1. BLIP
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP的总体结构如下所示,主要包括三部分:
- 单模态编码器(Image encoder/Text encoder):分别进行图像和文本编码,文本编码器和BERT一样在输入中增加了[CLS]来表征整个句子
- Image-grounded text encoder:通过在文本编码器的每个transformer块中的self-attention和FFN之间增加cross attention来注入视觉信息,在具体任务里在输入文本前增加特殊标识符[Encode],输出中该特殊标识符的表征代表图像文本对的表征
- Image-grounded text decoder:将Image-grounded text encoder中的self attention层换成causal self-attention层,特殊标识符[Decode]表示序列解码的开始符号
总体包括三个损失:
-
图像-文本对比损失 ITC(Image-Text Contrastive Loss):针对图像编码器和文本编码器,通过正负图文对的对比学习,来对齐图像和文本的潜在特征空间
-
图像-文本匹配损失 ITM(Image-Text Matching Loss):针对以图像为基础的文本编码器,通过对图文匹配性进行二分类,建模图文多模态信息的相关性
-
语言建模损失 LM(Language Modeling Loss ):针对以图像为基础的文本解码器,通过交叉熵损失进行优化,训练模型以自回归的方式生成目标caption

2. BLIP 2
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP-2通过利用预训练的视觉模型和语言模型来提升多模态效果和降低训练成本,预训练的视觉模型能够提供高质量的视觉表征,预训练的语言模型则提供了强大的语言生成能力.
BLIP-2 由预训练的Image Encoder,预训练的Large Language Model,和一个可学习的 Q-Former 组成,整体结构如下图所示
- Image Encoder:负责从输入图片中提取视觉特征,本文试验了两种网络结构,CLIP 训练的 ViT-L/14和EVA-CLIP训练的 ViT-g/14。
- Large Language Model:负责文本生成,本文试验了decoder-based LLM and encoder-decoder-based LLM。
- Q-Former:负责弥合视觉和语言两种模态的差距,由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层

BLIP-2 在预训练时冻结预训练图像模型和语言模型,但是,简单地冻结预训练模型参数会导致视觉特征和文本特征难以对齐,为此BLIP-2提出两阶段预训练 Q-Former 来弥补模态差距:表示学习阶段和生成学习阶段,Q-Former的整体结构如下图所示

(1)表示学习阶段
在表示学习阶段,将 Q-Former 连接到冻结的 Image Encoder,训练集为图像-文本对,通过联合优化三个预训练目标,在Query和Text之间分别采用不同的注意力掩码策略,从而控制Image Transformer和Text Transformer的交互方式
- ITC(Image-Text Contrastive Learning):ITC的优化目标是对齐图像嵌入和文本嵌入,将来自Image Transformer输出的Query嵌入与来自Text Transformer输出的文本嵌入对齐,为了避免信息泄漏,ITC采用了单模态自注意掩码,不允许Query和Text相互注意。具体来说,Text Transformer的文本嵌入是 [CLS] 标记的输出嵌入,而Query嵌入则包含多个输出嵌入,因此首先计算每个Query输嵌入与文本嵌入之间的相似度,然后选择最高的一个作为图像-文本相似度;注意该任务中Q-Former两部分输入分别为query和文本
- ITG(Image-grounded Text Generation):ITG 是在给定输入图像作为条件的情况下,训练 Q-Former 生成文本,迫使Query提取包含文本信息的视觉特征。由于 Q-Former 的架构不允许冻结的图像编码器和文本标记之间的直接交互,因此生成文本所需的信息必须首先由Query提取,然后通过自注意力层传递给文本标记。ITG采用多模态Causal Attention掩码来控制Query和Text的交互,Query可以相互关注,但不能关注Text标记,每个Text标记都可以处理所有Query及其前面的Text标记。这里将 [CLS] 标记替换为新的 [DEC] 标记,作为第一个文本标记来指示解码任务
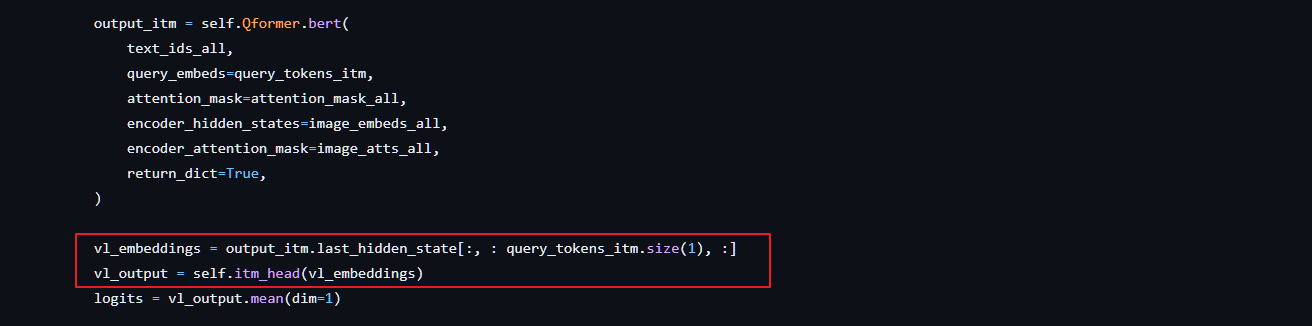
- ITM( Image-Text Matching):ITM是一个二元分类任务,通过预测图像-文本对是正匹配还是负匹配,学习图像和文本表示之间的细粒度对齐。这里将Image Transformer输出的每个Query嵌入输入到一个二类线性分类器中以获得对应的logit,然后将所有的logit平均,再计算匹配分数。ITM使用双向自注意掩码,所有Query和Text都可以相互关注。(注意:使用Qformer左边部分结构,输入是query和文本embedding concat到一起,然后再通过self-attention及后续操作,在分类头之前只取query部分的向量在进行分类)
关于代码上实现的一些细节:
- 输入embedding:Qformer.py line95

- ITM分类任务: blip2_qformer.py line239
(2)生成学习阶段
在生成预训练阶段,将 Q-Former连接到冻结的 LLM,以利用 LLM 的语言生成能力。这里使用全连接层将输出的Query嵌入线性投影到与 LLM 的文本嵌入相同的维度,然后将投影的Query嵌入添加到输入文本嵌入前面。由于 Q-Former 已经过预训练,可以提取包含语言信息的视觉表示,因此它可以有效地充当信息瓶颈,将最有用的信息提供给 LLM,同时删除不相关的视觉信息,减轻了 LLM 学习视觉语言对齐的负担
BLIP-2试验了两种类型的 LLM:基于解码器的 LLM 和基于编码器-解码器的 LLM,如下图所示
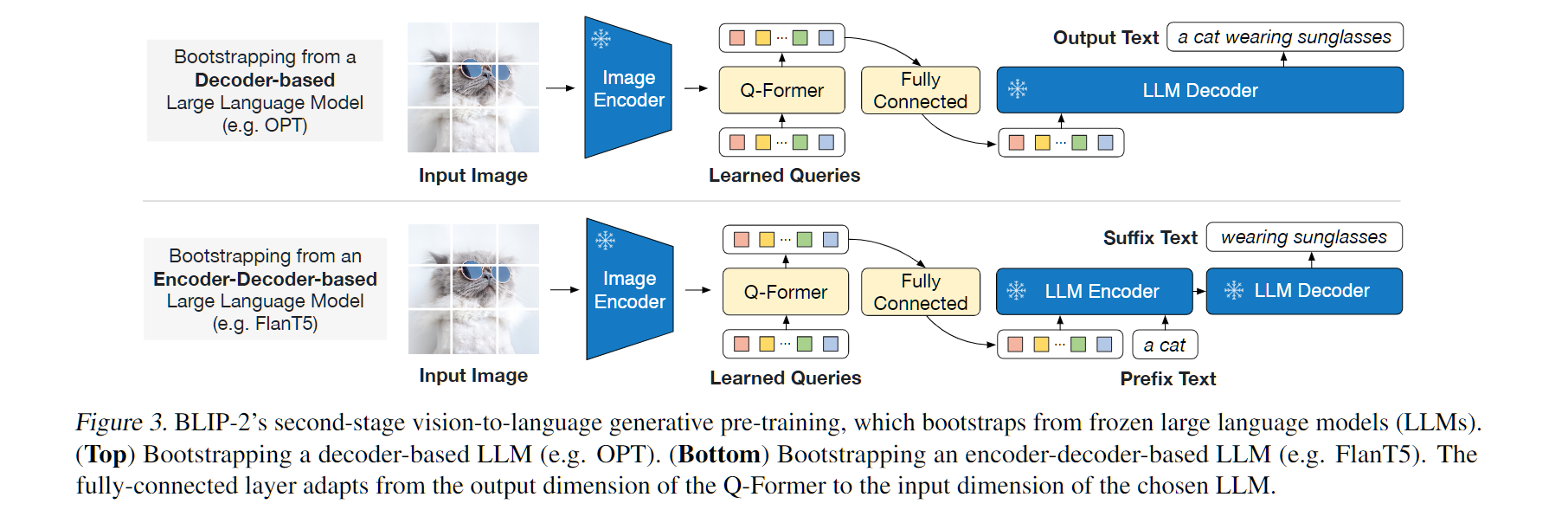
- 对于基于decode only LLM,使用语言建模损失进行预训练,其中冻结的 LLM 的任务是根据 Q-Former 的视觉表示生成文本
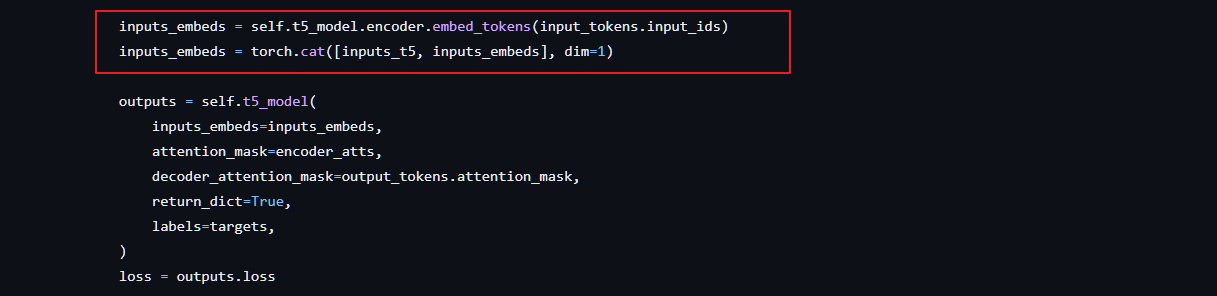
- 对于基于encoder-decoder LLM,使用前缀语言建模损失进行预训练,将文本分成两部分,前缀文本(instruction)与视觉表示连接起来作为 LLM 编码器的输入,后缀文本(caption)用作 LLM 解码器的生成目标 blip2_t5.py line145
3. 参考
一文读懂BLIP和BLIP-2多模态预训练
blip2 代码