「Kafka」Kafka理论知识解读(一)
- 1. Kafka与RabbitMQ的区别
- 2. Kafka适合什么样的场景?
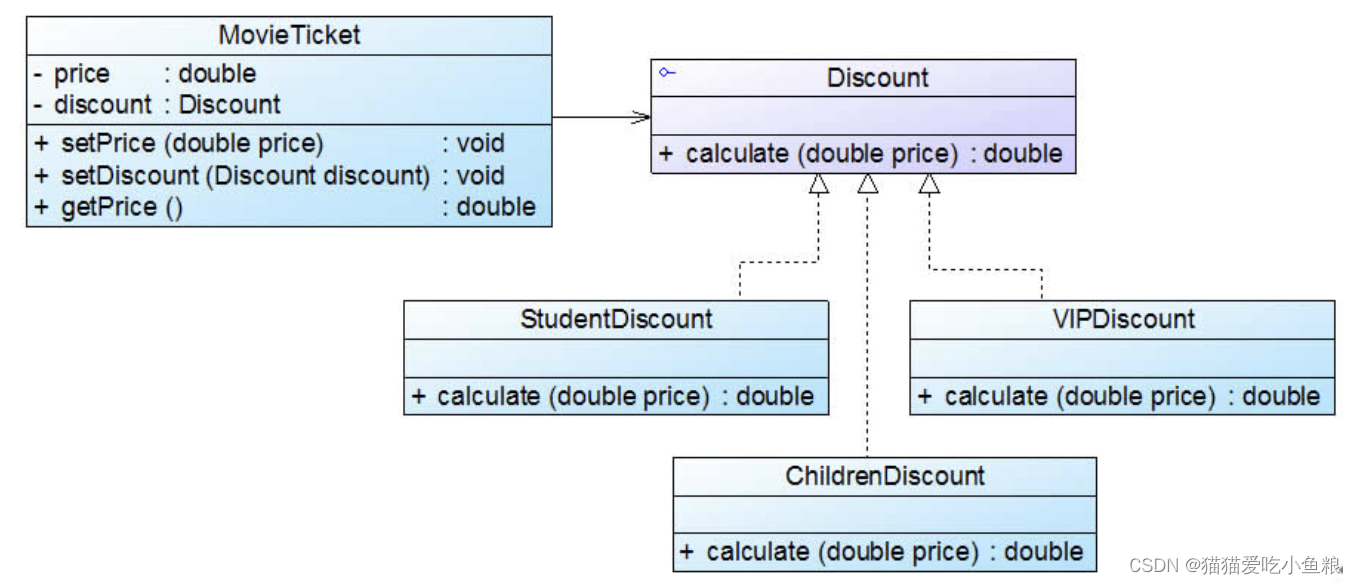
- 3. Kafka的核心概念:提供一串流式的记录 - topic
- 4. 分布式(高可用)
- 5. Kafka 的功能
- 6. Kafka 重要的五个概念
- 7. Kafka 如何进行持久化?
- 8. Kafka 的 Consumer 如何进行消费?
- 9. Kafka 的多副本机制(保证了 Kafka 的高可用)
1. Kafka与RabbitMQ的区别
Kafka与RabbitMQ的区别
2. Kafka适合什么样的场景?
它可以用于两大类别的应用:
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream
topic和topic之间内部进行变化)
3. Kafka的核心概念:提供一串流式的记录 - topic
Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:

每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
4. 分布式(高可用)
每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
5. Kafka 的功能
Kafka 是一个分布式流式处理平台,流平台具有三个关键功能:
消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险·。流式处理平台:在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
6. Kafka 重要的五个概念
Kafka 是一个 Pub-Sub 的消息系统,无论是发布还是订阅,都要指定 Topic。Kafka 将生产者发布的消息发送到Topic(主题)中,需要这些消息的消费者可以订阅这些 Topic(主题),如下图所示:
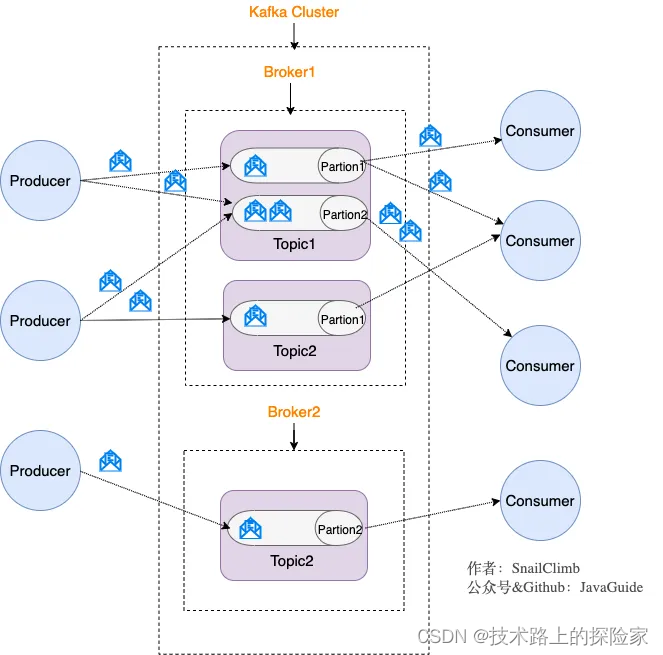
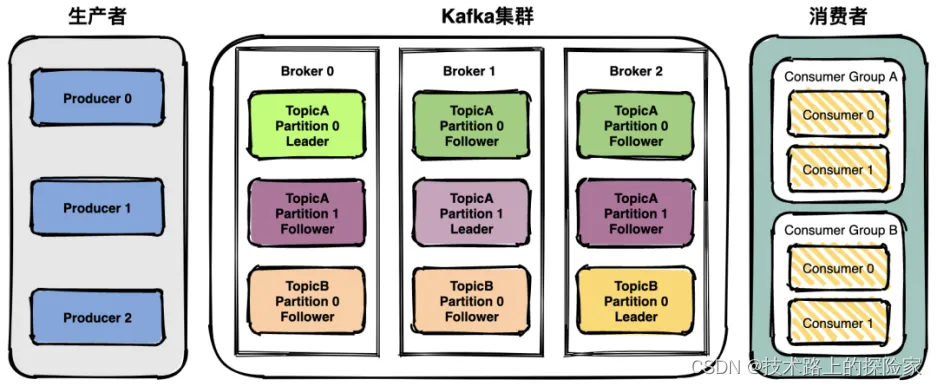
上面这张图也为我们引出了,Kafka 比较重要的几个概念:
- Producer(生产者):产生消息的一方。
- Consumer(消费者):消费消息的一方。
- Broker(代理):可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
- Topic(主题):Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
- Partition(分区):Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。
Kafka 天然是分布式的,往一个 Topic 丢数据,实际上就是往多个 Broker 的 Partition 存储数据。
7. Kafka 如何进行持久化?
● Kafka 是将 Partition 的数据写在磁盘上的(消息日志),不过 Kafka 只允许追加写入(顺序访问),避免缓慢的随机 I/O 操作。
● Kafka 也不是 Partition 一有数据就立马将数据写到磁盘上,它会先缓存一部分,等到足够多数据量或等待一定的时间再批量写入(flush)。
8. Kafka 的 Consumer 如何进行消费?
我们可以用消费者组,让每个 Consumer 去消费一个分区(这样可以提高吞吐量)。
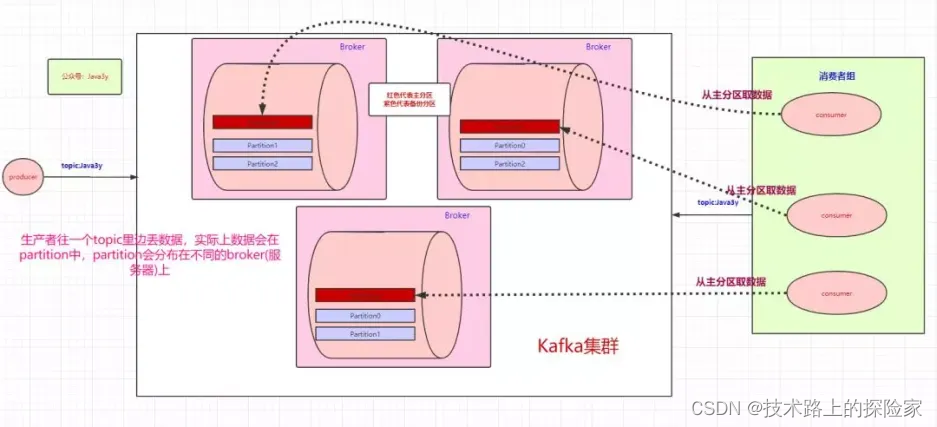
Consumer 在读的时候也很有讲究:正常的读磁盘数据是需要将内核态数据拷贝到用户态的,而 Kafka 通过调用sendfile()直接从内核空间(DMA的)到内核空间(Socket的),少做了一步拷贝的操作。
如果一个消费者组中的某个 Consumer 挂了,那挂了的 Consumer 所消费的分区就由存活的 Consumer 消费。那存活的 Consumer 怎么知道挂掉的 Consumer 消费到哪里呢?又或者是如果机器宕机需要重启,那么重启之后 Consumer 怎么知道自己消费到哪个位置呢?这就要引出
offset了,Kafka 就是用offset来表示 Consumer 的消费进度到哪了,每个 Consumer 会都有自己的offset,代表消息的序号。然后 Consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示『我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的 offset 来继续消费吧』(可以选择自动提交还是手动提交)。
在以前版本的 Kafka,这个offset是由 Zookeeper 来管理的,后来 Kafka 开发者认为 Zookeeper 不合适大量的删改操作,于是把offset保存在 Kafka 集群的__consumer_offsets这个 Topic 中。
9. Kafka 的多副本机制(保证了 Kafka 的高可用)
Kafka 基本架构是多个 broker 组成,每个 broker 是一个节点。创建一个 topic 可以划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 就放一部分数据,这就是天然的分布式消息队列。就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
Kafka 0.8 以后,Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?
- Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
- Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性,提高了容灾能力,不过也相应的增加了所需要的存储空间。