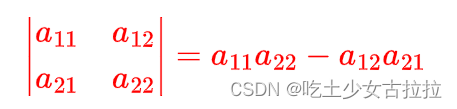首页
编程日记
开发工具
嵌入式
服务器
运维
通往大厂之路:Solr面试题及参考答案100道题
embedded
/
2024/10/10 13:22:22
/
目录
什么是Solr,它主要用来做什么?
解释Solr和Lucene的关系。
Solr有哪些主要特点?
http://www.ppmy.cn/embedded/5532.html
相关文章
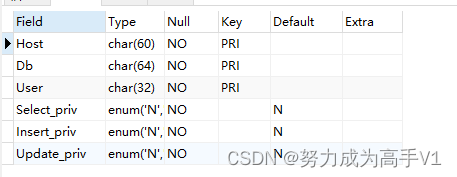
MySQL数据库第二天
如何授权和撤销 已经给客户授权: GRANT all on *.* to "用户名""获取IP地址" identified by "密码" 如果想撤销可以使用: revoke all on 数据库.表 form "用户名""获取的IP地址" 补充࿱…
阅读更多...
Spark面试整理-Spark集成Hive
Apache Spark与Apache Hive的集成使得Spark能够直接对存储在Hive中的数据进行读取、处理和分析。这种集成利用了Spark的高性能计算能力和Hive的数据仓库功能。以下是Spark集成Hive的关键方面: 1. 启用Hive支持 要在Spark中使用Hive,需要确保Spark编译时包含了对Hive的支持。在…
阅读更多...
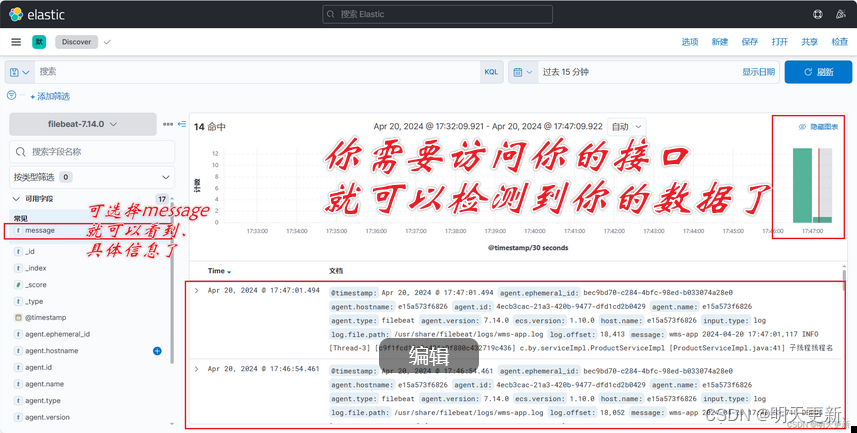
EFK安装与使用!!!
一、将你的项目进行打包。 二、上传到docker, 启动项目 三、修改前端的代理路径 四、EFK相关配置 1、docker-compose.yml: version: 3 services:kibana:image: kibana:7.14.0ports:- "5601:5601"environment:- ELASTICSEARCH_HOSTShttp://19…
阅读更多...
使用new 关键字调用函数,创建对象的过程中做了什么
使用new 关键字调用函数,创建对象的过程中做了什么 使用 new关键字创建对象的过程大致可以分为以下几个步骤: 创建空对象:首先,new操作符会创建一个空对象,这个对象的隐式原型__proto__属性会被设置为构造函数的显示原…
阅读更多...
线性代数基础3 行列式
行列式 行列式其实在机器学习中用的并不多,一个矩阵必须是方阵,才能计算它的行列式 行列式是把矩阵变成一个标量 import numpy as np A np.array([[1,3],[2,5]]) display(A) print(矩阵A的行列式是:\n,np.linalg.det(A))array([[1, 3],[2, …
阅读更多...
椋鸟数据结构笔记#10:排序·中
文章目录 四、归并排序时间复杂度实现递归实现非递归实现 测试稳定性 五、非比较排序5.1 计数排序时间复杂度实现测试局限性 5.2 桶排序时间复杂度实现测试 5.3 基数排序时间复杂度实现测试局限性 萌新的学习笔记,写错了恳请斧正。 四、归并排序 归并排序是一种非常…
阅读更多...
在QT中使用QTableView与数据库连接
一、界面与数据库连接,使用QSqlTableModel对数据处理 //界面初始化 void TestProSetWid::initsqlmodel() {// 连接SQLite数据库db QSqlDatabase::addDatabase("QSQLITE","second");db.setDatabaseName("./testitem.db"); // 替换为…
阅读更多...
亚远景科技-如何看待汽车软件开发中的质量管理与传统质量管理的异同?结合ASPICE标准谈谈
汽车软件开发中的质量管理与传统质量管理在某些方面存在异同,而ASPICE(Automotive SPICE)标准为汽车行业提供了一套针对软件开发过程的专门质量管理框架。下面是对比分析以及ASPICE标准在此背景下的作用: 异同点: 1. 复…
阅读更多...
最新文章
YouTube音视频合并批处理基于 FFmpeg的
Golang | Leetcode Golang题解之第467题环绕字符串中唯一的子字符串
《大道平渊》· 廿贰 —— 杀心篇:独立人格的形成
SKG未来健康校招社招入职测评:综合能力及性格问卷SHL测评题库
自然语言处理-语言转换
微信小程序15天