检索增强生成(RAG)应用程序通过将外部来源的数据集成到 LLM 中,擅长回答简单的问题。但他们很难回答涉及将相关信息之间的点连接起来的多部分问题。这是因为 RAG 应用程序需要一个数据库,该数据库旨在存储数据,以便轻松找到回答这些类型问题所需的所有内容。
知识图谱非常适合处理复杂的多部分问题,因为它们将数据存储为节点网络及其之间的关系。这种连接的数据结构允许 RAG 应用程序有效地从一条信息导航到另一条信息,从而访问所有相关信息。
使用知识图谱构建 RAG 应用程序可以提高查询效率,尤其是在处理连接的数据时,并且您可以将任何类型的数据(结构化和非结构化)转储到图中,而无需重新设计架构。
这篇博文探讨了:
- RAG 应用程序的内部运作
- 知识图谱作为一种高效的信息存储解决方案
- 结合图和文本数据以增强洞察力
- 应用思维链问答技术
RAG 的工作原理
检索增强生成(RAG)是一种通过从外部数据库检索相关信息并将其合并到生成的输出中来增强 LLM 响应的技术。
RAG 过程很简单。当用户提出问题时,智能搜索工具会在提供的数据库中查找相关信息:
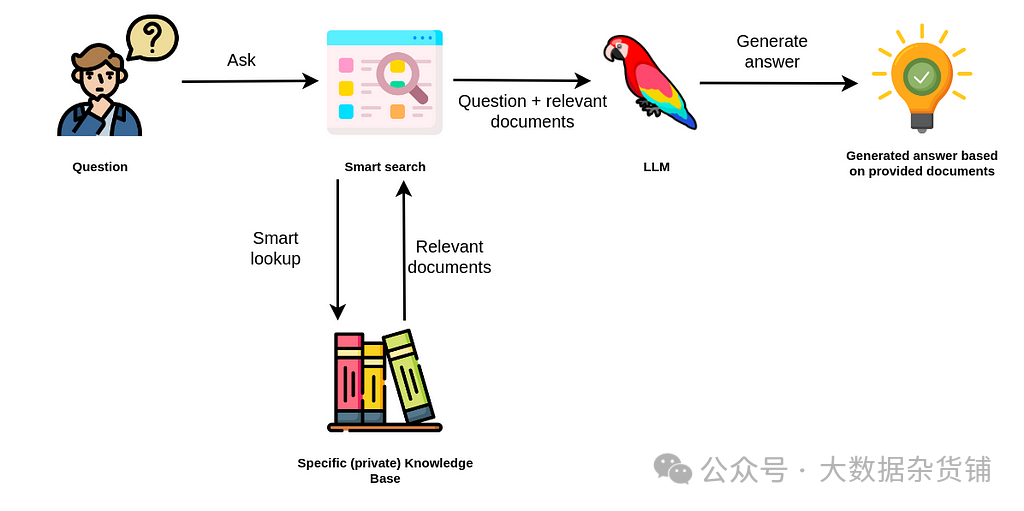
LLM 申请的检索增强方法
您可能使用过“与 PDF 聊天”等工具来搜索所提供文档中的信息。这些工具大多数使用向量相似性搜索来识别包含与用户问题相似的数据的文本块。实现很简单,如下图所示。
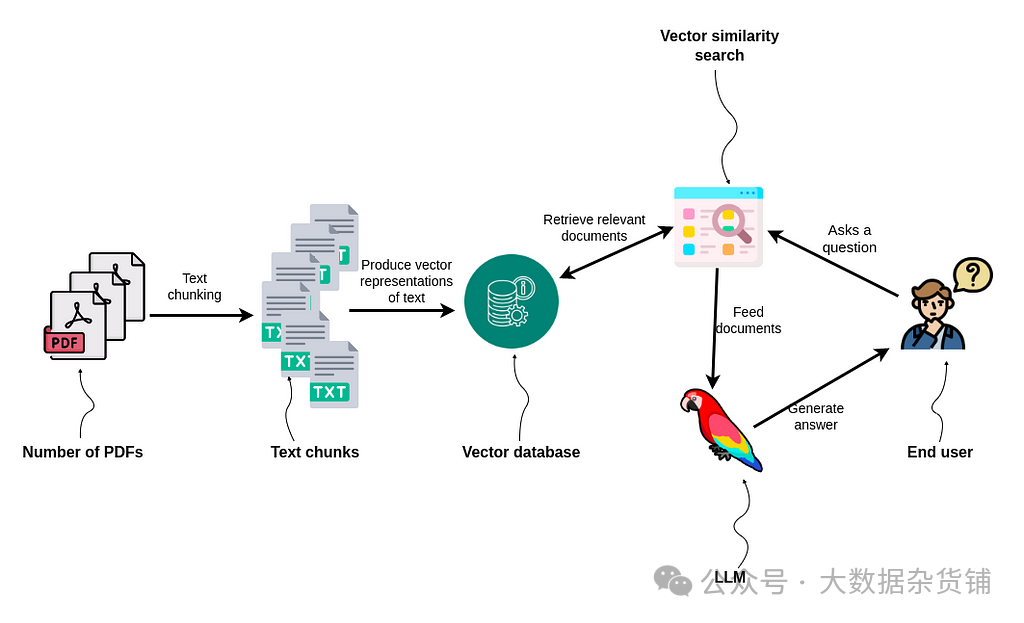
使用向量相似性搜索的 RAG 应用程序
PDF(或其他文档类型)首先被分割成多个文本块。您可以根据文本块的大小或文本块之间是否存在重叠来使用不同的策略。然后,RAG 应用程序使用文本嵌入模型来生成文本块的向量表示。
这就是在查询时执行向量相似性搜索所需的所有预处理。最后,RAG 在查询时将用户输入编码为向量,并使用余弦等相似性算法来比较用户输入和嵌入文本块之间的距离。
通常,RAG 会返回三个最相似的文档,为 LLM 提供背景信息,从而增强其生成准确答案的能力。当矢量搜索可以识别相关的文本块时,这种方法效果相当好。
然而,当 LLM 需要来自多个文档甚至多个文本块的信息来生成答案时,简单的向量相似性搜索可能不够。例如,考虑以下问题:
这个问题是多部分的,因为它包含两个问题:
- OpenAI 的前员工有哪些?
- 他们中有人创办了自己的公司吗?
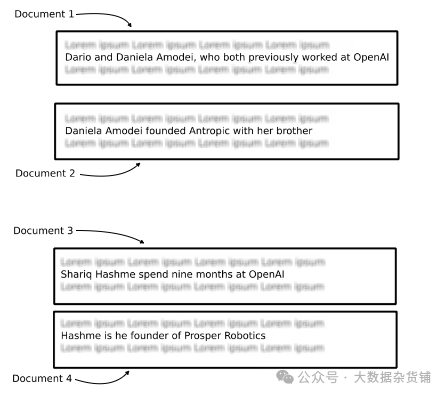
信息跨越多个文档
回答这些类型的问题是一个多跳问答任务,其中单个问题可以分解为多个子问题,而获得准确的答案需要检索大量文档。
简单地在数据库中对文档进行分块和嵌入,然后使用简单的向量相似性搜索不会达到多跳问题的目标。原因如下:
- 前 N 个文档中的重复信息:所提供的文档不能保证包含完整回答问题所需的所有信息。例如,排名前三的类似文件可能都提到 Shariq 在 OpenAI 工作过,并可能创立了一家公司,而忽略了所有其他成为创始人的前员工。
- 缺少参考信息:根据块大小,某些块可能不包含完整的上下文或对文本中提到的实体的引用。重叠块可以部分缓解丢失引用的问题。还有一些引用指向另一个文档的示例,因此您需要共同引用解析或预处理技术。
- 很难定义理想的 N 个检索文档:有些问题需要更多文档才能使 LLM 准确,而在其他情况下,大量文档只会增加噪音(和成本)。
在某些情况下,相似性搜索将返回重复的信息,而其他相关信息由于检索到的信息数量或嵌入距离较低而被忽略。
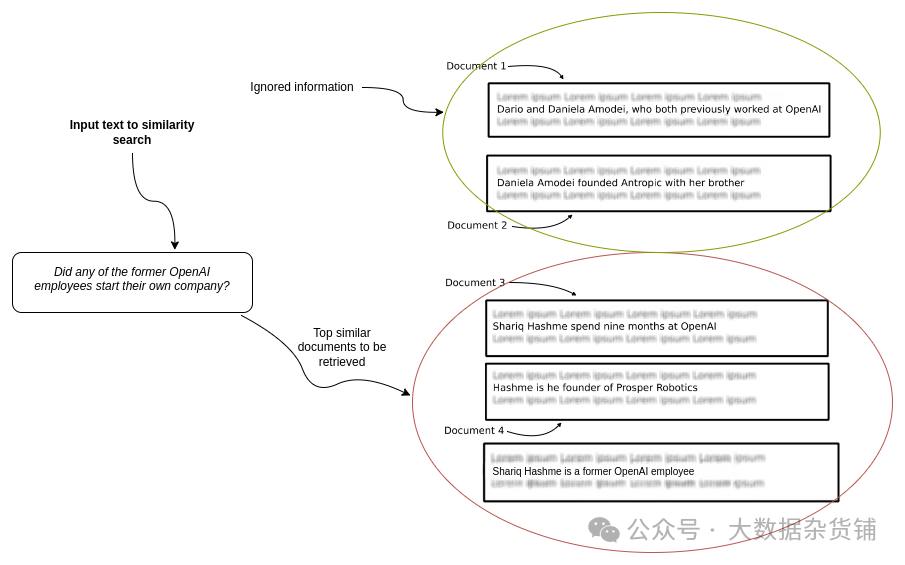
相似性搜索可能返回重复信息的示例,而其他相关信息可能由于检索到的信息数量或嵌入距离较低而被忽略
很明显,普通向量相似性搜索无法满足多跳问题。但我们可以采用多种策略来回答需要来自不同文档的信息的多跳问题。
知识图谱作为压缩信息存储
如果您密切关注 LLM 领域,您可能已经看到了压缩信息以使其在查询时更易于访问的技术。例如,您可以使用 LLM 提供文档摘要,然后嵌入和存储摘要而不是实际文档。使用这种方法,您可以消除大量噪音,获得更好的结果,并且不用担心提示令牌空间。
您还可以在摄取时或查询期间执行上下文摘要。查询期间的上下文压缩更具指导性,因为它选择与所提供的问题相关的上下文。但查询期间的工作负载越重,用户延迟预计就越差。我们建议将尽可能多的工作负载转移到摄取时间,以改善延迟并避免其他运行时问题。
可以应用相同的方法来总结对话历史记录,以避免遇到令牌限制问题。
我还没有看到任何有关将多个文档组合和汇总为单个记录的文章。我们可以合并和总结的文档组合可能太多,因此在摄取时处理所有文档组合的成本太高。知识图谱克服了这个问题。
信息提取管道已经存在了一段时间。这是从非结构化文本中提取结构化信息的过程,通常以实体和关系的形式。将其与知识图谱结合起来的美妙之处在于您可以单独处理每个文档。当知识图谱被构建或丰富时,来自不同记录的信息就被连接起来。
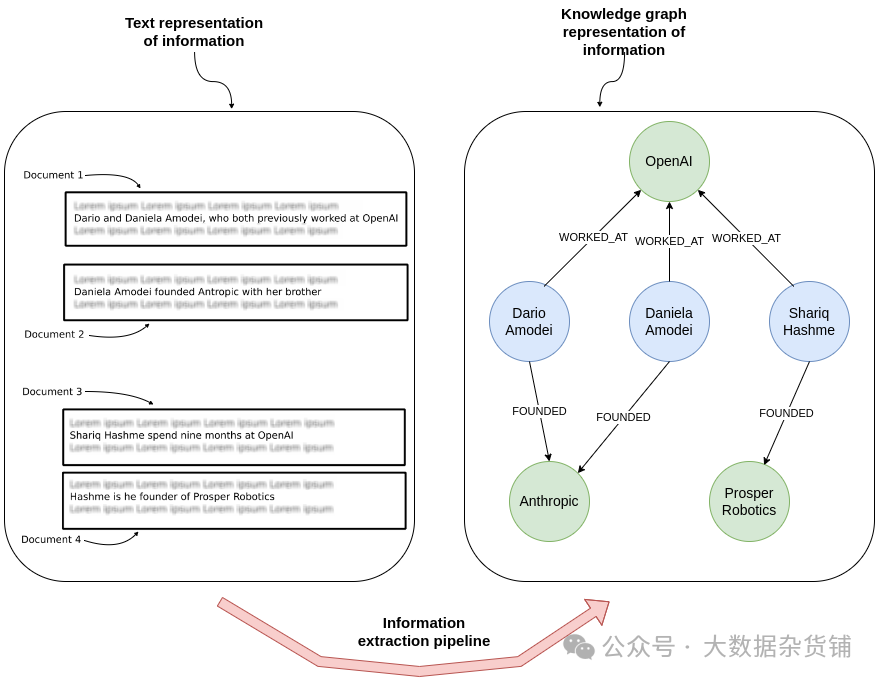
从文本中提取实体和关系以构建知识图谱
知识图谱使用节点和关系来表示数据。在此示例中,第一个文档提供了 Dario 和 Daniela 曾经在 OpenAI 工作的信息,而第二个文档提供了有关他们的 Anthropic 初创公司的信息。每条记录都是单独处理的,但知识图谱表示连接数据,从而可以轻松回答跨多个文档的问题。
大多数回答多跳问题的较新的 LLM 方法都侧重于在查询时解决任务。事实上,许多多跳问答问题可以通过在摄取之前预处理数据并将其连接到知识图谱来解决。您可以使用 LLM 或自定义文本域模型来执行信息提取管道。
为了在查询时从知识图谱中检索信息,我们必须构建适当的 Cypher 语句。幸运的是, LLM 非常擅长将自然语言翻译为 Cypher 图查询语言。
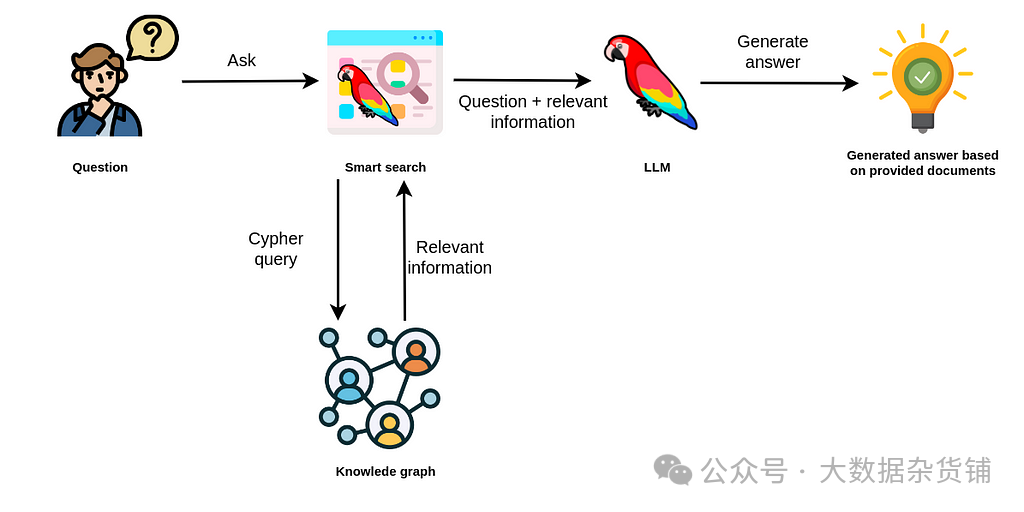
使用知识图谱的 RAG 的 LLM 应用
智能搜索使用 LLM 生成适当的 Cypher 语句,以从知识图谱中检索信息。然后,该信息被传递到另一个 LLM 调用,该调用使用原始问题和提供的信息来生成答案。在实践中,您可以使用不同的 LLM 来生成 Cypher 语句和答案,也可以在单个 LLM 上使用各种提示。
结合图形和文本数据
有时,您需要结合图形和文本数据来查找相关信息。例如,考虑这个问题:
在此示例中,您希望 LLM 使用知识图谱结构识别 Prosper Robotics 创始人,然后检索提及他们的最新文章。
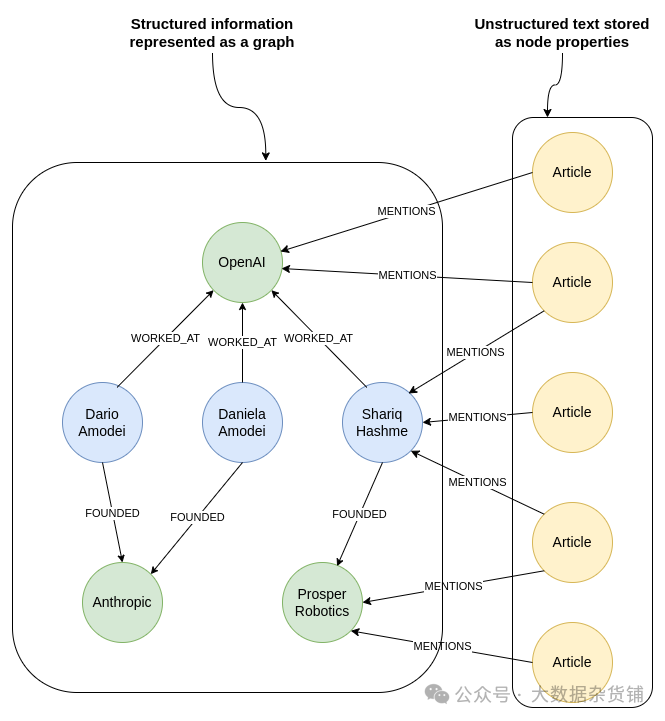
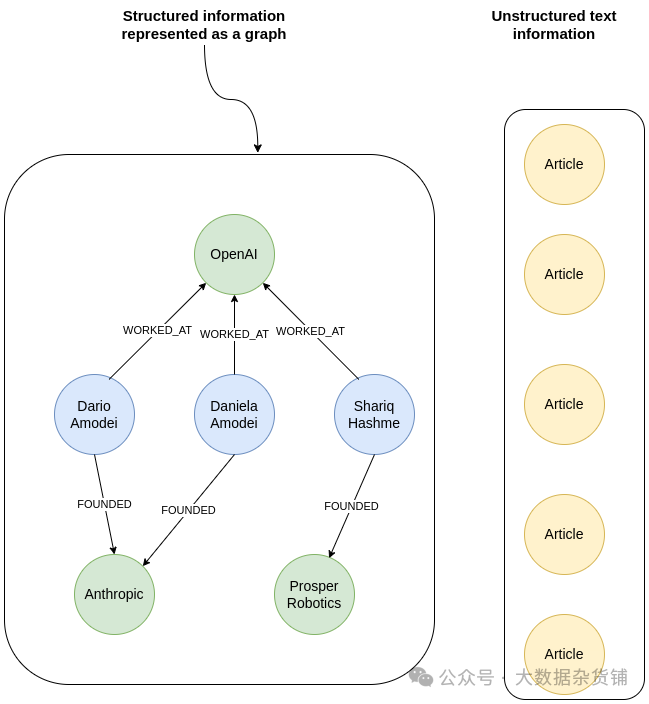
结构化信息和非结构化文本之间具有明确链接的知识图谱
在知识图谱中,您可以从 Prosper Robotics 节点开始,遍历到其创始人,然后检索提及他们的最新文章。
知识图谱表示有关实体及其关系的结构化信息,以及作为节点属性的非结构化文本。您还可以使用命名实体识别等自然语言技术将非结构化信息连接到知识图谱中的相关实体,如 MENTIONS 关系所示。
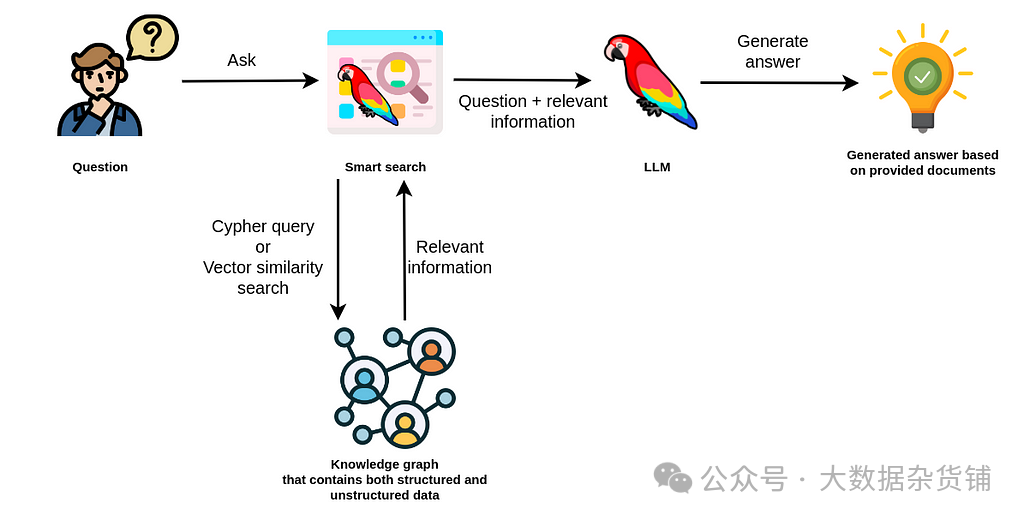
使用 Cypher 和向量相似性搜索从知识图谱中检索相关信息
当知识图谱包含结构化和非结构化数据时,智能搜索工具可以使用 Cypher 查询或向量相似度搜索来检索相关信息。在某些情况下,您还可以结合使用两者。例如,您可以从 Cypher 查询开始来识别相关文档,然后应用向量相似性搜索来查找这些文档中的特定信息。
在思维链中使用知识图谱
围绕 LLM 的另一个令人着迷的发展是思维链问题回答,尤其是 LLM 代理。
LLM 代理可以将问题分为多个步骤,定义计划,并利用任何提供的工具生成答案。通常,代理工具由代理可以查询以检索附加信息的 API 或知识库组成。
让我们再次考虑同样的问题:
知识图谱实体和非结构化文本之间没有明确的链接
假设您在文章和它们提到的实体之间没有明确的连接,或者文章和实体位于不同的数据库中。在这种情况下,使用思维链流程的 LLM 代理将非常有帮助。首先,代理会将问题分成子问题:
- Prosper Robotics的创始人是谁?
- 关于创始人的最新消息是什么?
现在代理可以决定使用哪个工具。假设它基于知识图谱,这意味着它可以检索结构化信息,例如 Prosper Robotics 创始人的名字。
代理发现 Prosper Robotics 的创始人是 Shariq Hashme。现在,智能体可以使用第一个问题中的信息重写第二个问题:
- 关于 Shariq Hashme 的最新消息是什么?
代理可以使用一系列工具来生成答案,包括知识图谱、向量数据库、API 等。对结构化信息的访问允许 LLM 应用程序执行需要聚合、过滤或排序的分析工作流程。考虑这些问题:
- 哪家单独创始人的公司估值最高?
- 谁创办的公司最多?
普通向量相似性搜索很难回答这些分析问题,因为它搜索非结构化文本数据,从而很难对数据进行排序或聚合。
虽然思维链展示了 LLM 的推理能力,但它并不是最用户友好的技术,因为由于多次 LLM 调用,响应延迟可能会很高。但我们仍然非常兴奋地了解更多有关将知识图谱集成到许多用例的思想流中的信息。

中途关于成立调查委员会的想法。
为什么将知识图谱用于 RAG 应用程序
RAG 应用程序通常需要从多个来源检索信息以生成准确的答案。虽然文本摘要可能具有挑战性,但以图格式表示信息有几个优点。
通过单独处理每个文档并将它们连接到知识图谱中,我们可以构建信息的结构化表示。这种方法可以更轻松地遍历和导航互连文档,从而实现多跳推理来回答复杂的查询。此外,在摄取阶段构建知识图谱可以减少查询期间的工作量,从而改善延迟。
RAG 应用程序将越来越多地使用结构化和非结构化数据来生成更准确的答案。知识图谱可以轻松吸收所有类型的数据。这种灵活性使其适用于广泛的用例和 LLM 应用程序,特别是涉及实体之间关系的应用程序(例如欺诈检测、供应链、主数据管理等)。
通读 GitHub 存储库上有关此项目的文档。