目录
一、redis
二、布隆过滤器
三、缓存穿透问题
四、布隆过滤器解决缓存穿透

一、redis
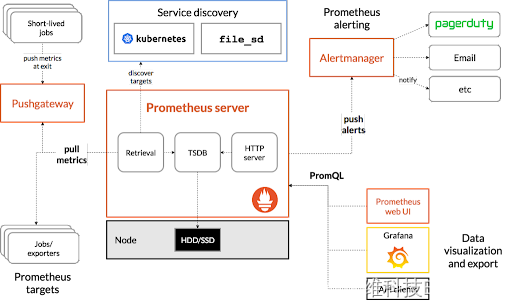
Redis(Remote Dictionary Server)是一种开源的内存数据存储系统,也是一个使用键值对(Key-Value)方式的高性能数据库。Redis以其快速、灵活和丰富的数据结构而闻名,常用于缓存、队列、实时数据分析等场景。
Redis支持多种数据结构,包括字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)等。这些数据结构使得Redis能够满足各种需求,如缓存数据、计数器、排行榜、发布订阅等。
Redis具有以下几个关键特点:
-
内存存储:Redis将数据存储在内存中,因此读写速度非常快。它支持持久化到磁盘,以确保数据的持久性。
-
高性能:Redis使用单线程模型,避免了多线程的竞争和上下文切换开销,从而提供了极高的性能。此外,Redis还通过使用异步I/O和高效的数据结构等手段进一步提升了性能。
-
多功能性:Redis不仅仅是一个简单的键值存储,还支持丰富的功能,如事务、发布订阅、Lua脚本等。这些功能使得Redis能够在各种场景下发挥作用。
-
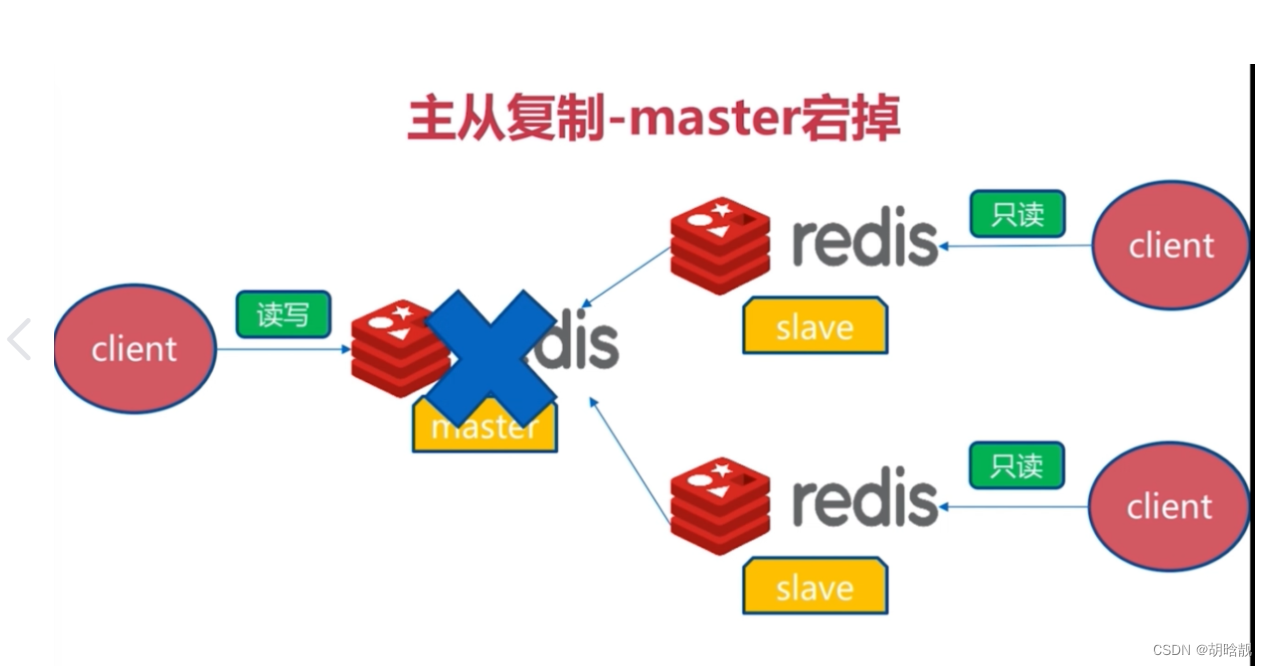
高可用性:Redis支持主从复制和哨兵机制,以提供高可用性和故障恢复能力。当主节点发生故障时,Redis能够自动将从节点提升为主节点,并继续提供服务。
总的来说,Redis是一个功能丰富、高性能的内存数据库,适用于各种场景,如缓存、消息队列、实时数据处理等。其简单易用的接口和灵活的数据结构使得开发者能够快速构建高效可靠的应用系统。
二、布隆过滤器
布隆过滤器(Bloom Filter)是一种概率型的数据结构,用于判断一个元素是否可能存在于一个集合中,具有高效的查询和存储特性。它基于位数组和一系列哈希函数构建,可以对元素进行快速的插入和查询操作。
布隆过滤器的原理是通过多个哈希函数将元素映射到位数组的不同位置上。当一个元素被插入时,对应的位数组位置被标记为1。判断一个元素是否存在时,会对元素进行相同的哈希映射操作,如果所有对应的位数组位置都为1,则可能存在于集合中;如果有任何一个位数组位置为0,则一定不存在于集合中。
布隆过滤器的主要优点是空间效率高和查询速度快。因为它只需要使用少量的空间来存储位数组,而且查询操作只需要进行位数组的读取,时间复杂度为O(1)。另外,布隆过滤器可以容忍一定的误判率,即可能会将不存在的元素判断为存在,但不会将存在的元素判断为不存在。
然而,布隆过滤器也有一些缺点。首先,它无法删除已插入的元素,因为删除会影响到其他元素的判断结果。其次,随着元素数量的增加,误判率会逐渐上升。因此,在设计布隆过滤器时需要合理选择位数组大小和哈希函数的数量。
布隆过滤器常用于需要快速判断元素是否存在的场景,如缓存穿透、URL去重、反垃圾邮件等。它可以在很小的空间开销下,提供高效的元素存在性判断,减少了对实际数据存储的依赖和查询的时间开销。
三、缓存穿透问题
缓存穿透是指在使用缓存系统时,某个请求查询的数据在缓存中不存在,导致请求直接访问数据库或其他存储系统,从而增加了请求的响应时间和系统的负载。当恶意用户或非法攻击者故意查询不存在的数据时,可能会引发缓存穿透问题。
具体来说,缓存穿透问题发生的步骤如下:
- 用户发送一个查询请求,该请求对应的数据在缓存中不存在。
- 缓存系统接收到请求后,首先检查缓存中是否存在对应的数据。如果不存在,则需要从数据库或其他存储系统中获取数据。
- 由于查询的数据在存储系统中也不存在,缓存系统无法将数据写入缓存,直接返回查询结果为空。
- 用户发起的大量查询请求都会导致缓存系统频繁查询数据库,增加了数据库的负载和查询时间。
缓存穿透问题对系统的影响主要包括两个方面:
- 响应时间延迟:由于缓存无法命中,每次都需要访问数据库或其他存储系统,导致响应时间变慢。
- 系统负载增加:大量的缓存穿透请求会直接落到存储系统上,增加了存储系统的负载,可能导致性能下降甚至崩溃。
为了解决缓存穿透问题,常见的方法包括:
- 布隆过滤器(Bloom Filter):使用布隆过滤器来过滤掉不存在的数据,减轻对存储系统的压力。
- 空值缓存:当发现某个查询结果为空时,将空结果也缓存起来,避免重复查询。
- 热点数据预热:将热点数据提前加载到缓存中,降低缓存穿透的概率。
- 异步加载:当查询结果不存在时,可以使用异步的方式去加载数据,避免阻塞查询线程。
- 限制恶意请求:对于频繁查询不存在数据的请求,可以进行限制或封禁,以防止恶意攻击。
通过以上措施,可以有效地减少缓存穿透问题的发生,提高系统的性能和稳定性。

四、布隆过滤器解决缓存穿透
使用布隆过滤器可以有效地解决缓存穿透问题。下面是使用布隆过滤器来解决缓存穿透问题的步骤:
-
创建布隆过滤器:根据预估的数据量和期望的误判率,创建一个合适大小的布隆过滤器。布隆过滤器的大小取决于预期存储的数据量和所允许的误判率。
-
初始化布隆过滤器:将缓存中已存在的数据添加到布隆过滤器中。这样,在后续的查询中,如果查询的数据在布隆过滤器中不存在,就可以直接返回不存在,而不需要访问存储系统。
-
查询数据:在每次查询之前,先使用布隆过滤器判断查询的数据是否已经存在于布隆过滤器中,如果不存在,则可以直接返回查询结果为空,避免了对存储系统的访问。
-
数据写入缓存:当从存储系统获取到数据后,需要将数据写入缓存中,并同时将数据添加到布隆过滤器中,以保证下次查询时可以命中缓存。
需要注意的是,由于布隆过滤器的特性,存在一定的误判率,即有可能将实际不存在的数据误判为存在。为了避免这种情况,可以将布隆过滤器作为缓存的一个辅助工具,仍然需要进行实际的数据验证,例如在缓存层之上再添加一层校验,从存储系统获取数据并验证其真实性。
通过使用布隆过滤器,可以在缓存层面上快速判断数据是否存在,避免了对存储系统的频繁访问,提高了系统的性能和响应速度,有效解决了缓存穿透问题。