后,我们来看看什么是上下文敏感的生成规则。这个概念是从上下文敏感文法(context-sensitive grammar)中引申出来的。在上下文敏感文法中,生成规则的形式变为了“X → Y”,其中X和Y都可以是一个或多个符号的序列。这意味着,一个符号的替换可以依赖于它周围的上下文。例如,“她 + 吃 + 苹果”中的“吃”可以在不同的上下文中被替换为不同的形式,比如在过去时的上下文中,它可能被替换为“吃过”。
最后,变换(transformation)是指在生成规则的基础上,对句子进行某种改变的操作。例如,我们可以有一个变换规则,将被动语态的句子转换为主动语态,或者将肯定句转换为否定句。
所以,整体来看,由上下文敏感的生成规则和变换定义的语法是一种描述语言结构的方法,它可以捕捉到语言的复杂性,包括词语在不同上下文中的不同形式,以及句子的不同变换形式。
-
转换: 在语法中,有一些规则可以将一种句子结构转换为另一种。
-
-
上下文无关文法(Context Free Grammars,CFG),描述语言的结构
-

-
一个上下文无关文法由一组产生式规则(Production Rules)构成,这些规则描述了如何生成语言中的句子。规则的形式通常为 A → B,意味着我们可以将A替换为B。
-
在上下文无关文法中,每个产生式规则只关心当前的非终结符(non-terminal symbol,也就是A),而不关心这个非终结符周围的上下文。这就是为什么它被称为“上下文无关”的原因。而非终结符可以被看作是语法结构的部分,比如句子,短语等,终结符则是具体的词语或者标点符号。
-
假设我们有一个非常简单的自然语言语法,它只包括两个规则:
- 句子 → 名词短语 + 动词短语
- 名词短语 → 冠词 + 名词
我们还有一些名词(例如"猫"和"狗"),动词(例如"跑"和"跳"),以及冠词(例如"一个"和"那个")。
根据这个上下文无关文法,我们可以生成很多符合规则的句子。比如,我们首先使用规则1生成一个句子,得到 “名词短语 + 动词短语”,然后我们可以使用规则2替换名词短语,得到 “冠词 + 名词 + 动词短语”。最后,我们用具体的词替换掉非终结符,得到 “一个猫跑”,这就是一个符合我们定义的上下文无关文法的句子。
在这个例子中,无论我们在哪里看到 “名词短语” 或者 “句子”,我们都可以应用相应的规则进行替换,我们不需要考虑这些非终结符的上下文,这就是为什么这种文法被称为"上下文无关"的原因。
需要注意的是,这只是一个非常简化的例子,实际的自然语言的语法要复杂得多,而且有很多特例和例外。
-
-
区别:
- 上下文无关文法:这种文法的产生式规则的形式是 “A → B”,其中 A 是一个非终结符,B 是一个由非终结符和终结符组成的序列。在这种规则中,我们只关心当前的非终结符 A,而不关心它在句子中的位置或者周围的上下文。也就是说,无论 A 在哪里出现,我们都可以将其替换为 B。上下文无关文法在描述语言结构时比较简单,但也有一定的限制。
- 上下文敏感文法:这种文法的产生式规则的形式是 “ABC → AxB”,其中 A, B, C 可以是非终结符或者终结符,x 是一个由非终结符和终结符组成的序列。在这种规则中,非终结符 B 的替换是依赖于其周围的上下文 A 和 C 的。也就是说,只有当 B 周围的上下文是 A 和 C 时,我们才能将其替换为 x。上下文敏感文法在描述语言结构时更加灵活,但也更加复杂。
-
语义映射: 我们可以将语法规则映射到语义函数,这样我们就能理解句子的意义。
-
终结符是指涉物或者功能: 在语法中,终结符(terminal symbols)是那些实际的词语或者短语,它们可以表示某种特定的意义或者在句子中发挥某种作用。
-
一个环境是(用现代术语来说)一个语义网络的复杂相互关系: 在语义分析中,环境(environment)可以被看作是一系列语义元素(例如词语或者概念)之间的关系网络。
-
意义是有组合性的,表现为语义函数: 意义不是孤立存在的,而是由多个部分组合而成的。这些部分的组合方式就是语义函数。
-
-
大的剩余问题:如何在“真实世界”中表示意义? 这是自然语言处理面临的一大挑战:我们如何将抽象的语义表示方法应用到真实世界的语言中去?
-
语法关系: 两个phrase之间的句法关系,比如单词如何组织等等。这部分展示了如何使用语法规则去解析句子的结构。
-
映射到意义: 将phrase mapping 到meaning。这部分展示了如何使用语义映射将语法结构转换为实际的意义。
-
语义关系: 在map到meaning后,就是比较两个meaning之间的意义关系了。这部分展示了如何理解句子的意义,并且找出句子中各个部分的关系。
-
Term spotting + handling negation, uncertainty
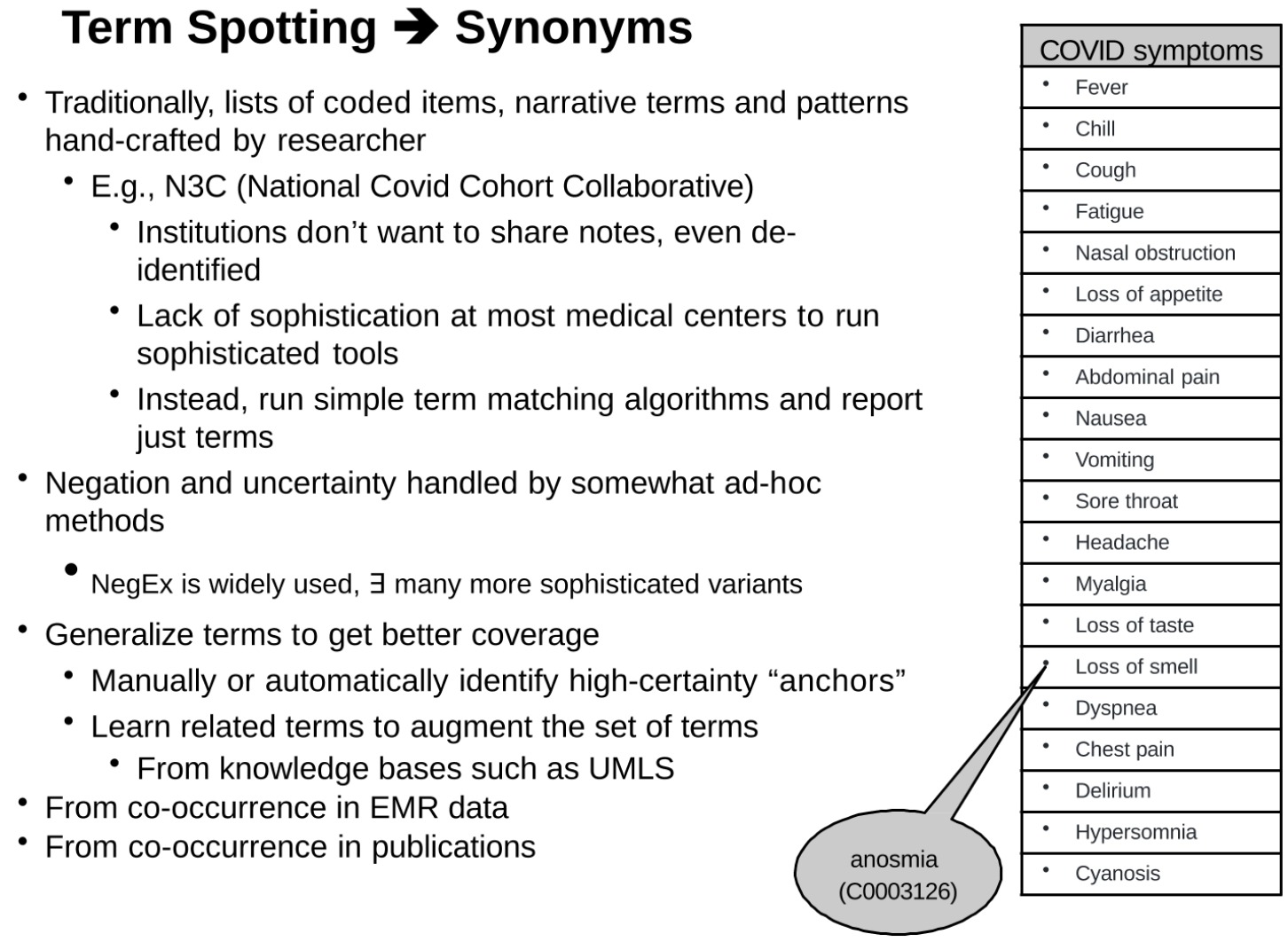
处理临床文本中对于COVID症状的检测和处理的一种方法,包括词条(Term)识别,同义词的处理,以及对否定和不确定性的处理
-
这段内容看起来是描述在处理临床文本中对于COVID症状的检测和处理的一种方法,包括词条(Term)识别,同义词的处理,以及对否定和不确定性的处理。
-
传统上,研究者手工创建编码项,叙述词条和模式的列表。
- 例如:发热,寒冷,咳嗽,疲劳,鼻塞,食欲不振,腹泻,腹痛,恶心,呕吐,喉咙痛,头痛,肌肉痛,味觉丧失,嗅觉丧失,呼吸困难,胸痛,精神错乱,嗜睡,紫绀。
- 例如,N3C(全国Covid病例合作)
- 许多机构不愿分享记录,即使是去除身份信息的记录。
- 大部分医疗中心缺乏运行复杂工具的技术精密度。
- 相反,他们运行简单的词条匹配算法并报告,仅仅是词条。
- 由此带来的问题:否定和不确定性通过相对专断的方法处理。因为只有词条,没有其他语义词(比如否定)
- NegEx被广泛使用,还有许多更复杂的变体。
- 目标:通过词条泛化获得更好的覆盖率。
- 手动或自动识别高确定性的“锚”。
- 学习相关词条以扩充词条集。
- 从如UMLS这样的知识库中得出。
- 从EMR数据的共现中得出。
- 从公开发表的文献中共现得出。
这段内容强调的是,词条匹配对于理解临床文本非常重要,但是在许多情况下,这些匹配需要考虑更多的上下文信息,包括同义词,否定,以及不确定性。这些复杂的因素使得从临床文本中提取有用信息变得更加困难,但也提供了对更复杂和更有效工具的需求。

这里快速过一下就行:
这部分内容介绍了在处理临床文本时,如何处理否定词(Negation)和识别否定表达(NegEx)。
首先,识别病情相关的否定,涉及到识别一种陈述,该陈述描述了一个人的临床状况,并确定该陈述在文本中是否被否定或反驳。
其次,介绍了四组不同的对比实验,分别基于是否包含NegEx否定短语的句子,以及是否包含否定词。这些实验对比了敏感度(Sensitivity)、特异性(Specificity)、阳性预测值(Positive Predictive Value,PPV)和阴性预测值(Negative Predictive Value,NPV)。
然后,这部分内容指出,在自然语言处理(NLP)中处理否定的问题通常比较复杂,但在这个情况下,否定主要应用于指示疾病、测试、药物、发现等名词短语,所以问题相对简单些。
在具体操作上,寻找所有出现在出院总结每个句子中的UMLS(统一医学语言系统)术语,找出是否有否定短语出现在这些术语之前。例如,“no”、“denies” “not”、 “without”,“n’t”,“ruled out”,“denied"等,如果有,这些表述就被识别为否定表达。
另外,一些词语或短语可能会误导识别,如"gram negative"、“no further”、“not able to be”、“not certain if”、“not certain whether”、“not necessarily”、“not rule out”、“without any further”、“without difficulty”、“without further”,这些短语虽然含有否定词,但在上下文中并不代表否定的意思,所以需要特别注意。
这部分内容最后引用了一篇关于在出院总结中识别否定发现和疾病的简单算法的论文,这表明以上介绍的内容的来源和依据。
ML to expand terms
数十年来人们花了大量的时间去做这些语义相关的工作,建立短语间的等级结构。比如统一医学语言系统(Unified Medical Language Systems,UMLS)。这些是NLP的基础

UMLS的核心部分是元词库(Metathesaurus),到2022年ab版本,元词库已经包含了182种源词汇(原来有215种,但一些过时的被去掉了)。这些源词汇包括医学主题词(MeSH)、SNOMED、ICD-9、ICD-10、LOINC、RXNORM、NCI、CPT、GO、DXPLAIN、OMIM等。
元词库提供了跨词汇的同义词映射,例如“heart attack"(心脏病发作)和"acute myocardial infarct"(急性心肌梗死)以及"myocardial infarction"(心肌梗塞)是同义词。
元词库包含了4662313个独特的概念,每个概念都由一个唯一的概念标识符(CUI)表示。元词库实质上是从每个源头提取的所有层次结构的混合汇编。
此外,除了使用同义词之外,还可以利用其他相关词汇,如上下义词以及其他关联词。例如,一种疾病的常见症状或治疗方法。这也是一个递归的机器学习问题:学习如何最好地识别与一个术语相关的案例,这个过程被称为“表型鉴定”(phenotyping)。
最后,"Anchor & Learn"这样的方法可以从医疗记录中学习次要术语。

对于医学文本中的术语,尤其是缩略词,有很多挑战。首先,许多缩略词都是模棱两可的,这就大大增加了理解和解释的复杂性。比如,MAC可以代表"minimum alveolar anesthetic concentration",PCA可以代表"procoagulant activity",CML可以代表"carboxymethyllysine",IPA可以代表"n-6-(delta-2-isopentenyl) adenine"。一个缩略词可能有多个不同的含义,而这些含义在不同的上下文中会有不同的解释。
这部分内容中的研究表明,在Medline(Pubmed)摘要中,81.2%的三个字母的缩略词是有歧义的,平均有16.6种含义。如果忽略罕见的(出现次数少于5次)含义,仍然有64.6%的缩略词是有歧义的,平均有4.91种含义。这显示出一种"长尾"分布,即大部分缩略词都有少数几种常见的含义,但也有许多缩略词有大量的罕见含义。
此外,82.8%的出现次数超过100次的缩略词在UMLS(统一医学语言系统)中可以找到,但所有的缩略词只有23.5%在UMLS中可以找到。这说明了现有的医学语言资源并不能涵盖所有的医学术语,尤其是罕见和特定领域的术语。
为了解决这些问题,可以使用机器学习来扩展术语。这可能包括使用一种称为MetaMap的工具,该工具使用启发式方法来识别文本中的医学概念,以及链接到UMLS中的相关概念。通过机器学习的方法,我们可以更好地理解术语的上下文含义,从而减少歧义,并可能发现新的术语和含义。
pre-NN ML to identify entities and relations

在建立基于特征的模型时,我们可以从文本中提取各种特征。这些特征可能包括:
- 单词:文本中的各个单词。
- 词性:每个单词的语法类别,如名词、动词、形容词等。
- 大小写:单词的大小写情况,这可能在识别专有名词或句子的开始时很重要。
- 标点符号:文本中的标点符号,如逗号、句号等。
- 文档章节:文本的结构信息,如段落、标题等。
- 传统的文档结构:如摘要、引言、方法、结果、讨论等部分的存在和顺序。
- 识别的模式和词典术语:在文本中识别的预定义模式和词典中的术语。
- 词汇上下文:目标单词周围的单词以及它们的特性。
- 语法上下文:与目标单词语法上有关的单词及其特性。
例如,“The lasix, started yesterday, reduced ascites.”这个句子中,"lasix"和"ascites"都是名词,"started"和"reduced"都是过去时态的动词,"yesterday"是副词。这些信息可以用于构建一个更复杂的特征模型,有助于理解和解析医学文本。
Latent Dirichlet Allocation (LDA)
更现代的方法叫作LDA

潜在狄利克雷分配(LDA,Latent Dirichlet Allocation)是一种常用的主题模型技术。其基本概念如下:
-
每个文档是多个主题的混合体:在LDA模型中,我们假设每篇文档都由多个主题组成,而这些主题的比例可以是不同的。比如,一篇关于健康饮食的文章可能由“营养”、“健康”和“食物”这三个主题组成。
-
每个主题是词语的分布:在给定主题的情况下,每个词出现的可能性不同。例如,“营养”主题中,“维生素”、“蔬菜”、“蛋白质”等词可能更常见。
-
每个词是从一个主题抽取出来的:在文档中,每个词都是从其中的一个主题中抽取出来的。抽取的主题是基于该文档主题的比例分布来选择的。
在应用LDA进行文本分析时,我们通常需要确定的参数是主题数,也就是我们想要在文档集中发现的主题的数量。然后,LDA算法会自动发现每个主题的词语分布以及每个文档的主题分布。

在文本文档中发现隐藏的主题结构。该模型假设每个文档是由一组主题的混合生成的,而每个主题又是词语的概率分布。
在LDA的框架下,我们假设每个文档的主题分布是由狄利克雷分布生成的,而每个主题的词分布也是由狄利克雷分布生成的。然后,对于文档中的每个词,我们首先从文档的主题分布中抽取一个主题,然后从该主题的词分布中抽取一个词。这个过程生成了文档中的所有词。
在这个模型中,我们只能观察到词(即文档中的词),而所有其他的东西,如主题分布、词分布和每个词的主题分配,都是隐藏的,我们需要使用推理算法(如吉布斯采样或变分推理)来推断出这些隐藏的变量。
以下是这个图模型中各个符号的含义:
- D:文档的数量。
- K:主题的数量。
- N:每个文档中的词的数量。
- α,β:这是狄利克雷分布的参数,它们决定了主题分布和词分布的形状。
- θ:这是每个文档的主题分布。
- φ:这是每个主题的词分布。
- z:这是每个词的主题分配。
- w:这是观察到的词。
这个模型的目标是,给定观察到的词,推断出所有的隐藏变量,即每个文档的主题分布、每个主题的词分布和每个词的主题分配。
W d , n W_{d,n} Wd,n是在特定文档中观察到的第n个词, Z d , n Z_{d,n} Zd,n是这个词的主题分配,N框起来的属于是单词。
而D框起来的是文档级别, θ θ θ 是这个文档的主题分布(比如这个文档有20个关于计算机、60个关于生物、20个关于神经科学的主题)。
α α α是参数,在所有的语料库中学习,属于是对文件的期望(一种先验概率),表示特定主题在文档中被采样的概率。
现在我们从左往右看
先是一个先验概率Proportions parameter,影响了生成的主题分布的形状。然后确定后,就可以生成每个文档的主题分布。(这个分布描述了在生成该文档时,我们选择每个主题的概率。例如,如果一个文档的主题分布是 [0.1, 0.2, 0.7],这意味着生成这个文档时,我们选择第一个主题的概率是 0.1,选择第二个主题的概率是 0.2,选择第三个主题的概率是 0.7。)
Per-word topic assignment(每个词的主题分配):在生成每个词之前,我们需要首先确定这个词的主题。这是通过从当前文档的主题分布中抽样得到的。例如,如果我们抽样得到的主题是第三个主题,那么我们将会从第三个主题的词分布中抽样生成这个词。
Observed word(观察到的词):在确定了每个词的主题之后,我们就可以生成这个词了。这是通过从这个词的主题的词分布中抽样得到的。这个词分布描述了在生成词时,我们选择每个词的概率。这就完成了生成文档的过程,我们观察到的就是这些生成的词。
总的来说,这个过程从生成文档的主题分布开始,然后对于文档中的每个词,首先确定它的主题,然后生成这个词。这是一个层级的过程,上一层的输出成为了下一层的输入,最终生成了我们观察到的词。
从右往左看
- 主题参数(Topic parameters):首先,我们为每个主题选择一个词的分布。这个分布定义了在给定的主题下,每个词出现的概率。
- 主题(Topics):然后,对于一个给定的文档,我们会选择一个主题的分布。这个分布定义了在该文档中,每个主题出现的概率。
- 观察到的词(Observed words):最后,对于文档中的每个词,我们首先从文档的主题分布中选择一个主题,然后从该主题的词分布中选择一个词。
两个方向貌似是等价的,一个是文档->文档的主题->词语,一个是主题->词。
两个方向都可以反向学习,就是从给定观察到的词的情况下,我们想要推断出潜在的主题分布和主题参数的过程。这种过程通常需要使用一些推理或优化算法,如吉布斯采样或变分贝叶斯方法。
Statistical Models of Language: Zipf’s law

词语是存在一个幂律分布的,不同单词的频率呈指数衰减。
-
N-gram models
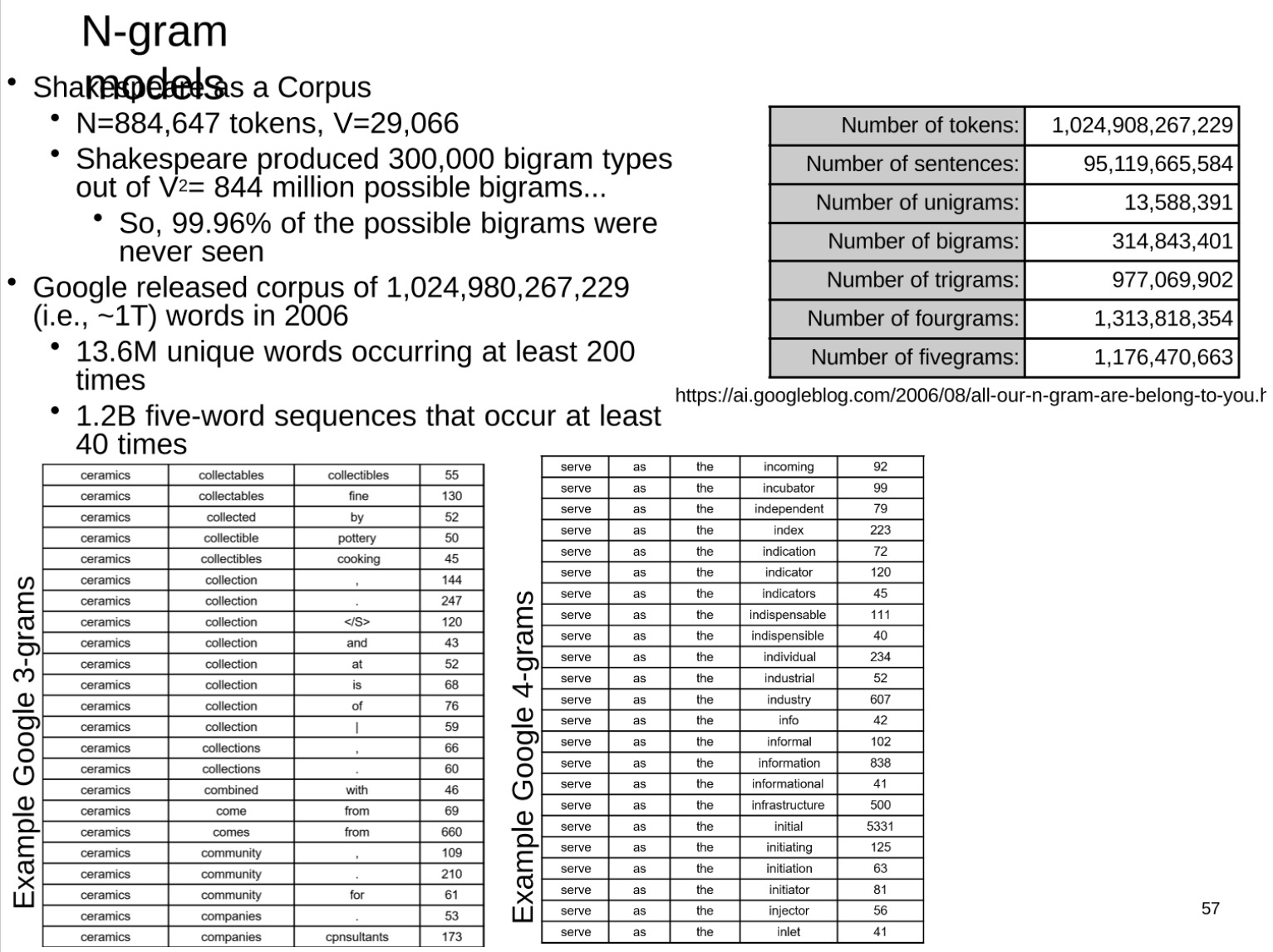
-
bigram是成对的词对
-
这一部分内容描述了N-gram模型在大语料库中的实际应用,以及该模型的一些限制。N-gram模型是一种统计语言模型,它假设一个词的出现只与前面N-1个词相关。对于大规模语料库,我们可以使用N-gram模型来统计词序列的频率。
这段内容中首先提到莎士比亚的作品,莎士比亚在他的作品中产生了30万种不同的二元组(bigram)类型,从理论上讲,可能的二元组数量是词汇量的平方,即844万种。但是实际上,莎士比亚作品中99.96%的可能二元组从未出现过。这体现了语言的实际使用中,词序列的分布是非常不均匀的。
接着,这段内容引用了Google在2006年发布的一个包含1.03万亿个词的语料库。这个语料库包含了1360万个至少出现200次的唯一单词,以及11.7亿个至少出现40次的五元组(five-gram)。这种大规模的N-gram语料库可以用来训练和评估各种语言模型。
然而,需要注意的是,N-gram模型也有其局限性。它无法很好地处理长距离的词间依赖关系,同时也会遇到数据稀疏问题,即很多可能的N-gram在实际语料库中并没有出现。这就需要一些平滑技术来处理这种情况,或者使用更复杂的模型如神经网络语言模型来捕捉复杂的词间关系。

这部分内容介绍了如何使用N-gram模型来生成序列或者句子。这种方法通常被归功于信息论的创始人克劳德·香农。具体的操作如下:
- 首先,根据其概率随机选择一个以句子开始符号
为前缀的二元组(s>, w)。 - 然后,根据其概率随机选择一个二元组(w, x),其中前缀w与第一个二元组的后缀匹配。
- 以此类推,不断随机选择新的二元组,前缀与上一个二元组的后缀匹配,直到我们随机选择到一个以句子结束符号为后缀的二元组(y, )。
- 最后,将这些二元组中的词串联起来,形成一个句子。
这种生成序列的方式可以模拟原始语料库中的句子风格,但是需要注意的是,由于这种方法完全依赖于概率选择,所以生成的句子可能在语义上并不完全连贯,只是在形式上模仿了原始语料库的风格。
- 莎士比亚的文章生成内容,可以看到,按多元组的形式(n-gram),n越大,生成的效果相对越好
vector space embeddings based on co-occurrence
接下来的内容才算是进入正题,进入了当今最火的大语言模型的内容,前面讲的都是传统的一些方法,
Modern-day NLP: Actually modeling language: LLMs

-
核心观点
- 只要模型是可微的,我们就可以构建任意复杂的模型。然后,我们可以通过随机梯度下降方法进行训练。
- 我们可以在任意大的未标注语料库上进行预训练,然后通过微调或甚至少样本学习进行适应。
-
预训练任务通常是预测给定之前的**词元(token)**后的下一个词元。
- 在单词模型中,词元的概率仅从语料库中的频率进行估计。
-
马尔可夫假设简化了模型,使得给定前面的内容后的词元概率等于给定前一个词元后的词元概率(二元模型),或者给定前n个词元后的词元概率(n元模型)。
-
困惑度(Perplexity)是对语料库复杂度的总体度量。
- 其中H§是概率分布的熵,直观地说,困惑度是继续文本的可能方式的数量。困惑度为k意味着你的平均惊讶程度就如同在每一步都需要在k个等可能的选择中进行猜测。
- 例如,我们比较了口述医生笔记的困惑度(8.8)与医生-患者对话的困惑度(73.1)。这告诉我们在这些应用中准确转录语音的难度。
简单解释一下预训练:
预训练(pre-training)是深度学习中的一个重要概念,其核心思想是先在大量的未标注数据上进行训练,学习到一种通用的语言表示,然后再在特定的任务上进行微调(fine-tuning)。
我来举个简单的例子:
假设你正在学习法语,但你的老师只会给你提供一小部分的练习题(这就是我们的标注数据,即每个例子都有正确答案)。但是你还有一整个法语的图书馆可以自由阅读(这就是未标注数据,即大量的法语书籍,但是没有答案或解释)。
预训练的过程,就好比你首先花了很多时间在图书馆里阅读各种各样的书,尽管没有老师在旁边指导,但是通过大量的阅读,你对法语的单词、语法和语境有了深入的了解和感觉。这个过程就像神经网络在大量未标注数据上进行预训练,学习到一种对语言的通用表示。
然后,当你回到老师那里,做那些有标注的练习题时,你已经有了丰富的背景知识和语言感,因此你可以更准确地完成这些练习题。这个过程就像神经网络在具体任务(如文本分类、命名实体识别等)上的微调,利用预训练得到的知识,来提高特定任务的性能。
在自然语言处理中,预训练和微调的策略已经被证明是非常有效的,因为在现实世界中,我们往往有大量的未标注数据(如网页、书籍等),但只有少量的标注数据。通过预训练和微调,我们可以更好地利用这两种资源,提高模型的性能。

实现以上的工作的重要基础就是embedding,将词语映射到一个所谓的语义空间里面,在这里一个词语用一个空间中的向量表示。(在这里,意义相近的单词距离就比较近)
这段内容是关于**分布式语义学(Distributional Semantics)**的。这个实现看起来非常的复杂(实际上也确实是),但是它的key idea很简单。其主要理念是,出现在相同上下文中的词语可能在语义上有关联(好好品一下这个话,我们通过context来推算词之间的相似性,而不是像以前那样hard-code 硬编码来表示词的意思,仅仅是关注这些词跟它上下文的哪些词同时出现)。
这种关联被通过高维向量(嵌入空间)表示,每个词语都会映射到这个高维空间中的某个点。
图中列举了几种具有代表性的词嵌入模型(更复杂的,等同于矩阵分解),包括word2vec,GloVe,Elmo,Bert和GPT,这些模型都是利用分布式语义学的理念,通过学习大量的未标注文本数据,为每个词语生成一个高维向量(也就是词嵌入)。这些词嵌入可以捕获词语的语义信息,如语义相似性,语义关系等。
- word2vec:通过预测词语的上下文(或由上下文预测词语)来生成词嵌入。
- GloVe(Global Vectors for Word Representation):基于词语的共现统计生成词嵌入。
- Elmo(Embeddings from Language Models):利用双向语言模型生成上下文敏感的词嵌入。
- Bert(Bidirectional Encoder Representations from Transformers):使用Transformer架构的双向语言模型生成上下文敏感的词嵌入。
- GPT(Generative Pretrained Transformer):使用Transformer架构的单向语言模型生成上下文敏感的词嵌入。
这些词嵌入模型的方法各有不同,但都是利用大量的未标注文本数据,通过学习词语的上下文信息,生成能够捕获词语语义的词嵌入。
补充:这个展示的图使用t-SNE来给这个高维空间降维了,所以就实现可视化。有了这个空间,我们就可以相互计算了,可以实现词语之间的转换

具体如何实现这个过程。这个过程真的很妙。就像是自编码器,编码器是一个embedding,输出就是语义空间中的坐标(相当于自编码器里的表征学习),解码器是复杂的神经网络,最后输出预测的token(可以是字母、词语、词语中的一部分等等)
这个过程包含编码(将词转换为向量表示,也称为词嵌入或表示学习)和解码(实际的预测)两部分。训练过程通过密集连接网络(Dense)和嵌入层(Embedding)来更新权重,采用反向传播(Backpropagation)方法进行优化。(注意:这里反向传播修改的不止是神经网络、还包括embedding的设置)
最初,词嵌入是分散的,但经过训练后,具有相似上下文的词会聚集在一起。为了增加上下文信息,可以使用多个连续的字符。随着训练的进行,预测能力会有所提升。
当我们从字符过渡到单词时,需要更大的上下文、更多的层和更高维度的表示,因为单词的语义和用法通常比单个字符更复
language models
语言模型这里不会写的很细,大概知道都是啥就行。给出了几个不错的视频链接,等我学完之后会再写一篇完整的博客并将博客链接放在这篇下面。
循环神经网络RNN
首先,先说明一下这些模型和词嵌入的关系
RNN(循环神经网络),LSTM(长短期记忆网络)和Transformer都是用来处理序列数据的模型,如文本或时间序列数据。它们都可以捕获序列中的模式,并对未来的序列元素进行预测。这些模型都可以用于生成词嵌入,也可以使用预先训练的词嵌入作为输入。
在生成词嵌入的任务中,这些模型可以学习将相似上下文的词映射到嵌入空间中相近的点。例如,word2vec模型就可以通过一个简单的两层神经网络(它实际上是一个非常基础的RNN)来训练。而更复杂的模型,如BERT或GPT,则使用了Transformer结构。
所以事实上,词的embedding可以直接从权威的官网上进行下载,在本地直接训练。也可以自己使用模型训练embedding,都是可以的。这两者的界限比较模糊。
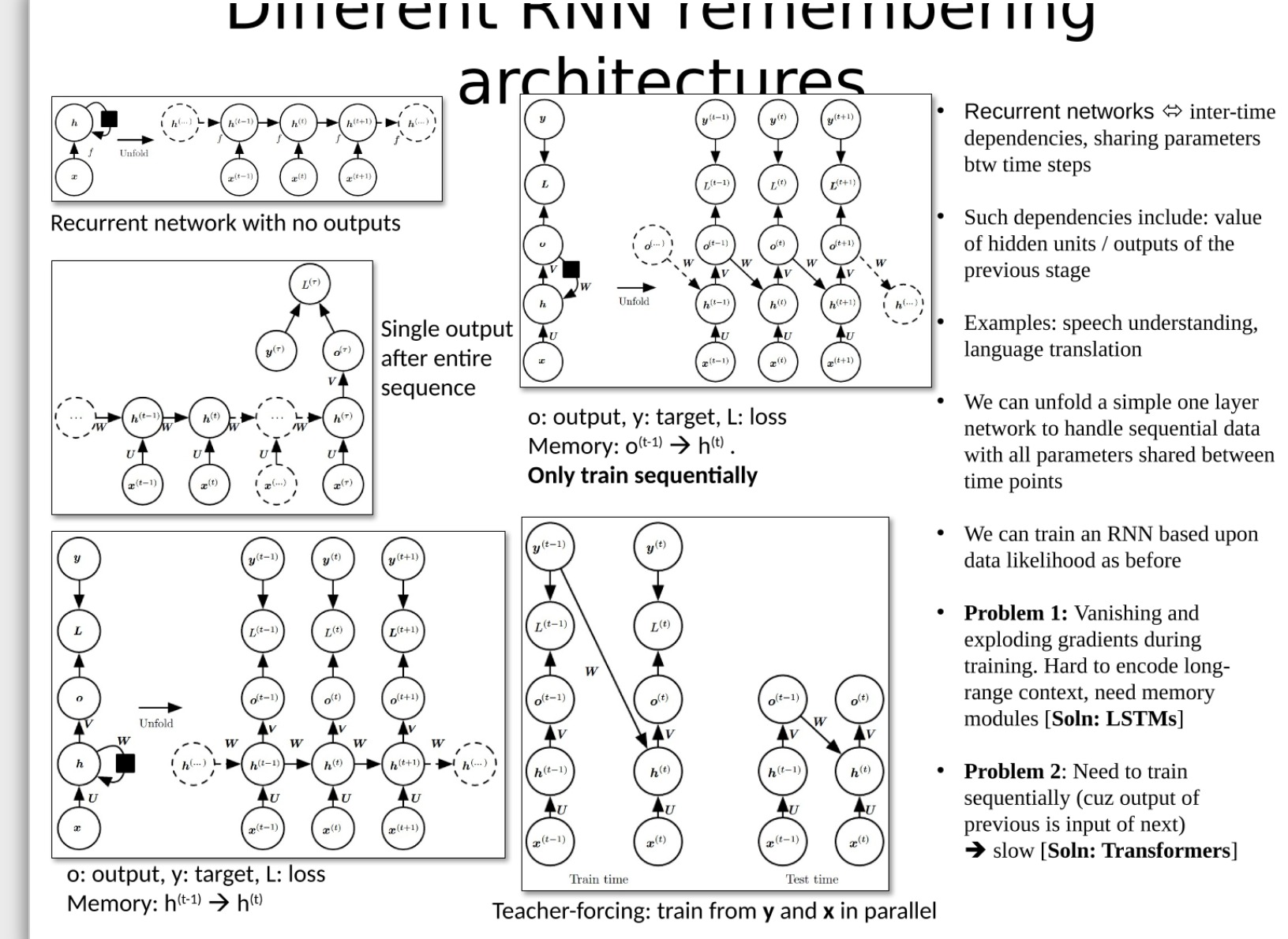
具体内容可以参考我以前写的博客:pytorch 神经网络笔记-RNN和LSTM,开头贴出了学习的视频链接,视频非常的好懂。
LSTM

推荐学习课程:李宏毅手撕LSTM
ELMo
(Contextual) Embeddings from Language Models

ELMo(Embeddings from Language Models)是一种深度学习模型,该模型通过训练语言模型来生成单词的词嵌入(即表示单词的向量)。这些词嵌入考虑了单词的上下文,从而提供了比传统的词嵌入(如Word2Vec或GloVe)更丰富的语义信息。
以下是ELMo的关键特点:
- 上下文词嵌入:不同于Word2Vec或GloVe等模型为每个词提供固定的词嵌入,ELMo为每个单词提供根据其上下文变化的嵌入。这意味着同一个单词在不同的句子中可能会有不同的词嵌入。例如,“play”在“Let’s play football”和“In a play written by Shakespeare”两个句子中的含义是不同的,因此它们的词嵌入也将不同。
- 双向LSTM:ELMo使用双向长短期记忆(LSTM)网络对文本进行建模。这种网络同时考虑了单词的前后文信息,从而生成更准确的上下文词嵌入。
- 预训练:ELMo是通过预训练的语言模型生成词嵌入的。这种预训练任务是无监督的,也就是说,它不需要标签数据。这种预训练语言模型的任务是预测给定其上下文的单词的下一个单词,这种任务需要大量的文本数据。
使用ELMo词嵌入的优点在于,预训练的模型可以捕获大量的语义信息,然后将这些信息用于各种自然语言处理(NLP)任务,如文本分类、实体识别和情感分析等。然而,ELMo模型的一个缺点是其计算成本相当高,需要大量的计算资源来训练和使用。
学习了LSTM后就可以学ELMO了,但是要先学习transformer后才可以学习GPT
学习课程:李宏毅-ELMO, BERT, GPT讲解
Transformer