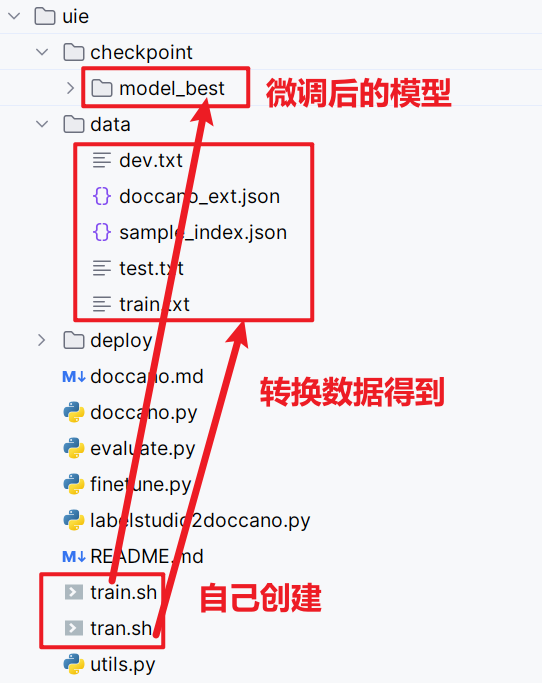
预处理doccano标注的数据
该章节详细说明如何通过doccano.py脚本对doccano平台导出的标注数据进行转换,一键生成训练/验证/测试集。
在本地部署UIE模型
下载模型压缩包:
本来是要通过一定的方法(GitZip)才能在整体的大项目仓库中下载的,不详细讲,这里直接给压缩包。
PaddleNLP-model_zoo.zip - 蓝奏云 (lanzoub.com)
抽取式任务数据转换
- 当标注完成后,在 doccano 平台上导出
JSONL(relation)形式的文件,并将其重命名为doccano_ext.json后,放入./data目录下。 - 通过 doccano.py 脚本进行数据形式转换,然后便可以开始进行相应模型训练。
python doccano.py \--doccano_file ./data/doccano_ext.json \--task_type "ext" \--save_dir ./data \--negative_ratio 5
当然也可以将这个命令保存为tran.sh文件
训练UIE模型
- 使用标注数据进行小样本训练,模型参数保存在
./checkpoint/目录。
tips: 推荐使用GPU环境,否则可能会内存溢出。CPU环境下,可以修改model为uie-tiny,适当调下batch_size。
增加准确率的话:--num_epochs 设置大点多训练训练
可配置参数说明:
model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 "uie-base"、 "uie-medium", "uie-mini", "uie-micro", "uie-nano", "uie-m-base", "uie-m-large"。multilingual:是否是跨语言模型,用 "uie-m-base", "uie-m-large" 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。device: 训练设备,可选择 'cpu'、'gpu' 、'npu'其中的一种;默认为 GPU 训练。per_device_train_batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。per_device_eval_batch_size:开发集评测过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为3e-5。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。logging_steps: 训练过程中日志打印的间隔 steps 数,默认100。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0;do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估。
该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
微调命令
export finetuned_model=./checkpoint/model_bestpython finetune.py \--device gpu \--logging_steps 10 \--save_steps 100 \--eval_steps 100 \--seed 42 \--model_name_or_path uie-base \--output_dir $finetuned_model \--train_path ./data/train.txt \--dev_path ./data/dev.txt \--max_seq_length 512 \--per_device_eval_batch_size 16 \--per_device_train_batch_size 16 \--num_train_epochs 20 \--learning_rate 1e-5 \--label_names "start_positions" "end_positions" \--do_train \--do_eval \--do_export \--export_model_dir $finetuned_model \--overwrite_output_dir \--disable_tqdm True \--metric_for_best_model eval_f1 \--load_best_model_at_end True \--save_total_limit 1
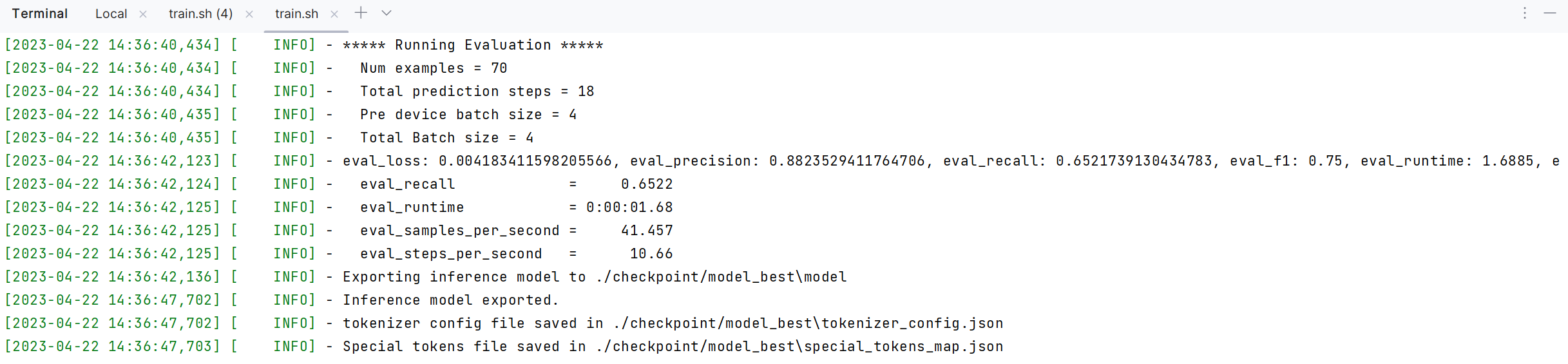
训练完成的结果:
验证UIE模型效果
通过运行以下命令进行模型评估:
python evaluate.py \--model_path ./checkpoint/model_best \--test_path ./data/dev.txt \--batch_size 16 \--max_seq_len 512
根据我们手动标注的数据训练微调后,再次测试自有标注的领域数据,返回的准确率为88%.

部署微调后的UIE模型
本地终端定制模型一键预测
paddlenlp.Taskflow装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件model_state.pdparams。
from pprint import pprint
from paddlenlp import Taskflow
schema = ['出发地', '目的地', '费用', '时间']#根据自身实体类别修改
# 设定抽取目标和定制化模型权重路径
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
pprint(my_ie("城市内交通费7月5日金额114广州至佛山"))
经过测试,原本无法预测出来的类型在引入自己标注的模型之后就可以识别出来了。自此我们可以实现标注的数据用于训练,训练的模型又可以提升我们标注的速率。
模型快速服务化部署
在UIE的服务化能力中我们提供基于PaddleNLP SimpleServing 来搭建服务化能力,通过几行代码即可搭建服务化部署能力。
在上一篇文章如何使用doccano+flask+花生壳+服务器实现命名实体识别ner自动标注 - 孤飞 - 博客园 (cnblogs.com)中的部署代码里,我们修改task_path模型路径为刚刚微调过后的即可完成识别。
from flask import Flask, request, jsonify
from paddlenlp import Taskflowapp = Flask(__name__)# 在这里定义你想要识别的实体类型
# UIE具有zero-shot能力,所以类型可以随便定义,但是识别的好坏不一定
schema = ['出发地', '目的地', '费用', '时间']#根据自身实体类别修改# 第一运行时,联网状态下会自动下载模型
# device_id为gpu id,如果写-1则使用cpu,如果写0则使用gpu
ie = Taskflow('information_extraction', schema=schema, device_id=0,task_path='./uie/checkpoint/model_best/')#添加了tesk_path指向新的模型def convert(result):result = result[0]formatted_result = []for label, ents in result.items():for ent in ents:formatted_result.append({"label": label,"start_offset": ent['start'],"end_offset": ent['end']})return formatted_result@app.route('/', methods=['POST'])
def get_result():text = request.json['text']print(text)result = ie(text)formatted_result = convert(result)return jsonify(formatted_result)if __name__ == '__main__':# 这里写端口的时候一定要注意不要与已有的端口冲突# 这里的host并不是说访问的时候一定要写0.0.0.0,但是这里代码要写0.0.0.0,代表可以被本网络中所有的看到# 如果是其他机器访问你创建的服务,访问的时候要写你的ipapp.run(host='0.0.0.0', port=88)