为节省篇幅,不标注文章来源和文章的问题场景。大部分是我的通俗理解。
文章目录
- 向量关于向量的偏导数:雅可比矩阵
- 二阶导数矩阵:海森矩阵
- 随机变量
- 随机场
- 伽马函数
- beta分布
- 数学术语
- 坐标上升法
- 协方差
- 训练集,验证集,测试集,交叉验证
- 凸函数
- 学习曲线
- TF-IDF
- 分层聚类
- 万能近似定理,神经网络到底在干什么
- state-of-the-art,baseline,benchmark
- 知识
- 关系抽取
- 事件提取
- 误差累积
- 零样本学习
- 集成学习
- 敏感词审核
- 用于文本审查的神经网络算法
- 准确率,精确率,召回率,F-measure
- Inter-rater agreement Kappas
- RNN和LSTM
- hard-limit
- NLP的预训练
- 词嵌入中的K
- NLP输入数据处理
- 神经网络实现
- 特征提取
- LDA
- PCA
- CRF 条件随机场
- DL和NLP当年为什么不火
- 词袋bow
- n-gram
- 依存分析
- type dependency
- 情感分析
- 社交媒体文本分析
- wordnet
- 相对熵(KL散度),交叉熵,JS散度,Wasserstein推土机距离
- 浪潮起因
- 正则化项
- 欧拉公式
- 正弦波
- 傅里叶级数
- 傅里叶变换
- 傅里叶变换的应用
- 卷积
- fine tuning
- RELU/sigmoid/tanh
- 池化层,池化
- 卷积层,边缘探测
- channel 通道
- 欧氏空间、grid、结构化数据
- 特征分解和谱分解
- 图的拉普拉斯矩阵为什么叫拉普拉斯矩阵
- 高斯分布:最大熵?
- triplet loss
向量关于向量的偏导数:雅可比矩阵

二阶导数矩阵:海森矩阵
多元函数的二阶偏导数构成的方阵,对称。

随机变量
随机变量是样本点的函数。
随机场
一个例子是,平面上的每一个点都是一个随机变量。
随机场强调空间,跟随机过程一样,都是一系列随机变量的集合。
伽马函数
阶乘在实数集上的延拓。比如说,2.5!。推导过程只有两行,见百度百科。
beta分布
beta分布可以从二项分布推导。
以下图为例讲解吧,
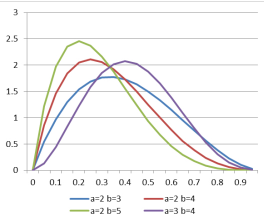
a+b可以理解为实验次数。如a=2,b=3,抛5次硬币,a=2表示5次中有两次朝上。如果硬币朝上的概率为0.3,那么可能性会较硬币朝上概率为0.8时大。此处的纵轴不表示概率(因为要保证概率归一,即曲线下面积为1),但可以体现出概率的相对大小。
至于狄利克雷分布,是beta分布的高维推广。
数学术语
- 算子是一个函数到另一个函数的映射,它是从向量空间到向量空间的映射
- 泛函是函数(向量空间)到数域的映射
- 函数是从数域到数域的映射
闭式解=解析解,即获得一个解函数,这个解函数有通用性,即能帮我们计算不同情况下的解。
与闭式解对应的,是数值解,可以认为是给定情况下能解出来一个足够精度的解,但换一种情况后之前的解就没用了。
配分函数partition function,所有状态的和,放在分母上就能起到归一作用。
坐标上升法
多元函数,求极值。每次固定n-1元,求自由元偏导,令偏导为0,就能得到一个自由元=f(固定元)的更新式。把所有更新式都求出来之后,开始迭代。
协方差
协方差经常也用来衡量两个随机变量之间的线性相关性。如果两个随机变量的协方差为0,那么称这两个随机变量是线性不相关。
两个随机变量之间没有线性相关性,并非表示它们之间是独立的,可能存在某种非线性的函数关系。反之,如果X与Y是统计独立的,那么它们之间的协方差一定为0。
协方差矩阵是在两个随机向量上讨论的。协方差矩阵中的元素,对应两个随机变量的协方差。
核函数,可以衡量两个样本之间的相似度。计算协方差矩阵时,有若干种核函数可以选择。
训练集,验证集,测试集,交叉验证
训练集,训练获得最佳参数。
验证集(强调调超参作用时,也有叫开发集的),调超参,如在神经网络中选择隐藏单元数、广义线性回归中的多项式次数、控制权值衰减的λi等。一般由专家经过经验或者实验选定。控制模型复杂程度(如果训练集准确率提升,而验证集准确率下降,说明过拟合,模型过于复杂,应该停手)。
测试集,测试泛化能力。
交叉验证,由于数据有限,划为k份之后,用多种分配方案来划分为三种集合。
凸函数
一阶导单调增,或者用两点连线在函数图像上方来判断。
损失函数必须是凸函数,以免梯度下降时陷入局部最优解。
学习曲线
偏差大,是欠拟合。方差大,是过拟合。
欠拟合,可以增加特征。减小正则项。提高模型复杂度。
过拟合,可以减少特征。扩大数据集。增大正则项。降低模型复杂度。
TF-IDF
用于关键字提取。
字词在文件中出现次数越多,则越重要;
字词在文件集中出现次数越多,则越不重要。
TF,term frequency,定义为出现次数/文章词数
IDF,inverse document frequency,定义为log(总文章数/出现文章数)。
分层聚类
自底向上,先定义距离,每次将距离最小的类合并。
定义一个最大最小值,如果相距最近的类的距离大于它,就停止聚类。决定了是将层分得细一点还是粗一点。
可见,效果取决于距离的定义,和最大最小值的设置。
万能近似定理,神经网络到底在干什么
译自universal approximation theorem。
https://blog.csdn.net/guoyunfei20/article/details/78288271
万能近似定理意味着无论我们试图学习什么函数,我们知道一个大的MLP(多层感知机)一定能够表示这个函数。
两层的前馈神经网络可以拟合任意有界闭集上的任意连续函数。
这也解释了神经网络在“学什么”,就是在学一个函数。
这个函数的作用是,把输入的低维特征,变成更加抽象的高维特征。
基本的深度学习相当于函数逼近问题,即函数或曲面的拟合,所不同的是,这里用作基函数的是非线性的神经网络函数,而原来数学中用的则是多项式、三角多项式、B-spline、一般spline以及小波函数等的线性组合。
由于神经网络的非线性和复杂性(要用许多结构参数和连接权值来描述),它有更强的表达能力,即从给定的神经网络函数族中可能找到对特定数据集拟合得更好的神经网络。这相信正是深度学习方法能得到一系列很好结果的重要原因。直观上很清楚,当你有更多的选择时,你有可能选出更好的选择。当然,要从非常非常多的选择中找到那个更好的选择并不容易。
state-of-the-art,baseline,benchmark
表示“目前最好的”。比如state-of-the-art model,就是“目前领域内最好的模型”。
偶尔会用SOTA 来简写 state-of-the-art。
“举个例子,NLP任务中BERT是目前的SOTA,你有idea可以超过BERT。那在论文中的实验部分你的方法需要比较的baseline就是BERT,而需要比较的benchmark就是BERT具体的各项指标。”(知乎 许力文 MorrisXu)
知识
什么是知识,知识是非结构/半结构化数据经过处理后得到的结构化数据,比如下面提到的,关系抽取中的关系三元组,以及事件提取中的事件描述表格。相较文本,提炼出的结构化的表格更容易查询,体积也更小。
从文本中获取知识,有两个重要的步骤,关系提取和事件提取。
关系抽取
https://blog.csdn.net/mch2869253130/article/details/117199565 (提到了一些经典论文)
关系抽取主要做两件事:
- 识别文本中的subject和object(实体识别任务)
- 判断这两个实体属于哪种关系(关系分类)
全监督关系抽取任务并没有实体识别这一子任务,因为数据集中已经标出了subject实体和object实体分别是什么,所以全监督的关系抽取任务更像是做分类任务。模型的主体结构都是特征提取器+关系分类器。特征提取器比如CNN,LSTM,GNN,Transformer和BERT等。关系分类器用简单的线性层+softmax即可。
相对全监督,也有半监督。基础是距离监督假设:如果知识库中的实体对之间存在关系,那么每个包含该实体对的文档都会表达该关系。这个假设太强,因此提出多示例学习和多种降噪方法。
关系提取,是为了获得(主体,关系,客体)的三元组。关系提取的发展,先是全监督,全监督的问题主要是数据标注不足,于是提出半监督,半监督的主要问题是假设太强、噪声太大,更前沿的研究聚焦于如何弱化假设和降噪。深度学习可以用于全监督关系提取。
事件提取
指定schema(感兴趣的类型,事件触发词、要素(如时间地点人物)),然后判断类型、提取要素,从而将文本变成表格。
事件提取,识别特定类型的事件,并把事件中担任既定角色的要素找出来。比如说,识别“企业成立”这一事件,需要靠事件触发词“成立”“创办”,需要提取出时间、地点、人物、注册资金等要素。传统上需要外部NLP工具(如依存分析、句法分析、词性标注),有时还需要人工设计特征。使用深度学习进行事件提取则可以减少对外部NLP工具的依赖,并自动提取特征。
误差累积
一个常见的老大难问题(如果没啥可说的,可以提一下。不过也确实有针对这个问题的工作。)
所有的pipeline式的方法都会有这个问题。简单来说,如果前面的步骤错了,后面的步骤只会是错上加错。
相应的,有joint式的方法。中文可分别译作流水线模型和联合模型。
零样本学习
属于迁移学习。利用类别的高维语义特征(有尾巴、有条纹,标签空间)代替样本的低维特征(图像特征,特征空间),使得训练出来的模型具有迁移性。
低维升高维很类似接近人类的思考过程,感觉是人类比能力的基础。
传统上,模型需要某类型足够多的数据,才能足够了解一个类,才能判断新物体是否属于这个类。
最初,令输入都是未知类(即测试集与训练集没有交集)。但实用价值有限。后来发展,输入中可以有已知类也可以有未知类。
集成学习
思路是博采众长。
按学习器的种类,可以分为同质和异质。
按学习器间的依赖关系,可以分为串行和并行。
同质常用的模型是cart决策树和神经网络。
串行的代表是boosting,使前面学习器误差率高的样本,会获得更大的权重。
并行的代表是bagging。随机森林使bagging的特殊情况,其学习器都是决策树。
除了学习器的种类和依赖,还需要考虑如何结合。可以用平均法、投票法、学习法。
学习法是指,用多个初学习器的输出,作为次学习器的输入。
敏感词审核
一般使用DFA算法。
用于文本审查的神经网络算法
考虑到对上下文关联的分析,神经网络采取LSTM long short-term memory。
LSTM是RNN recurrent neural network的特殊类型,利用RNN上下层的动态相关性,学习长期依赖信息,
因此LSTM对文本中的上下文关系有较好的理解。
TextCNN是利用CNN来处理文本分类任务,它利用CNN捕捉局部相关性的特点,来提取句子中的关键信息,从而进一步进行文本样本的特征提取,实现更准确的分类。CNN+LSTM的模型是结合CNN和LSTM网络,先使用CNN做局部特征提取,再用LSTM提取上下文关联信息。
准确率,精确率,召回率,F-measure
机器学习性能评估的参数(来自知乎答主Charles Xiao)
假设我们手上有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
TP: 将正类预测为正类数 40
FN: 将正类预测为负类数 20
FP: 将负类预测为正类数 10
TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%,
召回率(recall) = TP/(TP+FN) = 2/3,
F-measure是精确率和召回率的调和平均。
应用场景,
准确率不适合样本不均衡的情况,假如有90%的正样本,那么常数函数也能有90%的准确率。
精确率也叫查准率。当你说它为正的时候,我有多大把握相信你。
召回率适合只关心一类样本的情况,比如网贷违约,宁可误报也不能漏报。召回率也叫查全率。你找出了多少正类。
PR曲线指的是precision和recall,很难两全。
至于ROC,可以解决样本不均衡的情况,它考虑的是正查准率和1-负查准率。
Inter-rater agreement Kappas
inter-rater agreement,评分者之间的共识。
可以从侧面反映人工标注的质量。Kappas越高,说明评分者越一致。
RNN和LSTM
下面这个链接,是我目前看到的讲得最清楚的。
https://zhuanlan.zhihu.com/p/40119926
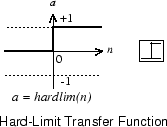
hard-limit
NLP的预训练
在互联网上有一些基于海量语料(例如中文维基百科等)的预训练词向量。但是一方面由于词库过于庞大,势必要用更多维数去表示,词向量就会更加冗长和稀疏;另一方面,某些词在特定场景具有特指的含义。因此,有时通用的预训练词向量不适合直接拿来使用,而应基于场景问题域本身的语料重新进行词向量训练。
词嵌入中的K
词向量的维数K是一个超参数。K的取值与语料内包含的不同词汇个数相关,可依据经验或由封装函数进行优化设置。
NLP输入数据处理
输入的维数要相同,而句子包含的词数不同。一种方法是截断和补齐。
神经网络实现
keras的封装程度比tensorflow更高,tensorflow比pytorch的封装程度更高。
特征提取
相比之前提到的关系提取和事件提取,特征提取的应用更加广泛。分类、聚类都可能用到。
一是对原始数据进行某种变换;二是在变换的过程中使不同的类别(或不同样本)具有相对较好的区分性。
效果上,对原始数据进行了提炼和加工。一般来说,特征提取的特征维数会低于原始特征,体积会大大缩小。
主成分分析(Principal components analysis,PCA)与线性鉴别分析(Linear Discriminant Analysis,LDA)最为经典。
LDA
Linear Discriminant Analysis和Quadratic Discriminant Analysis并列。
LDA会将k维数据投影到k-1维的超平面,因此也具有demension reduction的作用。不同于PCA会选择数据变化最大的方向,LDA会主要以类别为思考因素,使得投影后的样本尽可能可分。
使得相同类别在该超平面上的投影之间的距离尽可能近,同时不同类别的投影之间的距离尽可能远,在LDA中,我们假设每一个类别的数据服从高斯分布,且具有相同协方差矩阵。
Quadratic Discriminant Analysis类似于LDA,不同的地方是它可以形成非线性的边界,并且不同的类所属的高斯分布具有不同的协方差矩阵。
思想和triplet loss有点像,都是最小化类内间距 ,最大化类间间距。
PCA
经典的降维方法。
会产生一些新特性,新特性可以是旧特性的线性组合。从而可以用更少的维数、很少的信息损失来描述物件。
方差,其实就是辨识度的代名词。我们寻找最有辨识度的特征,就是寻找一种测度,使样本之间的方差最大。
误差,其实就是信息损失的代名词。我们希望降维过后仍能“重建”原始数据。
看下图,想象原点固定、旋转的平面坐标系。什么时候样本的方差最大?
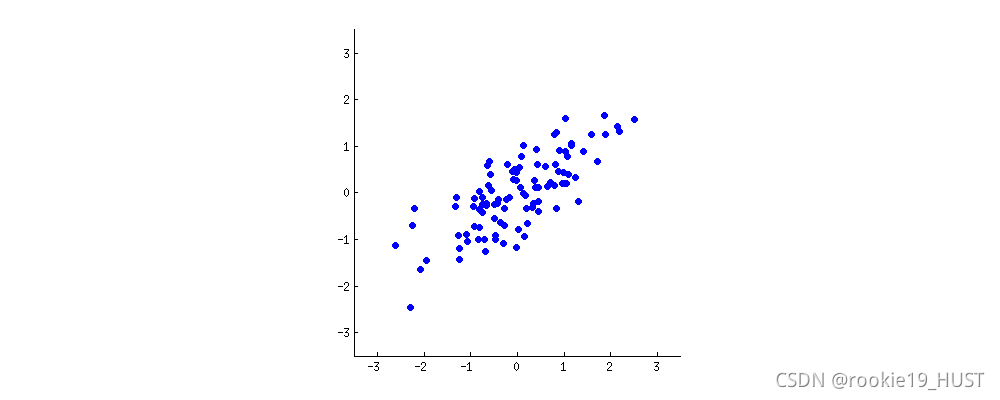
旋转的过程,就是将旧的两个指标进行不同比例线性组合的过程。基就是指标,就是测度。
达到最大方差的同时,也达到了最小误差。
方差是投影点到投影线中心的距离(的平方),误差是原点到投影点的距离(的平方),其和始终为原点到投影线中心的距离(勾股定理)。所以最大方差,最小误差会同时达到。
至于为什么要投影,投影其实就是降维了。
从上面的例子也可以看出,PCA可以合并原始特征中线性相关的特征。至于非线性相关,可以了解一下kernel PCA。
关于PCA更严谨的原理,需要了解协方差矩阵和奇异值分解。
CRF 条件随机场
随机场,场中有若干位置,按分布给位置赋值,则为随机场。
马尔科夫随机场,每一个位置的赋值只与相邻位置有关。
条件随机场,输入为单变量X,输出为单变量Y的马尔科夫随机场。
如果条件随机场的输入x和输出y有相同的结构,则为线性链条件随机场。

总结一下就是,tk是局部特征函数(节点与相邻节点,可见马尔可夫性),sk是节点特征函数(节点),两者前面的系数代表可信度,Z是规范化。
一个应用是词性标注。因为词性标注适合用条件随机场建模(也具有马尔可夫性)。
DL和NLP当年为什么不火
其实技术成熟度只是一个方面。另一个重要原因是没有数据。
数据量级的发展速度,我认为是快于所谓“技术”的发展速度的。
早年,NLP的数据很多都来自报纸这样的传统媒体。
词袋bow
把句子看成单词的集合,统计词出现的次数。
将非结构化的语言转化为结构化的map。
统计所有词会导致维度过高,也就是map中key太多,而且会很稀疏(平均value很小)。去掉停止词是方法之一。
词袋模型的应用之一是,结合距离定义,来对比文本相似度。
词袋模型的问题是,无法反映词之间的关联(比如主宾互换后仍然相似),而且无法捕捉否定关系(肯定句和否定句仍然相似)。
同样是词频,TF-IDF则多考虑了逆文档频率,与BoW不同。
n-gram
基于统计,判断连词成句的概率。
n是滑动窗口size,一般取2或者3,太大时有V的n次方种可能。词袋是n=1。
一个句子出现的概率,等于一连串条件概率的乘积。马尔可夫性可以简化计算。
n-gram的应用之一是智能联想。
当然,n-gram和词袋一样,n-gram统计结果也能作为文本特征,用于分类任务。
有character n-gram和token n-gram之分。
依存分析
处于支配地位的成分称之为支配者(governor,regent,head),而处于被支配地位的成分称之为从属者(modifier,subordinate,dependency)。
以谓语为中心(如下图的cancel),研究句子中词与词的关系。

(图来自CSDN flying_1314)
type dependency
也是分析句子中词与词的关系,出现频率很高。与依存分析的关系尚不清楚。
记得看stanford manual。
情感分析
这其实是NLP的一个简化子问题,把“理解”这个高级而难以实现的目标,变成了三分类问题(负面、中性、正面)。
情感分析的目标是,找出文档中的观点,甚至观点的限定条件和原因。
观点,就是(评价对象,对象属性,情感强度,评价者身份,时间)。
情感强度可以量化,比如-2~+2。表示负面/正面情感。
主要应用就是商品和服务的评论分析。西方还可用于选举分析等。
讽刺句是情感分析的难点。
社交媒体文本分析
长度短,不正式,网络用语,表情
针对社交媒体的不规范性,一般需要文本标准化和nlp工具再训练。
文本标准化的意思,比如heyyyyyy要规范成hey。
nlp工具再训练的意思,分词器POS/依存语法分析器/命名实体识别器NER等工具都是由报纸等传统数据训练出来的,需要在此基础上用社交媒体文本进行再训练。
wordnet
英文近义词词典。来自普林斯顿。
相对熵(KL散度),交叉熵,JS散度,Wasserstein推土机距离
https://zhuanlan.zhihu.com/p/25071913
https://zhuanlan.zhihu.com/p/74075915
叫熵已经不太直观了,直观上应该叫距离(不过不满足距离的对称性和三角不等式)。作用是衡量两个概率分布的距离,衡量预测值和实际值的差异。
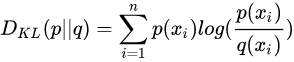
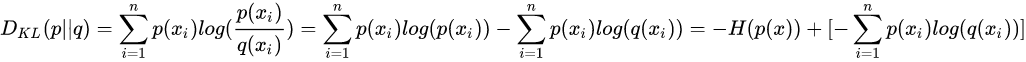
可以看见交叉熵和KL散度之间相差一个常数(实际值的熵)。

JS散度是KL散度的变体,解决对称性的问题。
推土机距离的式子我都看不懂。直觉上上面两篇文章都很好。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
可以看出,两个分布没有重叠时,KL会是0,这就是梯度消失。
推土机距离就是为了解决这个问题。WGAN在2017年提出。
浪潮起因
第一,硬件发展,如GPU。
第二,数据量来了。
第三,深度学习能从欧氏空间数据中提取潜在特征。
正则化项
翻译成正则不好,看不出“额外的约束”的意思。
目的是惩罚,比如惩罚复杂模型,惩罚译文长度。
比如说L1范数,是参数系数绝对值的和。所以参数较少的正则项就会较小。从几何角度(单位矩形)看,容易出0项,也就是能让参数稀疏。
L2范数则没有稀疏的作用(从几何角度看),但它能避免大参数(12+32>22+22),让参数普遍较小。如果有部分参数过大,抗扰动能力就不好。
正则化项一般有系数λ。
欧拉公式
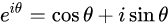
正弦波
傅里叶级数
周期函数可以表示为正弦波的叠加。
周期性,使有限能代表无限。
频域分析的结果就是,告诉你具体用哪些正弦波能叠出来。
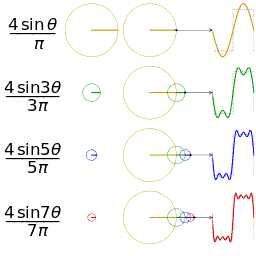
傅氏变换将信号投影到正交空间,看上图就能理解了。
从侧面看只有振幅信息,从下面看可以做出相位谱。
傅里叶级数,时域中周期、连续,频域中非周期、离散。
傅里叶变换
将一个时域非周期的连续信号(周期无穷大),转换为一个在频域非周期的连续信号。
对于有限区间非周期函数,可以通过复制的方法变成周期函数。
将函数投影到正交空间,在正交空间解决问题,再逆变换。典型例子是卷积定理,嫌卷积麻烦,那就先做傅氏变换,在正交空间做乘法,然后再反变换。
傅里叶变换的应用
滤波,去除特定的频率。在频域很容易做到,减少一根棍子就行。
解微分方程、计算卷积。复变函数课程中大家都学过。原理是微分积分变成了乘除法。想不起来了的话,可以翻一翻“常用傅里叶变换表”找找感觉。
卷积
两个函数参与卷积,输出另一个函数。
一个输入是输入信号,另一个输入代表系统。
翻转,乘积,滑动。在使用特定的卷积核时,可以看成滑动平均。
一个域中的卷积相当于另一个域中的乘积。
任意信号f(t)可表示为冲激序列之和,跟冲激函数的卷积。
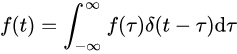
积分,就是先分割再累加。看看上式,可以理解,跟冲激函数卷积,相当于先分割为无数脉冲,再累加。
t决定两个函数的相对位置。在不同的相对位置下,求重叠面积,就得到输出函数在此位置的值。
据wiki,整数乘法和多项式乘法都是卷积。
图像处理中,用作图像模糊、锐化、边缘检测。
统计学中,加权的滑动平均是一种卷积。
概率论中,两个统计独立变量X与Y的和的概率密度函数是X与Y的概率密度函数的卷积。
fine tuning
指微调。
RELU/sigmoid/tanh
据wiki,增强网络的非线性特性。ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
池化层,池化
非线性形式的降采样。“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。
卷积层,边缘探测
卷积层可以发现边缘。
边缘探测的基本过程,先灰度化,再用低通滤波器降噪,用高通滤波器提取边缘,最后二值化。如图。

在CNN用于图像处理时,卷积核=滤波器=矩阵,图像卷积如图:
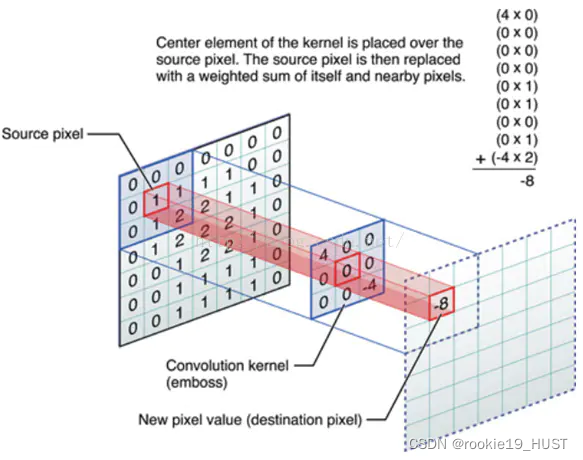
从结果来看,输出的是原图的边缘。这其实也是一种特征提取。网络的每一层输出都可以视为特征。
学习的过程,其实是寻找合适的卷积核的过程(对于边缘检测,已经有一些广泛使用的卷积核)。卷积核就是参数矩阵。
channel 通道
灰度图像,只有一个通道。RGB是三通道。
欧氏空间、grid、结构化数据
说的都是一件事情。
特征分解和谱分解
几乎一样。但谱分解形式上是和式,能让人联想到傅里叶级数。
图的拉普拉斯矩阵为什么叫拉普拉斯矩阵
https://zhuanlan.zhihu.com/p/362416124
关键是其中拉普拉斯算子的推广。
高斯分布:最大熵?
最混乱的应该是均匀分布。不过在限制方差的时候,高斯分布是最大熵模型。
印象中信息论好像学过同义的定理。
有人说,高斯分布是“无知”的。对此我的理解是,它是“稳妥”、“不武断”的,如果你只知道均值和方差,别人来问你数据是什么分布,你如何回答?你回答相应参数的高斯分布,会比较稳妥。因为这一回答没有做其它的假设,没有臆断,没有凭空制造什么先验信息。最大熵意味着这是你能给出的,最宽泛、最不确定的答案,因而说它“无知”、“稳妥”。
triplet loss
triplet三元组,包括a anchor,p positive,n negative。思想是让a和p的距离小,a和n的距离大。