关于网页视频下载方法(仅针对存在index.m3u8)
一、使用工具。
必备工具:迅雷、ffmpeg、python环境
选用工具:猫抓插件
二、获取m3u8、key和ts文件。
像腾讯课堂希望下载的课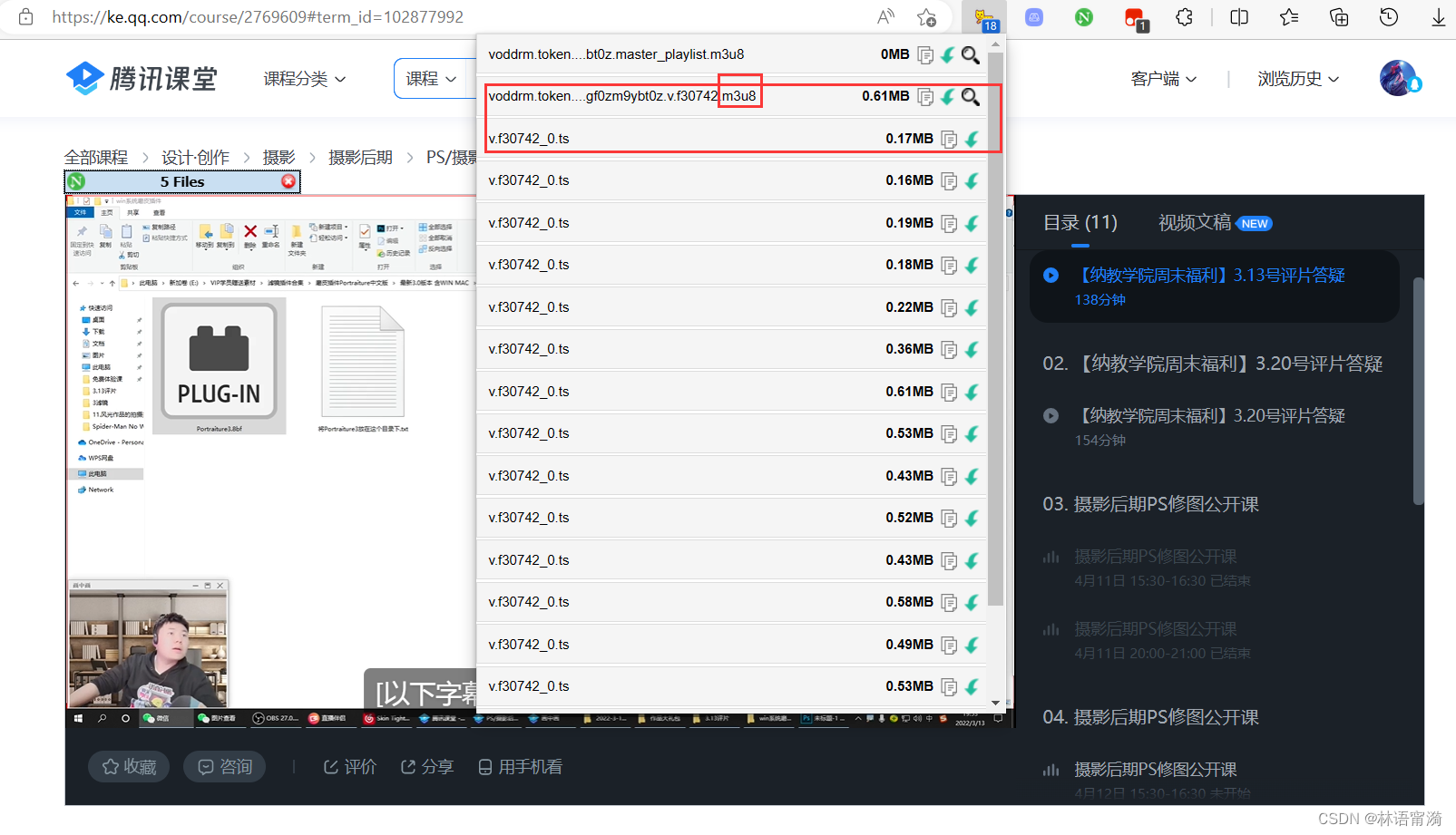
1.下载m3u8文件。
首先使用【猫抓视频下载】的浏览器拓展,可以清晰地看到,它不抓到的内容。我们需要的就是这个 .m3u8 的文件。
ps:其中可以也将其中的一个ts文件下下来,主要需要的是它的下载连接地址。
(当然也可以用f12,然后点击网络查看监控到的元素,复制其中的URL,在新的页面粘贴就可以下载。ps:没有监控到可以试着刷新一下。)
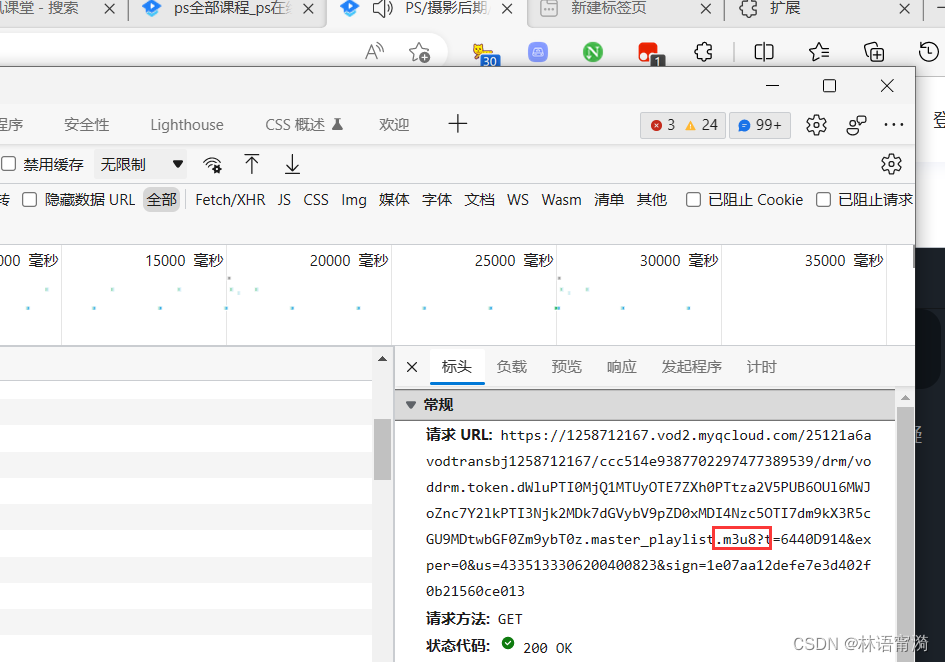
2.解析m3u8文件。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e6rE0t1z-1681308716521)(G:\document\未来\领域继承与反哺\遗产收集瓶\编程-开发\a文章\关于网页视频下载方法(仅针对存在index.m3u8)\打开m3u8文件.png)]](https://img-blog.csdnimg.cn/0cfcc857971f4be18321524c51c89eb6.png)
用记事本打开m3u8文件。
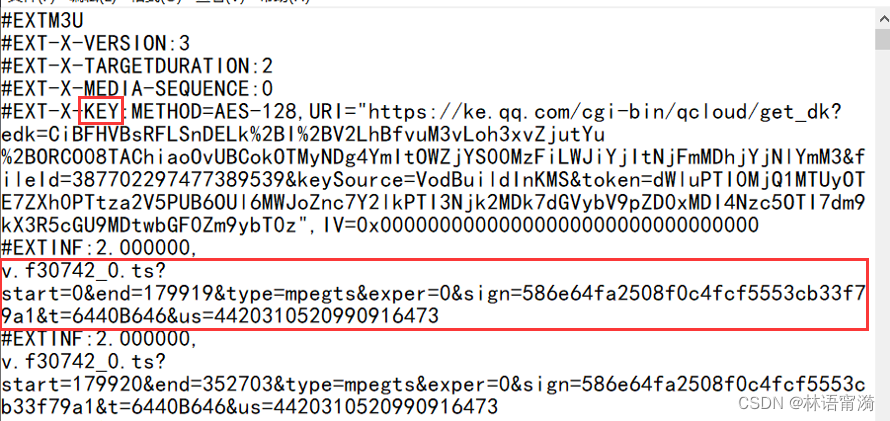
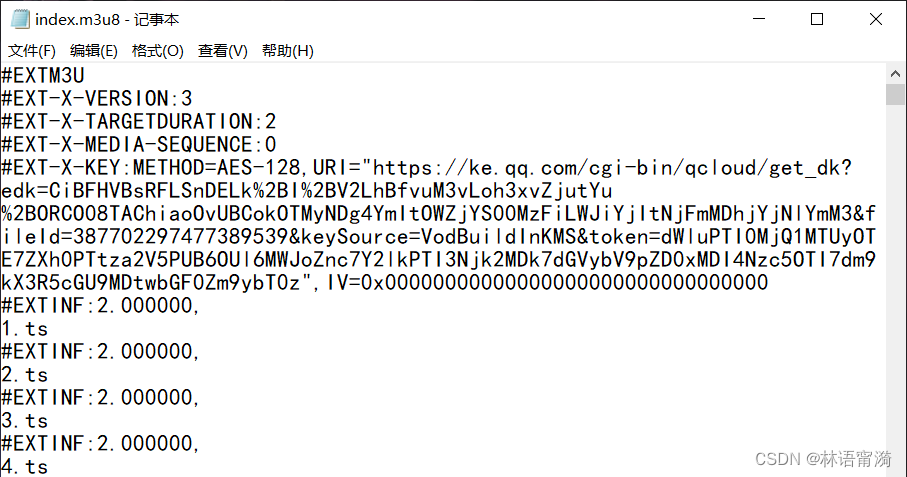
通过上图可以看到,这个m3u8文件是经过加密的,这个key的url就是加密的路径。所以我们要将它复制,在浏览器打开并下载。
部分m3u8文件显示的key文件路径是不全的,所以就得通过f12去寻找key的url,又或者通过刚才下载到的ts文件,然后通过其的下载连接,比如这样:
假设它的url是这样:
https://1258712167.vod2.myqcloud.com/25121a6avodtransbj1258712167/ccc514e9387702297477389539/drm/v.f30742_0.ts
那么 v.f307422_0.ts 文件前面的就是它们的前缀,要复制出来,拼接好。就如上图所示的ts文件也是不完整的url的路径,所以需要补全。(当然我这里讲拼接key的前缀只是示范,m3u8文件里已经有完整的url了,所以我们要把它下下来。)
3.拼接ts文件完整路径。
由于迅雷复制打包url下载限制只能是1000个。所以,我们需要在拼接url的同时,还要对它分开成各个文件夹进行下载。在这里我采用python进行切片打包。
首先打开m3u8文件,之后在line中填入需要拼接的前缀内容。而i[0] == ‘v’,则是判定是ts文件的特征,所有的ts文件的前缀都是’v’。(见过有些是’\'。)
with open(r'C:\Users\victo\Desktop\voddrm.token.dWluPTI0MjQ1MTUyOTE7ZXh0PTtza2V5PUB6OUl6MWJoZnc7Y2lkPTI3Njk2MDk7dGVybV9pZD0xMDI4Nzc5OTI7dm9kX3R5cGU9MDtwbGF0Zm9ybT0z.v.f30742.m3u8') as f:a = []for i in f.readlines():a.append(i)def split_ts(a):line = 'https://1258712167.vod2.myqcloud.com/25121a6avodtransbj1258712167/ccc514e9387702297477389539/drm/'ts = []for i in a:if i[0] == 'v':i = line + its.append(i)return tsts = split_ts(a)def save_href(ts,i):print(i)with open(r'C:\Users\victo\Desktop\番{}.txt'.format(i), 'w') as w:w.writelines(ts)w.close()def thousand_href(ts):i = 0if len(ts) > 1000:i = 1save_href(ts[:1000],i)if len(ts[1000:]) > 1000:i = 2save_href(ts[1000:2000], i)if len(ts[2000:]) > 1000:i = 3save_href(ts[2000:3000], i)if len(ts[3000:]) > 1000:i = 4save_href(ts[3000:4000], i)if len(ts[4000:]) > 1000:i = 5save_href(ts[4000:5000], i)if len(ts[5000:]) > 1000:i = 6save_href(ts[5000:6000], i)if len(ts[6000:]) > 1000:i = 7save_href(ts[6000:7000], i)if len(ts[7000:]) > 1000:i = 8save_href(ts[7000:8000], i)if len(ts[8000:]) > 1000:i = 9save_href(ts[8000:9000], i)if len(ts[9000:]) > 1000:i = 10save_href(ts[9000:10000], i)if len(ts[10000:]) > 1000:i = 11save_href(ts[10000:11000], i)save_href(ts[1000*(i):], i+1)thousand_href(ts)
拼接完成后,打开文本,全选复制,如果开启迅雷会自动弹出新建任务组,合并任务即可。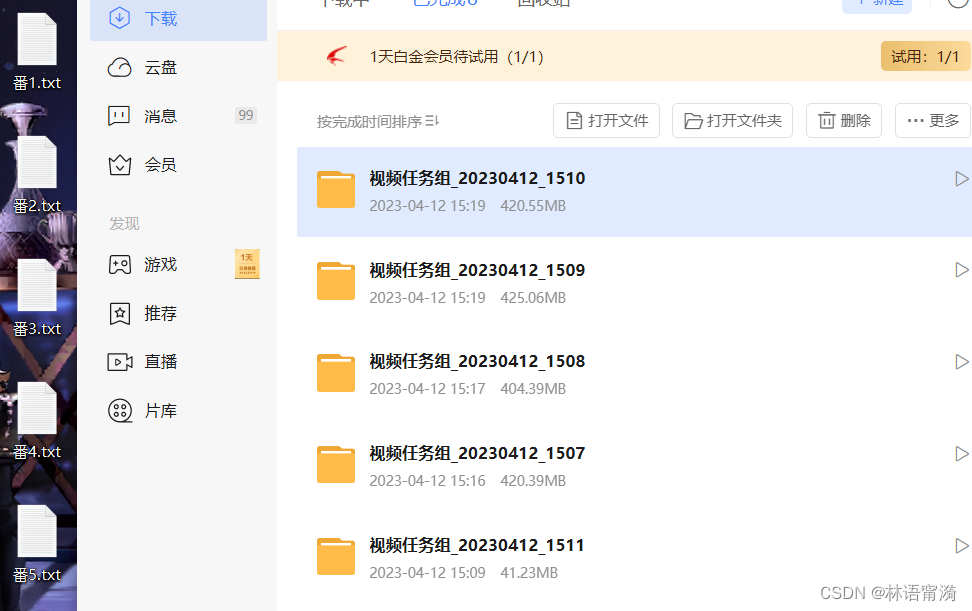
现在新的问题来了,下载下来的ts文件,迅雷是采取,以’?'作为文件名的分割,这样会导致ts文件名都是一样的,重复文件名的下载自然会在后缀出现下标。
(不过一般m3u8文件里记录的ts文件都有自己的字符串名字的……吧?)
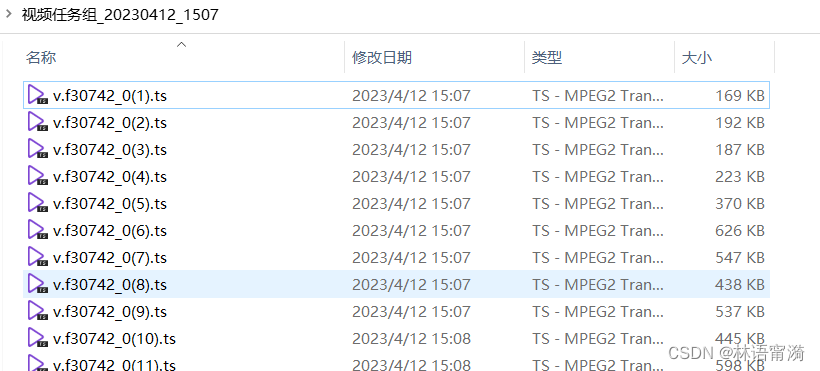
因此我这里对m3u8所有ts文件名进行了处理,所有ts文件以数字作为命名,进行了一次重命名。
那么相对应的,下载下来的文件也要重命名。一共5个文件夹,4125个ts文件。重命名脚本:
import os
path = 'D:\cookies\迅雷下载\视频任务组_20230412_1509'
files = os.listdir(path)
newfiles = []#第一个:0;第二个:1000;第三个:2000.
order = 2000for file in files:print(file)if "(" in file:num = int(file.replace('v.f30742_0(','').replace(').ts','')) + order +1newfiles.append(str(num)+'.ts')else:num = str(0+order+1)newfiles.append(num+'.ts')for i in range(len(files)):os.rename(path+'\\'+files[i],path+'\\'+newfiles[i])
4.调用ffmepg合并所有ts文件生成mp4
-
CMD打开命令提示符。
-
跳转到汇总所有ts文件的文件夹目录下。
-
输入命令:
ffmpeg -allowed_extensions ALL -i index.m3u8 -c copy D:\cookies\迅雷下载\kecheng.mp4
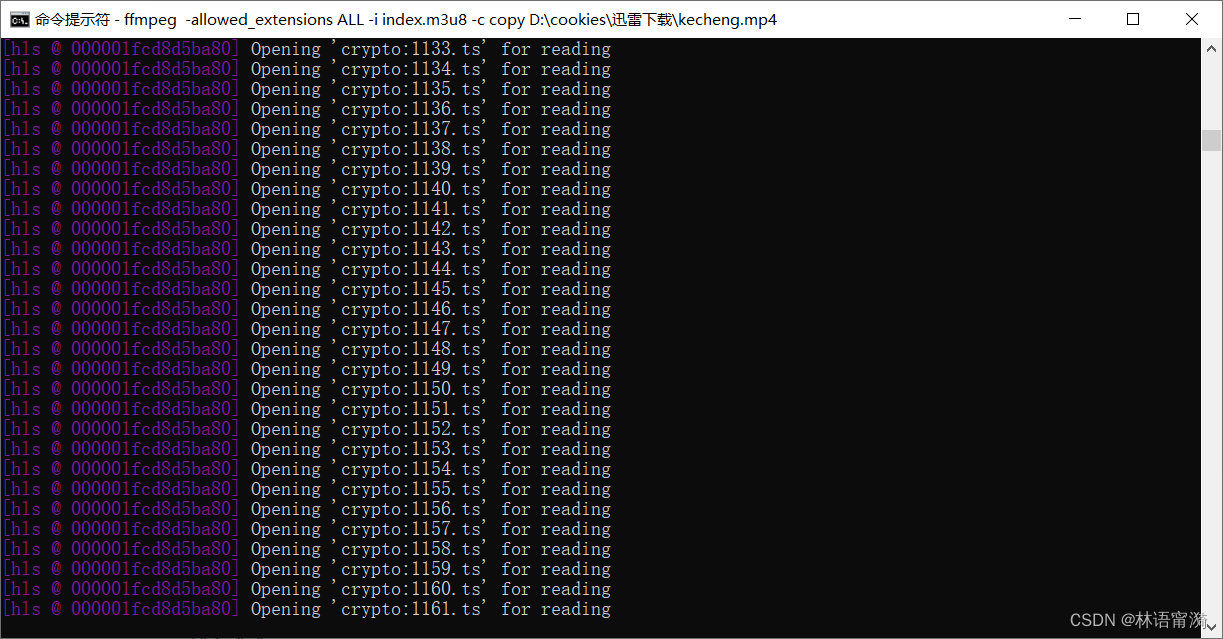
最后成功获得这节课程的文件!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UYoZ6OrQ-1681308716524)(G:\document\未来\领域继承与反哺\遗产收集瓶\编程-开发\a文章\关于网页视频下载方法(仅针对存在index.m3u8)\导出文件.png)]](https://img-blog.csdnimg.cn/ac64c9f3aab44064a82831baa5c53fc3.png)
5.结语。
以上的方法针对加密的视频爬取下载的性价比才高,对于那些没有加密的视频文件,其实直接用Neat Download Manager,或者IDM,又或者手机QQ浏览器都可以下载。
参考文章
ffmpeg详细安装教程:https://zhuanlan.zhihu.com/p/324472015
加密的m3u8、ts文件合并:https://www.cnblogs.com/f-ck-need-u/p/9033988.html
手把手教你下载浏览器上的视频:https://zhuanlan.zhihu.com/p/464729860
关于Neat Download Manager可以参考:https://zhuanlan.zhihu.com/p/187570397